
들어가며
- 번역한 페이퍼 원문: Graves, Alex. “Sequence transduction with recurrent neural networks.” arXiv preprint arXiv:1211.3711 (2012).
- 본 포스트에서는
transduction은 번역하지 않고 원문 그대로,transformation은 ‘변형’으로 번역하였습니다. - Graves의 이 2012년 논문은 이후 수많은 연구에 영향을 준 유명한 논문이지만 수식이 많고 그림은 적어 읽기가 쉽지 않습니다. 이것을 먼저 읽으면 이해가 잘 가지 않을 수 있으니 2015년 Google Brain에서 나온 A neural transducer1를 먼저 읽으시는 걸 추천드립니다. 2015년 논문은 조금 더 설명이 친절하게 되어 있습니다.(무엇보다도 일단 그림이 좀더 많습니다..ㅎㅎ)
이전 시리즈
Absract
- 많은 기계 학습 task들은 입력 시퀀스에서 출력 시퀀스로의 ‘transformation’ 또는 ‘transduction‘으로 표현 될 수 있음
- 음성인식, 기계 번역, 단백질 2차 구조 예측, TTS 등
- 시퀀스 transduction의 핵심 과제 중 하나는 수축(shrinking), 늘어남(stretching), 번역(translation)과 같은 순차적 왜곡에 강건하게 입력&출력 시퀀스 모두를 표현하는 방법을 배우는 것
- RNN(Recurrent Neural Network)은 그러한 표현 형식(representation)을 학습해낼 수 있는 강력한 시퀀스 학습 아키텍처
- 그러나 RNN은 본래 transduction을 수행하기 위하여 입력-출력 시퀀스 간에 미리 정의된 정렬(alignment)을 필요로 함
- 바로 이러한 입출력 간의 정렬을 찾는 것 자체가 많은 시퀀스 transduction 문제의 가장 어려운 부분이기 때문에 이것은 심각한 한계점
- 실제로 많은 경우에는 출력 시퀀스의 길이를 결정하는 것조차도 어려움
- 이 논문은 온전히 RNN을 기반으로 하는 end-to-end 확률론적 시퀀스 transduction 시스템을 제안
- 이 시스템은 이론상으로 모든 입력 시퀀스를 유한(finite)하고 이산적인(discrete) 출력 시퀀스로 변형(transform)할 수 있음
- 음소 인식(phoneme recognition)을 위한 실험은 TIMIT 음성 코퍼스를 이용
1. Introduction
- 시퀀스를 변형하고 다루는 능력은 인간 지능의 결정적인 부분. 우리가 세상에 대해 알고 있는 모든 것은 감각 시퀀스의 형태로 우리에게 도달하고, 우리가 세상과 상호작용하기 위해 하는 모든 일은 일련의 행동과 생각들의 시퀀스를 필요로 하기 때문
- 그러므로 자동 시퀀스 트랜스듀서(transducer)의 생성은 인공지능으로 가기 위한 중요한 단계라 할 수 있음
- 이러한 시스템이 직면한 핵심적인 문제는 순차적인(sequential) 왜곡 현상에 대해 어떻게 불변, 또는 최소한 강건한 방식으로 시퀀스의 정보를 표현할 것인가 하는 점. 또한 이 견고성은 입력-출력 시퀀스 모두에 적용되어야 함
- 예를 들어 오디오 신호를 일련의 단어로 변형하려면 다른 목소리들, 계속 변하는 이야기 속도, 배경의 잡음 등으로 인한 명백한 왜곡에도 불구하고 말소리(예를 들어 음소 또는 음절)를 식별할 수 있는 능력이 필요
- 언어 모델이 출력 시퀀스에 대한 사전(prior) 지식을 참고하는 데 사용되는 경우, 단어 누락, 잘못된 발음, 비 어휘적 발화 등에도 견고해야 함
- Recurrent Neural Network(RNNs)는 범용 시퀀스 transduction을 위한 촉망받는 아키텍처
- 고차원의 다변량 내부 state와 비선형 state-to-state 동역학의 조합은 hidden Markov 모델과 같은 기존의 연속성을 갖는 알고리즘보다 더 큰 표현력을 보여줌
- 특히 RNN은 오랜 기간 동안 정보를 저장하고 접근하는 데 더 뛰어난 성능을 보임1
- RNN의 초기 시기에는 학습의 어려움에 시달렸지만(Hochreiter et al., 2001), 최근의 결과는 필기 인식(Graves et al., 2008; Graves & Schmidhuber, 2008), 텍스트 생성(Sutskever et al., 2011), 언어 모델링(Mlov etling) .., 2010) 등에서 최고 수준의 성능을 기록
- 또한 이러한 결과는 긴 문자열 뒤에 괄호를 닫거나(Sutskever et al., 2011) 펜으로 쓴 글자 궤적에서 손글씨 문자를 식별하기 위해 지연된 스트로크를 사용하는 것과 같은 작업을 수행하기 위해 원거리에 걸친 메모리를 사용하는 것을 보여줌 (Graves et al., 2008).
