
NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE
ABSTRACT
- 신경망 기반 기계번역은(이하 NMT; Neural Machine Translation) 최근 제안된 접근 방식. 전통적인 통계 기반 기계번역(SMT; Statistical Machine Translation)과 달리 NMT는 번역 성능을 극대화하기 위해 결합적으로(jointly) 튜닝할 수 있는 단일 신경 네트워크를 구축하는 것을 목표로 함
- NMT를 위해 최근에 제안된 모델은 주로 인코더-디코더(encoder-decoder) 계열에 속하며, 원래의 문장을 인코딩하여 디코더가 번역을 생성하는 데 입력값으로 사용하는 고정 길이 벡터로 변환함
- 이 논문에서 저자들은 길이가 고정된 벡터의 사용이 이 기본적인 형태의 인코더-디코더 구조의 성능을 향상시키는 데 병목 현상이라고 추측
- 모델이 자동으로 원 문장 내에서 번역하고자 하는 타깃 단어와 관련된 부분을 명시적인 segment로 정의하지 않고 (soft-)search할 수 있도록 허용하여 모델 구조를 확장할 것을 제안
- 새로운 접근법을 통해 영어-프랑스어 번역 작업에 대한 기존의 최고 성능의 구문 기반 시스템과 비슷한 번역 성능을 달성. 또한 질적 분석 결과, 모델에서 발견되는 (soft-)alignment가 일반적인 직관과 잘 일치함을 발견
Introduction
- NMT는 최근 Kalchbrenner and Blunsom (2013), Sutskever 등이 제안한, 기계번역 분야에서 새로 부상하는 접근 방식. 개별적으로 튜닝된 많은 작은 하위 구성 요소로 구성된 전통적인 구문 기반 번역 시스템과 달리 NMT는 문장을 읽고 번역을 출력하는 단일의 큰 신경망을 구축하고 훈련
- 기존에 제안된 NMT 모델의 대부분은 인코더와 각 언어에 대한 디코더가 있는 인코더-디코더 계열(Sutskever et al., 2014, Cho et al., 2014a)에 속하거나 출력이 비교되는 각 문장에 적용되는 언어 별 인코더를 포함하고 있음 (Hermann and Blunsom, 2014)
- 인코더 신경망은 원 문장을 고정 길이 벡터로 읽고 인코딩하고, 디코더는 인코딩 된 벡터에서 변환을 출력
- 인코더와 언어 쌍의 디코더로 구성된 전체 인코더-디코더 시스템은 원 문장이 주어지면 올바른 번역의 확률을 최대화하도록 공동으로 학습
- 이 인코더-디코더 접근법의 잠재적인 문제는 신경망이 원 문장의 모든 필요한 정보를 고정 길이 벡터로 압축할 수 있어야 한다는 것. 이것은 신경망이 긴 문장, 특히 학습 코퍼스의 문장보다 긴 문장에 대처하는 것을 어렵게 만들 수 있음. Cho et al. (2014b)는 실제로 입력 문장의 길이가 증가함에 따라 기본 형태 인코더-디코더의 성능이 급격히 저하된다는 것을 증명
- 이 문제를 해결하기 위해 저자들은 결합적으로(jointly) align하고 번역하는 법을 학습하는 인코더-디코더 모델에 대한 확장을 제안
- 제안된 모델이 번역문에서 단어를 생성 할 때마다 가장 관련성이 높은 정보가 집중되어 있는 원 문장의 일련의 위치를 soft-search함. 그런 다음 모델은 이러한 원본의 위치와 관련된 컨텍스트 벡터와 이전에 생성된 모든 대상 단어를 기반으로 대상 단어를 예측
- 이 접근법의 기본 인코더-디코더와 가장 중요한 특징은 전체 입력 문장을 단일 고정 길이 벡터로 인코딩하려고 시도하지 않는다는 것. 그 대신, 입력 문장을 벡터 시퀀스로 인코딩하고 변환을 디코딩하는 동안 이러한 벡터의 하위 집합을 적응적으로 선택
- 이것은 NMT 모델이 길이에 관계없이 원 문장의 모든 정보를 고정 길이 벡터로 압축해야하는 것을 자유롭게 하는 효과. 저자들은 이를 통해 모델이 긴 문장에 더 잘 대처할 수 있음을 보여주었다고 함
