
참고자료
- 원 논문 (xDeepFM: Combining Explicit and Implicit Feature Interactions for Recommender Systems)
들어가기 전에 알아야될 용어
ABSTRACT
- Combinatorial features은 많은 상용 모델의 성공에 필수적입니다. 기능을 수동으로 제작하면 보통 웹시스템에서 원시 데이터의 다양성, 볼륨 및 속도로 인해 비용이 많이 듭니다.
- 벡터곱의 관점에서 상호 작용을 측정하는 Factorization based models은 조합 특징의 패턴을 자동으로 학습하고 보이지 않는 특징으로 일반화 할 수 있습니다.
- 다양한 분야에서 심층신경망(DNN)의 큰 성공으로, 최근 연구자들은 저차원 및 고차 특징 상호 작용을 배우기 위해 여러 DNN 기반 인수분해 모델을 제안했습니다. 데이터에서 임의의 기능을 학습하는 강력한 기능에도 불구하고 DNN은 암시적으로 비트 단위로 기능 상호 작용을 생성합니다.
- 이 논문에서, 명시적인 방식으로 그리고 벡터 수준에서 특징적인 상호 작용을 생성하는 것을 목표로 하는 Novel Compressed Interaction Network(CIN)를 제안한다.
- CIN은 CNN(Convolutional Neural Network) 및 RNN(Recurrent Neural Network) 모델과 일부 기능을 공유함을 보여줍니다. 또한 CIN과 클래식 DNN을 하나의 통합 모델로 결합하고 이 새로운 모델 eXtreme Deep Factorization Machine (xDeepFM)을 명명했습니다.
- 한편으로, xDeepFM은 bounded-degree도 기능 상호 작용을 명시 적으로 학습할 수 있습니다.
- 반면에, 임의의 하위 및 상위 기능 상호 작용을 암시적으로 학습할 수 있습니다. 세 가지 실제 데이터 세트에 대해 포괄적인 실험을 수행합니다.
- 결과는 xDeepFM이 최첨단 모델을 능가한다는 것을 보여줍니다. https://github.com/Levingseason/xDeepFM 에서 xDeepFM의 소스 코드를 공개했습니다.
1. INTRODUCTION
- feature은 많은 예측 시스템의 성공에 핵심적인 역할을 합니다. 원시 기능을 사용하는 것이 최적의 결과를 가져오는 경우는 거의 없기 때문에 데이터 과학자는 일반적으로 최상의 예측 시스템을 생성하거나 데이터마이닝 게임을 승리하기 위해 원시 기능을 변환하는 데 많은 노력을 기울입니다
- 기능 변환의 주요 유형 중 하나는 범주형 기능에 대한 교차 제품 변환입니다. 교차 기능 또는 multi-way 기능이라고 하며 여러 원시 기능의 상호 작용을 측정합니다.
- 예를 들어, 사용자가 Microsoft Research Asia에서 근무하고 월요일에 딥러닝에 대한 기술 기사를 표시하는 경우 3-way 기능(user_organization = msra, item_category = deeplearning, time = monday)는 값이 1입니다.
- 기존의 교차 피쳐 엔지니어링에는 세가지 주요 단점이 있습니다.
- 첫째, 고품질 기능을 사용하려면 비용이 많이 듭니다. 올바른 기능은 일반적으로 작업별로 다르므로 데이터 과학자는 도메인 전문가가 되고 의미있는 교차 기능을 추출하기 전에 제품 데이터의 잠재적 패턴을 탐색하는데 많은 시간을 소비해야 합니다.
- 둘째, 웹규모 추천 시스템과 같은 대규모 예측 시스템에서 수많은 원시 기능을 사용하여 모든 교차 기능을 수동으로 추출할 수 없습니다.
- 셋째, hand-crafted 크로스 기능은 훈련 데이터에서 보이지 않는 상호 작용을 일반화하지 않습니다. 따라서 수동 엔지니어링 없이 기능의 상호 작용하는 법을 컴퓨터가 배우는 것은 중요한 작업입니다.
- Factorization Machines(FM)는 각 특징 i를 잠재 인자 벡터 vi = [vi1, vi2, …, viD]에 포함시키고 쌍별 특징 상호 작용은 잠재 벡터의 inner product으로 모델링됩니다.
- 본 논문에서는 비트 벡터를 사용하여 잠재 벡터의 요소(FM)를 나타냅니다.
- 클래식 FM은 임의의 고차 특징 상호 작용으로 확장될 수 있지만 한 가지 주요 단점은 유용하고 쓸모없는 조합을 포함하여 모든 특징 상호 작용을 모델링할 것을 제안한다는 점
- 쓸모없는 기능과의 상호 작용으로 인해 노이즈가 발생하고 성능이 저하될 수 있습니다.
- 최근에는 DNN (Deep Neural Network)이 강력한 기능 표현 학습 기능을 통해 컴퓨터 비전, 음성 인식 및 자연어 처리에 성공했습니다. 정교하고 선택적인 기능 상호 작용을 배우기 위해 DNN을 활용하는 것은 약속입니다.
- 고차원의 특징 상호 작용을 배우기 위해 Factorisation-machine 지원 신경망 (FNN)을 제안한다.
- 사전으로 훈련된 FM 모델을 사용하여 DNN을 적용하기 전에 필드 임베딩을 위하여 사용합니다. PNN(Product-based Neural Network) 모델을 추가로 제안합니다.