- 그러나 RNN은 일반적으로 입력과 출력 시퀀스 간의 정렬이 미리 알려진 문제로 제한됨
- 예를 들어, RNN은 음성 신호의 모든 프레임 또는 단백질 사슬의 모든 아미노산을 분류하는 데 사용
- 네트워크 출력이 확률적이면 입력 시퀀스와 동일한 길이의 출력 시퀀스에 대한 분포가 발생
- 그러나 출력 길이가 미리 알려지지 않은 범용 시퀀스 트랜스듀서의 경우, 우리는 모든 길이의 시퀀스보다 분포를 아는 것을 선호함
- 또한 입력 및 출력을 정렬하는 방법이 없기 때문에 이 분포는 이상적으로 가능한 모든 정렬을 포함
역주: 이 부분이 본 연구의 핵심적인 아이디어라고 생각함. 이전의 연구에서는 타깃(출력) 시퀀스의 가능한 모든 시퀀스를 예측하면서 가장 조건부확률을 높이는 방향으로 출력이 결정되는데, 본 연구에서는 이러한 모든 길이의 시퀀스를 일일이 만들기보다는 출력에 대한 분포를 생성하는 방식으로 방향을 바꾼 것
- Connectionist Temporal Classification (CTC)은 입력 시퀀스보다 길지 않은 모든 출력 시퀀스를 가진 모든 선형에 대한 분포를 정의하는 RNN 출력 계층 (Graves et al., 2006)
- 그러나 출력 시퀀스가 입력 시퀀스보다 긴 텍스트-음성과 같은 작업을 배제할 뿐만 아니라 CTC는 출력 간의 상호 의존성을 모델링하지 않음
- 본 논문에 설명된 트랜스듀서는 모든 길이의 출력 시퀀스에 대한 분포를 정의하고 입출력 및 출력-출력 종속성을 공동으로 모델링하여 CTC를 확장
- 차별적인 sequential 모델로서, 트랜스듀서는 ‘체인 그래프(chain-graph)’ CRFs(Conditional Random Fields) (Lafferty et al., 2001)와 유사
- 그러나 raw 데이터 및 잠재적으로 제한되지 않은 범위의 종속성에서 학습 자질을 추출할 수 있는 RNN의 트랜스듀서 구성은 일반적으로 CRF에 사용되는 쌍 출력 전위 및 사람이 직접 제작한 입력 자질과 현저한 대조
- 본 연구와 정신적으로 좀더 가까운 것은 ‘그래프 트랜스포머 네트워크(Graph Transformer Network)’(Bottou et al., 1997) 패러다임
- 이 패러다임에서는 차별화 가능한 모듈(종종 신경망)이 탐지, 세분화, 인식과 같은 연속적인 그래프 변환을 수행하도록 글로벌하게 훈련될 수 있음
- 섹션 2는 RNN 트랜스듀서를 정의하여 테스트 데이터에 어떻게 훈련되고 적용될 수 있는지를 보여주며, 섹션 3은 TIMIT 음성 코퍼스에 대한 실험 결과를 제시하고 향후 task에 대한 최종 언급 및 방향성은 섹션 4에 기술
2. Recurrent Neural Network Transducer