- 정렬 및 번역을 결합적으로 학습하는, 제안된 접근법이 기본 인코더-디코더 접근법에 비해 번역 성능이 크게 향상. 더 긴 문장에서 이러한 개선 효과가 더 분명하지만 어느 정도 길이가 있는 문장에서는 관찰할 수 있음
- 영어-프랑스어 번역 task에서 제안된 접근법은 단일 모델, 번역 성능을 기존 구문 기반 시스템에 필적하거나 근접하게 달성. 또한 질적 분석 결과에서 제안된 모델이 원 문장과 관련 있는 타깃 문장 사이에 언어적으로 그럴듯한 (soft-) alignment를 발견
2. Background: Neural Machine Translation
- 확률론적 관점에서 번역은 원 문장 가 주어진 상태에서 표적 문장 의 조건부 확률을 최대화하는 를 찾는 것, 즉
- NMT에서 우리는 평행의 학습 코퍼스를 사용하여 문장 쌍의 조건부 확률을 최대화하기 위해 매개 변수화된 모델에 fitting. 조건부 분포가 번역 모델에 의해 학습되면 원 문장이 주어졌을 때 조건부 확률을 최대화하는 문장을 검색하여 해당 번역을 생성할 수 있음
- 최근 많은 논문에서 이 조건부 분포를 직접 학습시키기 위해 신경망의 사용을 제안(예 : Kalchbrenner and Blunsom, 2013; Cho et al., 2014a; Sutskever et al., 2014b; Cho et al., 2014b; Forcada and Neco, 1997)
- 이 NMT 접근법은 일반적으로 두 가지 구성 요소로 구성
- encoding: 원본 문장 를 인코딩
- decoding: 대상 문장 로 디코딩
- 예를 들어 Cho et al.(2014a)과 Sutskever et al.(2014)은 두 개의 RNN을 사용하여 가변 길이 소스 문장을 고정 길이 벡터로 인코딩하고 벡터를 가변 길이의 대상 문장으로 디코딩
- NMT는 꽤 최근에 나온 새로운 접근법임에도 불구하고 이미 유망한 결과를 보여준 바 있음
- Sutskever et al.(2014)에 따르면, LSTM을 기반으로 한 NMT는 영어-프랑스어 번역 task에서 기존의 구문 기반 기계번역 시스템의 최첨단 성능에 가까웠음
- 실제 예로는, 기존 번역 시스템에 신경망의 요소를 추가하여 구문 표(phrase table) 안의 구문 쌍(영어, 프랑스어)에 스코어링을 한다던가(Cho et al., 2014a) 또는 후보 번역문들을 다시 랭킹(rerank)을 매길 때(Sutskever et al., 2014) 이전의 최첨단 성능 수준을 능가하기도 함
2.1 RNN Encoder-decoder
- 이 단락에서 저자들은 결합적으로(jointly) align하고 번역하는 법을 학습하는 새로운 구조를 만들어낸 근간이 되는 Cho et al.(2014a)과 Sutskever et al.(2014)이 제안한 RNN Encoder-Decoder라는 기본 프레임워크를 간략하게 설명
-
인코더-디코더 구조에서 인코더는 입력 문장, 즉 벡터 시퀀스 를 벡터 의 형태로 읽어 냄. 가장 일반적인 접근법은 아래와 같은 형태의 RNN을 사용하는 것
역주: t번째 단어의 representation과 t-1번째 단어의 hidden state을 어떠한 비선형 함수 f에 입력으로 넣어 t번째의 hidden state을 계산
- 이 때 은 시간 에서의 hidden state, 는 hidden state의 시퀀스에서 생성된 (컨텍스트)벡터
- 와 는 어떠한 비선형 함수
- Sutskever et al. (2014)는 LSTM을 와 로 사용
-
디코더는 주로 다음 단어 를 예측하기 위해 주어진 context 벡터 와 이전의 모든 예측된 단어들 을 이용하여 학습됨
-