- : 어떠한 입력 공간 에 대한 모든 시퀀스의 집합 에 속하는 임의의 길이 짜리의 입력 시퀀스
- : 어떠한 출력 공간 에 대한 모든 시퀀스의 집합 에 속하는 길이 짜리 출력 시퀀스
- 입력 벡터 와 출력 벡터 는 모두 고정 길이의 실수 값 벡터로 표시
- 예를 들어 task가 phonetic 음성인식인 경우 각 는 일반적으로 MFC 계수의 벡터가 되며 각 는 특정 음소를 인코딩하는 1-hot vector
- 이 논문에서는 출력 공간이 이산적(discrete)이라고 가정
- 그러나 이 방법은 에 대해 다루기 쉽고 차별화 가능한 모델을 찾을 수 있는 연속(continuous) 출력 공간으로는 쉽게 확장 될 수 있음
- 확장(extended) 출력 공간 를 로 정의
- 은 ‘null’ 출력
- 의 직관적인 의미는 ‘출력 없음’
역주: 확장 출력 공간에서 null 출력을 제거한 것이 출력 공간
- 따라서 시퀀스 는 와 동일
역주: 위에서 는 모든 의 집합이므로 그 원소가 이미 벡터임(). 그래서 부분집합이 아니라 원소를 뜻하는 기호를 사용한 것
- 를 alignment로 놓음
- null 기호의 위치가 입력과 출력 시퀀스 사이의 정렬(alignment)을 결정하기 때문
역주: alignment ‘a’도 의 원소인 ‘벡터’임
- null 기호의 위치가 입력과 출력 시퀀스 사이의 정렬(alignment)을 결정하기 때문
- 를 alignment로 놓음
- 주어진 에 대해 RNN 트랜스듀서는 조건부 분포 을 정의
- 이 분포는 에 대한 다음 분포로 재 정리됨
- 여기서 는 의 alignment에서 null 기호를 제거하는 함수
- 을 결정하기 위해 두개의 RNN이 사용
- Transcript network : 입력 시퀀스 를 스캔하고 transcription 벡터인 시퀀스를 출력
- Prediction network : 출력 시퀀스 를 스캔하고 예측 벡터 시퀀스 를 출력
역주: 여기서 는 입력 시퀀스의 길이, 는 타깃인 출력 시퀀스의 길이
그리고 최종 예측 결과물이 Y가 아니라 G임
2.1. Prediction Network
- 예측 네트워크 는 입력층, 출력층 그리고 단일 hidden layer으로 구성된 RNN
- 길이 입력 시퀀스 에서 로 변환
- 에는 이 더해진 상태
- 입력은 1-hot 벡터로 인코딩되는데, 즉 가 개의 레이블로 구성되고 라면 는 길이 벡터이며, 그 요소는 1인 번째 것을 제외하고는 모두 0
- 은 길이 인 0벡터로 인코딩. 따라서 입력층의 크기는
-
출력층은 크기 (의 각 요소에 대해 하나의 단위)이므로 예측 벡터 는 크기
- 주어진 는 에서 까지의 다음 방정식을 반복함으로써 hidden 벡터 시퀀스 와 예측 시퀀스 를 계산:
- 여기서 는 input-hidden 가중치 행렬, 는 hidden-hidden 가중치 행렬
- 숨겨진 출력 가중 행렬인 와 는 바이어스 항, 는 숨겨진 레이어 함수
- 전통적인 RNN에서 는 탄젠트(tahn) 또는 로지스틱 시그모이드(logistic sigmoid) 의 엘리먼트 단위 적용
- 그러나 저자들은 Long Short-Term Memory (LSTM) 아키텍처 (Hochreiter & Schmidhuber, 1997; Gers, 2001)가 원거리 문맥 정보를 찾고 이를 이용하는 데 더 좋은 성능을 보인다는 것을 발견
- 본 연구에 사용된 LSTM 버전인 는 다음 복합 함수로 구현:
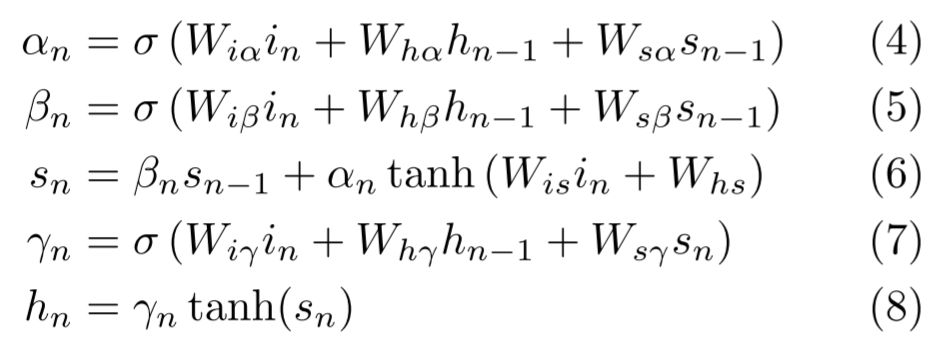
- 여기서 는 각각 input gate, forget gate, output gate, state 벡터. 모두 은닉 벡터인 와 동일한 사이즈
- 가중치 행렬의 첨자(작은 글자)는 예를 들어 는 hidden-input gate 행렬이고 는 input-output gate 행렬
- state에서 게이트 벡터까지의 가중치 행렬은 대각선 형태이므로 각 게이트 벡터의 요소(element)인 은 state 벡터의 요소 위치에서만 입력을 받음
-
바이어스 항 (에 더해지는)은 수식의 깔끔함을 위해 생략
- 예측 네트워크는 이전 요소가 주어진, 의 각 요소를 모델링하려고 시도
- 따라서 이는 표준의 next-step-prediction RNN_과 유사합니다만 이 때 _null prediction을 할 수 있어야 함
2.2. Transcription Network
- transcription 네트워크 는 양방향(bidirectional) RNN(Schuster & Paliwal, 1997)으로 입력 시퀀스 를 두 개의 각기 다른 hidden 레이어로 앞뒤로(forward and backward) 스캔하며 이들을 단일 출력 레이어로 전달
- 일반 RNN의 경우 바로 직전의 input들만 고려되는 데 반해 양방향 RNN은 각각의 출력 벡터들이 전체 입력 시퀀스에 의존하기 때문에 좀더 선호됨
-
그러나 본 연구에서는 이것이 성능에 어느 정도 영향을 미치는지까지는 테스트하지 않았음
-
주어진 길이 의 입력 시퀀스 에서 양방향 RNN은 역방향 레이어에 대한 첫번째 iteration을 거치면서( to 1) 전방향(forward) 은닉 시퀀스인 와 역방향(backward) 은닉 시퀀스 , 그리고 transcription 시퀀스 를 계산
- 양방향 LSTM 네트워크(Graves & Schmidhuber, 2005)를 위해, 는 에 의해 구현
- 출력 레이블이 있는 task의 경우, 전사 네트워크의 출력 레이어는 예측 네트워크와 마찬가지로 크기 이며, 따라서 전사 벡터 는 크기