즉 디코더는 일 때, 다음과 같은 조건 하에서 결합확률(joint probability)을 분해하여 번역 문장 에 대한 확률을 정의
역주: 어떠한 번역 문장 y의 확률 는 특정 time step에서의 예측된 단어 부터 까지와 컨텍스트 벡터 c일 때 일 확률들의 곱
-
RNN을 사용하면 각 조건부 확률이 아래와 같이 모델링됨
역주: 위에서 언급한 ‘특정 time step에서의 예측된 단어 부터 까지와 컨텍스트 벡터 c일 때 일 확률’은 아래 수식과 같이 multi-layer인 어떠한 비선형 함수에 바로 직전 단어(), 현재의 hidden state(), 컨텍스트 벡터 c를 입력 값으로 넣은 결과
- 여기서 는 의 확률을 출력하는 비선형의, 잠재적으로 다층인(multi-layered) 함수
- 는 RNN의 hidden state
- 여기서는 LSTM을 예로 들었지만 RNN & de-convolutional 신경망 하이브리드 같은 다른 아키텍처가 사용될 수도 있음(Kalchbrenner and Blunsom, 2013)
3. Learning to align and translate
- 이 섹션에서는 NMT를 위한 새로운 아키텍처를 소개
- 인코더(Sec. 3.2.)와 원본 문장에서의 검색을 emulating하는 디코더로서(Sec. 3.1)의 bidirectional RNN으로 구성
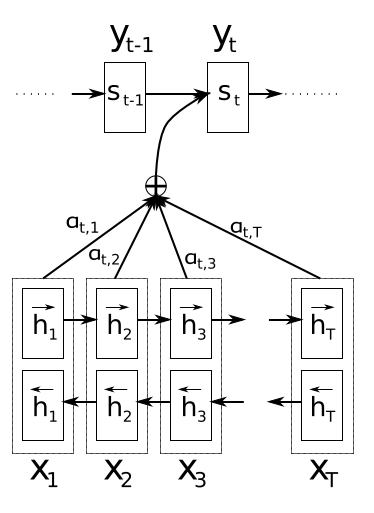
Figure 1. 제시된 모델에서 주어진 원본 문장 를 이용해 번째 타깃 단어 를 생성하는 모습을 표현한 그림
3.1 Decoder: general description
- 새로운 모델 아키텍처에서 저자들은 의 각 조건부 확률을 다음과 같이 정의
역주: 의 조건부 확률을 설명한 것이 이므로 그걸 보면 됨. 달라진 부분은 컨텍스트 벡터가 각 time step의 y값, 를 예측할 때마다 바뀐다는 점임. 디코더 설명이 먼저 나오는 이유는 기존의 encoder-decoder 모델에서 decoder 부분이 달라졌기 때문
- 여기서 는 아래 수식에 의해 계산된, 시간 에서의 hidden state
- 기존의 인코더-디코더 접근법과 달리( 참고), 여기서의 확률값은 각 타깃 단어 마다 존재하는 별개의 컨텍스트 벡터 에 기반하여 계산
- 컨텍스트 벡터 는 인코더가 입력 문장을 매핑한 결과인 일련의 sequence of annotation(주석의 시퀀스)인 에 따라 달라짐. 각 annotation 에는 전체 입력 시퀀스에 대한 정보가 포함되어 있는데, 여기서 특히 입력 시퀀스의 번째 단어 주변부에 포커싱
- annotation이 어떻게 계산되는지는 다음 절에서 자세히 설명
역주: 여기서 ‘annotation’이라는 용어가 생소할 수 있는데, 이것이 흔히 말하는 ‘attention’이라고 생각하면 됨
- annotation이 어떻게 계산되는지는 다음 절에서 자세히 설명
- 컨텍스트 벡터 는 이러한 의 가중치 합으로 계산
- 각 annotation 의 가중치 는 다음에 의해 계산되는데,
역주: 아래 수식 == softmax function. 를 0~1 사이로 만들어 줌
- 이 때 다음 수식은 위치 주변의 입력과 위치 의 출력이 얼마나 잘 매칭되는지 점수를 매기는 alignment model
-
이 점수는 RNN hidden state (를 방출하기 바로 직전 상태, 참고)와 입력 문장의 번째 annotation인 를 기반으로 함
역주: alignment model 는 하나 전의 위치의 hidden state()과 번째 annotation(전체 input sequence의 정보를 담고 있되 특히 번째 단어 주변부에 포커싱된)을 입력으로 받아 위치 주변의 입력과 현재 위치()의 출력이 어울리는(매칭되는) 정도를 점수 매기는 것.