- 전사 네트워크는 CTC RNN과 유사
- null 출력을 사용하여 입출력 정렬에 대한 분포를 정의
2.3. Output Distribution
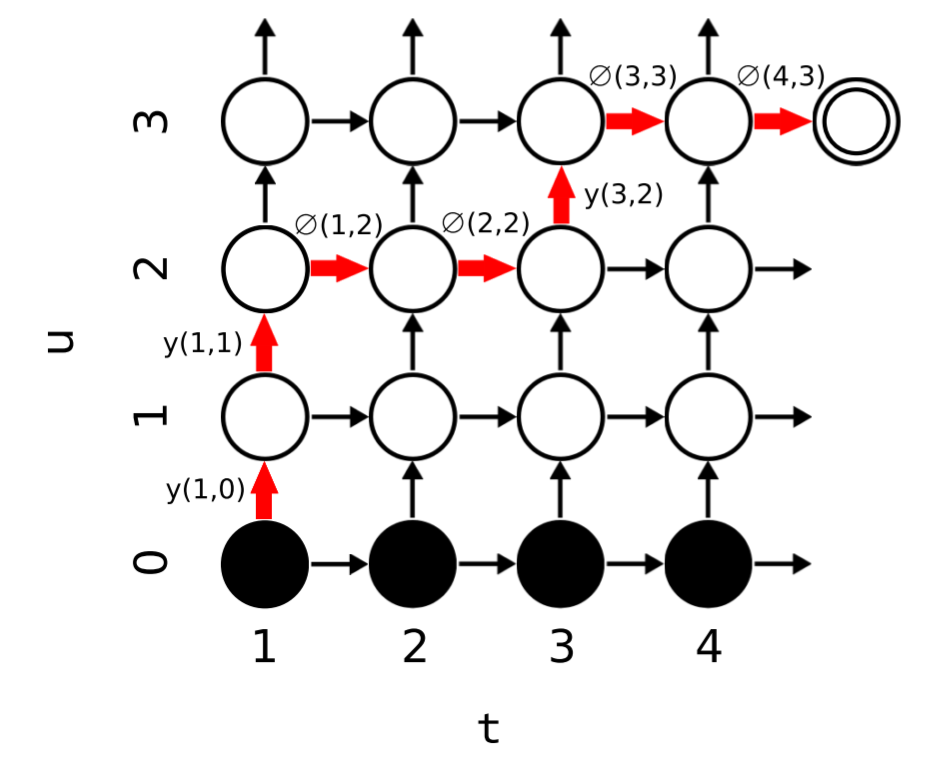
- 그림 1. 로 정의 된 출력 확률 격자 그래프. 의 노드는 transcription 시퀀스에서 점 에 의한 출력 시퀀스의 첫 번째 요소를 출력할 확률
- 노드 를 떠나는 수평 방향의 화살표는 에서 아무것도 출력하지 않는 확률
- 반면, 수직 방향의 화살표는 요소 을 출력할 확률
- 하단의 검은색 노드는 출력이 방출되기 전에 null 상태
- 왼쪽 하단에서 시작하여 오른쪽 상단의 종료 노드에 도달하는 경로는 입력과 출력 시퀀스 간의 가능한 정렬에 해당
- 각 정렬은 확률 1로 시작하고 최종 확률은 통과하는 화살표의 전이 확률의 곱 (빨간색 경로에 대해 표시).
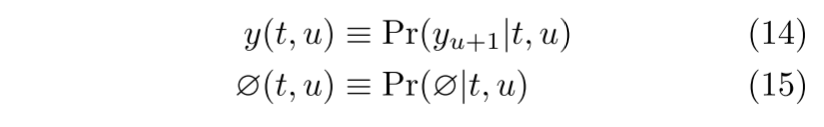
- 은 위 그림 1에 표시된 격자의 전이 확률을 결정하는 데 사용
- 왼쪽 하단에서 오른쪽 상단의 종료 노드까지 가능한 경로 집합은 와 사이의 완전한 정렬 집합에 해당
- 집합 에 대해. 따라서 가능한 모든 입출력 정렬에는 확률이 지정되며, 그 합은 입력 시퀀스가 주어진 출력 시퀀스의 총 확률
- 그 어떤 유한한 에 대해서도 유사한 격자를 그릴 수 있기 때문에, 은 단일 입력 시퀀스가 주어지면 모든 가능한 출력 시퀀스에 대한 분포를 정의 가능
2.5. Training
- 입력 시퀀스 x와 대상 시퀀스 y가 주어지면 모델을 훈련시키는 자연스러운 방법은 대상 시퀀스의 로그 손실 을 최소화하는 것
- 우리는 네트워크 가중치 매개 변수와 그라디언트 하강을 수행하여 L의 그라디언트를 계산하여 이를 수행
-
출력 격자를 통한 확률의 확산을 분석하면 Pr (yx)이 노드를 통해 왼쪽에서 오른쪽 대각선으로의 모든 상단에서 오른쪽 대각선에 대한 (t, u) (t, u)의 합과 동일하다는 것을 알 수 있음. 즉, n : 1 n n U + T
-
네트워크 가중치에 대한 그라디언트는 각 네트워크에 독립적으로 Backpropagation Through Time (Williams & Zipser, 1995)을 적용하여 계산 가능
- forward-backward 알고리즘에 필요한 모든 에 대해 별도의 소프트 맥스를 계산할 수 있음
- 그러나 이것은 지수 함수의 높은 비용으로 인해 계산 리소스가 많이 필요