현재 위치와 의 주변부가 매칭이 잘 되면 가중치()가 커지게 됨
- alignment 모델 를 본 연구의 제안 시스템의 다른 모든 구성 요소와 결합적으로(jointly) 학습된 FNN(Feedforward Neural Network)으로 매개 변수화
- 전통적인 기계번역과 달리 alignment는 잠재 변수(latent variable)로 간주되지 않음. 대신 alignment 모델은 soft-alignment를 직접 계산하여 비용 함수(cost function)의 변화도(gradient)를 역전파할 수 있음
- 이 변화도(gradient)는 전체 번역 모델과 alignment 모델을 함께 결합적으로 학습시키는 데 사용할 수 있음
- 모든 annotation의 가중치 합계를 expected annotation, 즉 가능한 alignment들에 대한 기대값을 계산하는 것으로 간주하는 접근법은 직관적으로 이해가 가능
- 를 타깃 단어 가 원본 단어 에 정렬되거나 번역될 확률이라고 가정. 이 때 번째 컨텍스트 벡터 는 확률 가 있는 모든 annotation에 대한 expected annotation
- 확률 또는 이와 관련된 에너지 는 다음 상태 를 결정하고 를 생성할 때 이전의 숨겨진 상태 에 대한 annotation 의 중요성을 반영
-
직관적으로 이것은 디코더에서 ‘attention’ 기제(mechanism)을 구현하는 것. 디코더는 원 문장의 특정 부분에 특히 주의를 기울이기로 결정하게 됨
역주: 원 페이퍼에는 ‘attnetion’에 이렇게 따옴표를 넣어 강조하지 않았으나 일반적으로 이 이름으로 많이 알려져 있어 강조하여 번역했음. 이 부분에서 ‘mechanism of attention’이라는 단어가 처음 등장함
attention은 여기에서 ‘특정 단어(시퀀스에서의 특정 부분)’와의 호응을 고려한다는 뜻으로 쓰임
- 디코더가 attention 기제를 갖도록 함으로써, 인코더가 원본 문장의 모든 정보를 고정 길이 벡터로 인코딩 해야하는 부담을 줄일 수 있음
- 이 새로운 접근법을 사용하면 정보가 annotation 시퀀스 전체에 퍼져 나갈 수 있으며, 이는 후에 디코더에 의해 선택적으로 탐색될 수 있음
3.2 Encoder: Bidirectional RNN for notating sequences
- 에 설명처럼 일반적인 RNN은 입력 시퀀스 를 첫 번째 기호 에서 마지막 까지 순서대로 읽음
- 그러나 본 논문의 모델에서는 각 단어의 annotation이 선행하는 단어들 뿐만 아니라 뒤에 오는 단어들까지 함께 요약하기를 원함
역주: 기존의 RNN에서는 입력 단어 시퀀스에서 앞부터 차례대로 읽어들이기 때문에 문장에서 특정 단어의 앞쪽에 있는 것들만 그 뒤의 단어 hidden state에 영향을 줄 수 있는데, 특정 단어의 뒤에 있는 단어들까지 문맥에는 영향을 줄 수 있으므로 bi-directional 모델을 써야 한다는 이야기임
-
따라서 저자들은 최근 음성인식에 성공적으로 사용된(Graves et al., 2013) bidirectional RNN(BiRNN, Schuster and Paliwal, 1997)을 사용
- BiRNN은 forward(전방) 및 backward(후방) RNN으로 구성
- forward RNN 는 입력 시퀀스를 있는 그대로 순서대로 읽고(에서 까지) forward hidden states의 시퀀스 를 계산
- backward RNN 는 역순으로 시퀀스를 읽음(에서 까지). 그 결과 backward hidden states 가 됨
- forward hidden state 와 backward 를 연결하여(concatenate) 각 단어 에 대한 annotation을 얻음
- 예를 들어
- 이런 식으로 annotation 에는 앞선 단어들과 이후에 오는 단어들의 축약이 모두 포함되어 있음
- 최근 입력을 더 잘 표현해 내는(represent) RNN의 경향으로 인해 annotation 는 주변의 단어에 초점을 맞추게 됨
- 이 annotation 시퀀스는 디코더와 alignment 모델에 의해 나중에 컨텍스트 벡터를 계산하는 데 사용
- 제안된 모델의 그래픽 일러스트레이션은 Fig. 1을 참조
4. Experiment setting
- 저자들은 영어-프랑스어 번역 task를 이용해 제안된 접근 방식 평가
- ACL WMT ‘14에 의해 제공되는 bilingual, parallel 말뭉치 사용
- 비교를 위해 Cho et al.(2014a)이 최근에 제안한 RNN Encoder-Decoder의 성능을 함께 실험
- 두 모델 모두에 동일한 훈련 절차와 동일한 데이터 세트를 사용
4.1 Dataset
- WMT ‘14에는 다음 영어-프랑스어 parallel 말뭉치가 포함되어 있음(총 850M 단어)
- Europarl (61M 단어)
- New commentary (5.5M 단어)
- UN (421M 단어)
- 두 개의 크롤링된 말뭉치
- 90M
- 272.5M
- Cho et al.(2014a)이 사용했던 절차에 따라 결합 된 코퍼스의 크기를 348M 단어로 줄임
- Axelrod et al.(2011) 데이터 선택 방법을 사용한 것
- 저자들은 위에 언급된 parallel 말뭉치 외에 단일 언어로만 이루어진 데이터는 사용하지 않았으나, 인코더를 pre-training시키는 데 더 큰 단일 언어 코퍼스가 함께 사용될 수도 있다고 언급
- news-test-2012와 news-test-2013를 연결(concatenate)하여 development(validation) 데이터셋을 제작
- 학습 데이터에 없는 3003개의 문장으로 구성된 WMT’14의 테스트 셋(news-test-2014)으로 모델을 평가
- 일반적인 수준의 토큰화1을 한 후에 양쪽 언어에서 가장 많이 사용된 단어 3만 개를 사용하여 모델을 훈련
- 여기에 포함되지 않은 단어는 특수 토큰([UNK])에 매핑
- 소문자화나 stemming 같은 다른 특수한 전처리는 수행하지 않음
4.2 Models
- 저자들은 두 가지 유형의 모델을 훈련
- RNN Encoder-Decoder(RNNencdec, Cho et al., 2014a): 비교를 위한 모델
- 인코더와 디코더는 각각 1000 개의 hidden unit2으로 구성
- RNNsearch: 본 연구에서 제안된 모델
- 인코더: 각각 1000 개의 hidden unit을 갖는 forward & backward RNN으로 구성
- 디코더: 1000개의 hidden unit
- RNN Encoder-Decoder(RNNencdec, Cho et al., 2014a): 비교를 위한 모델
- 두 모델 모두 각 타깃 단어의 조건부 확률을 계산하기 위해(Pascanu et al., 2014) single maxout을 가진 다층 네트워크(Goodfellow et al., 2013) hidden layer 사용
- 각 모델을 두 번 훈련되었는데, 각각은 약 5일 소요
- 최대 30 단어로 이루어진 문장 (RNNencdec-30, RNNsearch-30)
- 최대 50 단어로 이루어진 문장 (RNNencdec-50, RNNsearch-50)
- Adadelta(Zeiler, 2012)와 함께 미니배치 Stochastic Gradient Descent(SGD) 알고리즘 사용
- 각 SGD 업데이트 방향은 80 문장짜리 미니 배치를 사용하여 계산
- 모델이 학습된 후 조건부 확률을 대략(approximately) 최대화하는 번역 문장을 찾기 위해 빔 검색(beam search)을 사용
- ex. Graves, 2012; Boulanger-Lewandowski et al., 2013 참조
- Sutskever et al.(2014)도 접근법을 사용하여 NMT 모델에서 번역을 생성한 바 있음