- exp (a + b) = exp (a) exp (b)를 상기하면, 우리는 모든 exp (f (t, x) 및 exp (g (1 : u) 항을 미리 계산하고 그 제품을 사용하여 Pr (kt, u). 이것은 각 길이 T 전사 시퀀스 및 훈련에 사용되는 길이 U 표적 시퀀스에 대해 O (TU)에서 O (T + U)로 지수 평가의 수를 줄임
2.6. Testing
- 트랜스듀서가 테스트 데이터에서 평가 될 때 입력 시퀀스에 의해 유도된 출력 시퀀스 분포의 모드(mode; 가장 많이 나타난 값)2를 찾음
- 불행히도 여기서 모드를 찾는 것은 단일 시퀀스의 확률을 결정하는 것보다 훨씬 어려움
- 어려움은 예측 함수 (따라서 출력 분포 )가 모델에 의해 내보내진 모든 이전 출력에 의존할 수 있다는 것
- 본 연구에서 사용한 방법은 출력 시퀀스 트리를 통한 고정폭 빔 검색(fixed-width beam search)
- 빔 검색의 장점은 임의의 긴 시퀀스로 확장이 가능하고 검색 정확도와 계산 비용을 trade-off할 수 있다는 점
- 을 지금까지 검색에서 발견 된 일부 출력 시퀀스 y를 방출할 확률, 을 transcription 단계 t 동안 만큼 를 확장할 확률로 놓음
-
를 의 적절한 prefix 집합으로 놓음(null 시퀀스 포함)
- 이 알고리즘은 단일 최상의 요소 대신 B에서 N 최상의 요소의 정렬 된 목록을 반환하여 N 최상의 검색 (N w)으로 간단히 확장 가능
- 최종 라인의 길이 정규화는 좋은 성능을 위해 중요한 것으로 보임. 그렇지 않으면 짧은 출력 시퀀스가 더 긴 출력 시퀀스보다 과도하게 선호되기 때문
-
이와 유사한 기술은 음성 및 필기 인식에서 숨겨진 마르코프 모델에 사용됨 (Bertolami et al., 2006).
- Eq (2)에서 예측 네트워크 출력이 현재가 주어진 이전 숨겨진 벡터와 독립적이라는 것을 관찰하면 모든 y에 숨겨진 벡터를 저장하고 Eq를 실행하여 빔 검색 중에 고려된 각 출력 시퀀스 y + k에 대한 예측 벡터를 반복적으로 계산할 수 있음
- (2) 입력으로 k를 사용하여 한 단계를 위해. 예측 벡터는 전사 벡터와 확률을 계산 가능
- 이 절차는 메모리 사용 증가를 희생시키면서 빔 검색을 크게 가속화. LSTM 네트워크의 경우 숨겨진 벡터 h와 상태 벡터 s를 모두 저장해야 함
3.4. Analysis
- 차별화 가능한 시스템의 한 가지 장점은 각 구성 요소의 다른 모든 구성 요소에 대한 민감도를 쉽게 계산할 수 있다는 것
- 이를 통해 입력 시퀀스와 이전 출력의 두 가지 정보 소스에 대한 출력 확률 lattice의 의존성을 분석할 수 있음
- 원시 스펙트로그램 이미지 Fig. 3이 음소로의 중간 변환이 없는 문자 시퀀스로 직접 전사되는 ‘end-to-end’ 음성인식에 적용된 RNN 트랜스듀서에 대한 이러한 관계를 시각화합니다.




댓글남기기