- 실험에 사용된 모델 및 학습 절차의 아키텍처에 대한 자세한 내용은 부록 A 및 B를 참조
5. Results
5.1 Quantitative Results

Table 1. test set으로 계산한 학습 모델의 BLEU score. 2번째 칼럼은 모든 문장들에 대한 결과를, 3번째 칼럼은 데이터와 번역문 모두에
- 표 1은 BLEU 점수로 측정된 번역 성능을 나열한 것
- 모든 경우에 제안된 RNNsearch가 기존 RNNencdec보다 성능이 우수하다는 것은 표에서 분명함
- 더 중요한 것은 RNNsearch의 성능은 알려진 단어로 구성된 문장 만 고려할 때 기존의 구문 기반 번역 시스템 (모세)의 성능만큼 높음
-
이것은 모세가 RNNsearch와 RNNencdec을 훈련시키는 데 사용했던 평행한 코포라 외에도 별도의 단일 언어 코퍼스 (418M 단어)를 사용한다는 것을 고려할 때 중요한 업적
- 제안된 접근법의 동기 중 하나는 기본 인코더-디코더 접근법에서 고정 길이 컨텍스트 벡터를 사용하는 것
- 우리는 이 제한이 긴 문장으로 저조한 결과를 내기 위한 기본 인코더-디코더 접근법을 만들 수 있다고 추측
- 무화과에서. 2, 문장의 길이가 증가함에 따라 RNNencdec의 성능이 급격히 떨어지는 것을 알 수 있음. 반면에 RNNsearch-30과 RNNsearch-50은 문장의 길이에 더 견고
- RNNsearch50은 특히 길이가 50 이상인 문장에서도 성능 저하를 보이지 않음. 기본 인코더-디코더에 대한 제안 된 모델의 우월성은 RNNsearch-30이 RNNencdec-50보다 성능이 뛰어나다는 사실에 의해 더욱 확인(표 1 참조)
5.2 Qualitative Results
5.2.1 Alignment
- 제안 된 접근법은 생성 된 번역의 단어와 소스 문장의 단어 사이의 (부드러운) 정렬을 검사하는 직관적인 방법을 제공
- 이것은 그림 3에서와 같이 Eq. (6)의 주석 가중치 ij를 시각화하여 수행
- 각 그림의 행렬 행은 주석과 연관된 가중치
- 이로부터 우리는 대상 단어를 생성할 때 소스 문장의 어떤 위치가 더 중요하다고 간주되었는지를 알 수 있음
- 우리는 그림의 정렬을 볼 수 있습니다. 3 영어와 프랑스어 사이의 단어 정렬은 대부분 단조로움. 각 행렬의 대각선을 따라 강한 가중치가 보임
- 그러나 우리는 또한 여러 가지 사소한 비 단조로운 정렬을 관찰. 형용사와 명사는 일반적으로 프랑스어와 영어간에 다르게 정렬되며, 우리는 Fig에서 그 예를 찾아볼 수 있음
- 3 (a). 이 그림에서 우리는 모델이 [유럽 경제 지역]이라는 문구를 [구역 경제] 유럽으로 정확하게 번역한다는 것을 알 수 있음
- RNNsearch는 [지역]과 [구역]을 올바르게 정렬하고 두 단어 ([유럽]와 [경제])를 뛰어 넘은 다음한 번에한 단어를 되돌아보고 전체 문구 [zone economique Europeenne]를 완성
- 예를 들어, Fig에서와 같이 하드 정렬에 반대하는 부드러운 정렬의 강도가 분명
- 3 (d) [l’ homme]로 번역된 근원 문구 [남자]를 생각해보십시오. 어떤 단단한 정렬도 [l]과 [man]을 [homme]에 매핑. 번역에는 도움이 되지 않음[le], [la], [les] 또는 [l’]로 번역해야하는지 여부를 결정하기 위해 다음 단어를 고려해야하기 때문
- 우리의 소프트 정렬은 모델이 [the]와 [man]을 모두 보게 함으로써 자연스럽게 이 문제를 해결
- 이 예에서 모델은 [l’]로 올바르게 변환할 수 있음. 우리는 그림 3의 모든 제시된 사례에서 비슷한 행동을 관찰. 부드러운 정렬의 또 다른 이점은 자연스럽게 다른 길이의 소스 및 대상 구를 다루며, 일부 단어를 아무데도 ([NULL])에 매핑하는 직관적인 방법을 요구하지 않고도 (예 : Koehn, 2010).
5.2.2 Long sentences
-
Fig2에서 명확하게 볼 수 있듯이 제안 된 모델 (RNNsearch)은 긴 문장을 번역 할 때 기존 모델 (RNNencdec)보다 훨씬 낫습니다. 이것은 RNNsearch가 긴 문장을 고정 길이 벡터로 완벽하게 인코딩할 필요가 없지만 특정 단어를 둘러싸고 있는 입력 문장의 부분만 정확하게 인코딩해야하기 때문일 수 있음
-
예를 들어, 테스트 세트에서 이 원본 문장이 있음
(영어 문장)
- RNNencdec-50은 이 문장을 다음과 같이 번역
(번역 문장)
-
RNNencdec-50은 [의료 센터]까지 원본 문장을 올바르게 번역. 그러나 거기에서 (아래선) 소스 문장의 원래 의미에서 벗어났습니다. 예를 들어, 그것은 [병원에서 건강 관리 종사자로서의 지위에 기초하여] 원본 문장에서 [en fonction de son etat de sante] ( “건강 상태에 근거하여”)를 대체
-
반면에 RNNsearch-50은 다음과 같은 정확한 번역을 생성하여 세부 사항을 생략하지 않고 입력 문장의 전체 의미를 보존
(문장)
- 테스트 세트에서 다른 문장을 고려하십시오.
(영어 문장)
- RNNencdec-50은 이 문장을 다음과 같이 번역
(번역 문장)
-
이전 예제와 마찬가지로 RNNencdec은 약 30 개의 단어를 생성 한 후 소스 문장의 실제 의미에서 벗어나기 시작했습니다 (아래 줄 지어있는 구 참조). 그 시점 이후, 번역의 품질은 악화되며, 마감 인용 부호가 없는 것과 같은 기본 실수가 있음
-
다시 말하지만, RNNsearch-50은 이 긴 문장을 올바르게 번역할 수 있었음
(번역 문장)
- 이미 제시된 정량적 결과와 함께 이러한 질적 관찰은 RNNsearch 아키텍처가 표준 RNNencdec 모델보다 긴 문장을 훨씬 더 신뢰할 수 있는 번역을 가능하게한다는 가설을 확인
- 부록 C에서는 RNNencdec-50, RNNsearch-50 및 Google 번역과 함께 참조 번역본에서 생성된 긴 소스 문장의 샘플 번역을 제공
6. Related work
6.1 Learning to align
- 출력(output) 기호와 입력(input) 기호를 align하는 유사한 접근법이 최근 Graves(2013)에 의해 손글씨 합성의 분야에서 제안된 바 있음
- 손글씨 합성은 모델이 주어진 문자 시퀀스의 필체를 생성해 내는 task
- 그의 연구에서 그는 mixture of Gaussian kernel을 사용하여 각 커널의 위치, 너비 및 혼합 계수가 정렬 모델에서 예측된 annotation의 가중치를 계산
- 보다 구체적으로는 보면, 그의 alignment은 위치가 단조롭게 증가하도록 위치를 예측하도록 제한
- 본 논문의 접근 방식과의 가장 큰 차이점은 (Graves, 2013)에서는 annotation의 가중치의 모드가 한 방향으로만 이동한다는 것
- 기계번역에서는 문법적으로 올바르게 번역하기 위해 종종 (장거리) 재배열이 종종 필요하기 때문에(ex. 영어-독일어) 이는 심각한 한계
- 반면에 본 연구에서의 접근 방식은 번역 문장 각 단어에 대해 원본 문장의 모든 단어의 annotation 가중치를 계산해야 함
- 이러한 단점은 대부분의 입력 및 출력 문장이 15-40 단어인 번역 task에서는 심각하지는 않음
- 그러나 이 문제가 추후 본 모델이 다른 task에 사용되는 것을 제한할 수는 있음
6.2 Neural networks for machine translation
- Bengio et al.(2003)은 신경망을 사용해 고정된 개수의 이전 단어가 주어진 상태에서 특정 단어의 조건부 확률을 모델링하는 신경 확률 언어 모델을 도입했으며, 신경망은 기계 번역에 널리 사용되고 있음
- 그러나 신경망의 역할은 기존 통계 기계 번역 시스템에 단일 기능을 제공하거나 기존 시스템에서 제공하는 후보 번역 목록을 다시 순위를 매기는 것으로 크게 제한되었음
- 예를 들어 Schwenk(2012)는 FNN을 사용하여 원본 및 타깃 구절의 점수를 계산하고 구문 기반 통계 기계 번역 시스템의 추가 기능으로 이 점수를 사용할 것을 제안
- 최근에는 Kalchbrenner and Blunsom(2013)과 Devlin et al.(2014)은 기존 번역 시스템의 하위 구성 요소로서 신경 네트워크를 성공적으로 사용했다고 보고했음
- 전통적으로 타깃 측 언어 모델로 훈련 된 신경망은 후보 번역 목록을 다시 작성하거나 재 순위를 매기는 데 사용됨(ex. Schwenk et al., 2006 참조)
- 위의 접근법이 최첨단 기계 번역 시스템에 대한 번역 성능을 향상시키는 것으로 나타났지만 저자들은 신경망을 기반으로 완전히 새로운 번역 시스템을 설계하는, 보다 야심찬 목표에 더 관심이 있음
- 이 논문에서 저자들은 자신들이 고려하는 신경 기계 번역 접근법은 이러한 초기 연구에서 급진적인 출발이라고 강조
- 기존 시스템의 일부로 신경망을 사용하는 대신 본 모델은 자체적으로 작동하여 원본 문장에서 직접 번역을 생성
7. Conclusion
- 인코더-디코더 접근법이라고 하는 신경 기계 번역에 대한 일반적인 접근법은 전체 입력 문장을 번역이 디코딩 될 고정 길이 벡터로 인코딩
-
우리는 고정 길이 문맥 벡터의 사용이 Cho et al.이 보고한 최근의 경험적 연구를 토대로 긴 문장을 번역하는 데 문제가 있다고 추측. (2014b)와 푸젯 아바디 외(2014).
- 이 논문에서는 이 문제를 다루는 새로운 아키텍처을 제안
- 기본 인코더-디코더를 확장하여 모델이 입력 단어 집합을 검색하거나 각 대상 단어를 생성 할 때 인코더로 계산된 annotation을 사용하도
- 이렇게 하면 모델이 전체 원 문장을 고정 길이 벡터로 인코딩하지 않아도 되고 모델이 다음 대상 단어의 생성과 관련된 정보에만 집중할 수 있음
- 이것은 더 긴 문장에 좋은 결과를 산출하는 NMT 시스템의 능력에 큰 긍정적인 영향을 미침
- 전통적인 기계 번역 시스템과 달리 alignment 메커니즘을 포함한 모든 번역 시스템은 올바른 번역을 생성하는 더 나은 log 확률로 결합적으로(jointly) 학습됨
- 저자들은 영어와 프랑스어로 번역하는 작업을 위해 RNNsearch라고 불리는 제안된 모델을 테스트
- 이 실험은 제안 된 RNNsearch가 문장 길이에 관계없이 기존의 인코더-디코더 모델 (RNNencdec)보다 훨씬 뛰어나고 원본 문장의 길이에 훨씬 견고하다는 것을 보여주었음
- RNNsearch에서 생성 된 (soft-) alignment를 조사한 질적 분석에서 올바른 번역을 생성 할 때 원본 문장에서 각 대상 단어를 관련 단어 또는 annotation과 올바르게 정렬 할 수 있다고 결론
- 아마도 더 중요한 것은 제안된 접근법이 기존 구문 기반 통계 기계 번역과 비슷한 번역 성능을 달성했다는 것
- 제안된 모델, 즉 신경 기계 번역의 전체 가족이 올해만 제안된 것을 고려할 때 놀라운 결과
- 저자들은 여기서 제안된 아키텍처가 더 나은 기계 번역과 일반적으로 자연 언어에 대한 더 나은 이해를 향한 유망한 단계라고 믿음. 미래에 남은 과제 중 하나는 알려지지 않은 단어 또는 희귀한 단어를 더 잘 처리하는 것. 이것은 모델이 더 널리 사용되고 모든 상황에서 현재의 최첨단 기계 번역 시스템의 성능과 일치하도록 요구 될 것
Acknowledgements
- 저자는 Theano의 개발자에게 감사하고 싶습니다 (Bergstra et al., 2010; Bastien et al., 2012). NSERC, Calcul Quebec, Compute Canada, Canada Research Chairs 및 CIFAR와 같은 연구 자금 및 컴퓨팅 지원 기관의 지원을 인정합니다. Bah-danau는 Planet Intelligent Systems GmbH의 지원에 감사드립니다. 우리는 또한 펠릭스 힐, 바트 반 메리엔보어, 장 푸젯-아바디, 콜린 데빈, 태호 김에게 감사한다.
https://norman3.github.io/papers/docs/google_neural_machine_translation.html




댓글남기기