- 임베딩 레이어와 DNN 레이어 사이의 제품 레이어 사전 훈련된 FM에 의존하지 않습니다.
- FNN 및 PNN의 주요 단점은 상위 기능 상호 작용에 더 집중하고 하위 순서 상호 작용은 거의 포착하지 않습니다.
- Wide & Deep 및 DeepFM 모델은 암기 및 일반화를 배우기 위해 얕은 구성 요소와 깊은 구성 요소를 포함하는 하이브리드 아키텍처를 도입하여이 문제를 극복합니다. 따라서 이들은 하위 및 상위 기능 상호 작용을 공동으로 학습할 수 있습니다.
- 위에서 언급한 모든 모델은 DNN을 활용하여 고차원 피쳐 상호 작용을 학습합니다.
- 그러나 DNN은 내재된 방식으로 고차원 기능 상호 작용을 모델링합니다.
- DNN이 학습한 최종 기능은 임의적일 수 있으며, 최대 기능 상호 작용 정도에 대한 이론적 결론은 없습니다.
- 또한 DNN은 비트 단위의 상호 작용을 특징으로 하며 벡터 방식의 상호 작용을 특징으로 하는 기존 FM 프레임워크와 다릅니다.
- 따라서, 추천 시스템 분야에서, DNN이 실제로 고차 특징 상호 작용을 나타내는 가장 효과적인 모델인지 여부는 여전히 의문의 여지가 남아있다.
- 이 논문에서는 신경망 기반 모델을 제안하여 명시적, 벡터 방식으로 기능 상호 작용을 학습합니다.
- 접근 방식은 DCN(Deep & Cross Network)을 기반으로 하며, 제한된 각도의 특징 상호 작용을 효율적으로 캡처하는 것을 목표로 합니다.
- 그러나, 2.3 장에서 DCN이 특별한 형식의 상호 작용으로 이어질 것이라고 주장할 것입니다.
- 따라서 DCN의 교차 네트워크를 대체하기 위해 새로운 Compressed Interaction Network (CIN)를 설계합니다.
- CIN은 기능 상호 작용을 명시적으로 학습하고 상호 작용의 정도는 네트워크 깊이에 따라 증가합니다.
- Wide & Deep 및 DeepFM 모델의 정신에 따라, 명시적 고차 상호 작용 모듈을 암시적 상호 작용 모듈 및 전통적인 FM 모듈과 결합하고 조인트 모델 eXtreme Deep Factorization Machine (xDeepFM)의 이름을 지정합니다.
- 새로운 모델에는 수동 기능 엔지니어링이 필요하지 않으며 지루한 기능 검색 작업에서 데이터 과학자를 제외합니다. 요약하면 다음과 같은 기여를 합니다.
- 명시적 및 암묵적 고차 기능 상호 작용을 효과적으로 학습하고 수동 기능 엔지니어링이 필요없는 eXtreme Deep Factorization Machine (xDeepFM)이라는 새로운 모델을 제안합니다.
- xDeepFM에서 Compressed Interaction Network (CIN)를 설계합니다. 고차원의 기능 상호 작용을 명시적으로 학습합니다. 각 레이어에서 피처 상호 작용의 정도가 증가하고 피처는 비트 단위가 아닌 벡터 단위로 상호 작용합니다.
- 세 가지 실제 데이터 세트에 대해 광범위한 실험을 수행했으며 그 결과 xDeepFM이 여러 최신 모델보다 성능이 뛰어남을 보여줍니다.
- 본 논문의 나머지 부분은 다음과 같이 구성되어있다.
- 섹션 2는 딥러닝 기반 추천 시스템을 이해하는데 필요한 예비 지식을 제공합니다.
- 섹션 3에서는 제안 된 CIN 및 xDeepFM 모델을 자세히 소개합니다.
- 섹션 4에서 여러 데이터 세트에 대한 실험적 탐구를 제시할 것이다. 관련 연구는 섹션 5에서 논의된다.
2. PRELIMINARIES
2. Embedding Layer
- 컴퓨터 비전 또는 자연어 이해에서 입력, 데이터는 일반적으로 알려진 이미지 또는 텍스트 신호입니다. 공간적 및 / 또는 시간적으로 상관되므로 DNN을 적용할 수 있습니다.
- 조밀한 구조로 원시 피처에 직접 그러나 웹 규모 추천 시스템에서 입력 기능은 드문 드문하고 차원이 크기 때문에 공간적 또는 시간적 상관 관계가 명확하지 않습니다.
- 따라서 다중 분야 범주형 형식은 관련 작업에서 널리 사용됩니다.
- 예를 들어, 하나의 입력 인스턴스 [user_id = s02, gender = male, organization = msra, interests = comedy & rock]는 일반적으로 원-핫 인코딩을 통해 고차원 희소 피쳐로 변환됩니다.
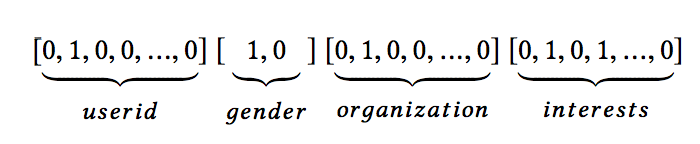
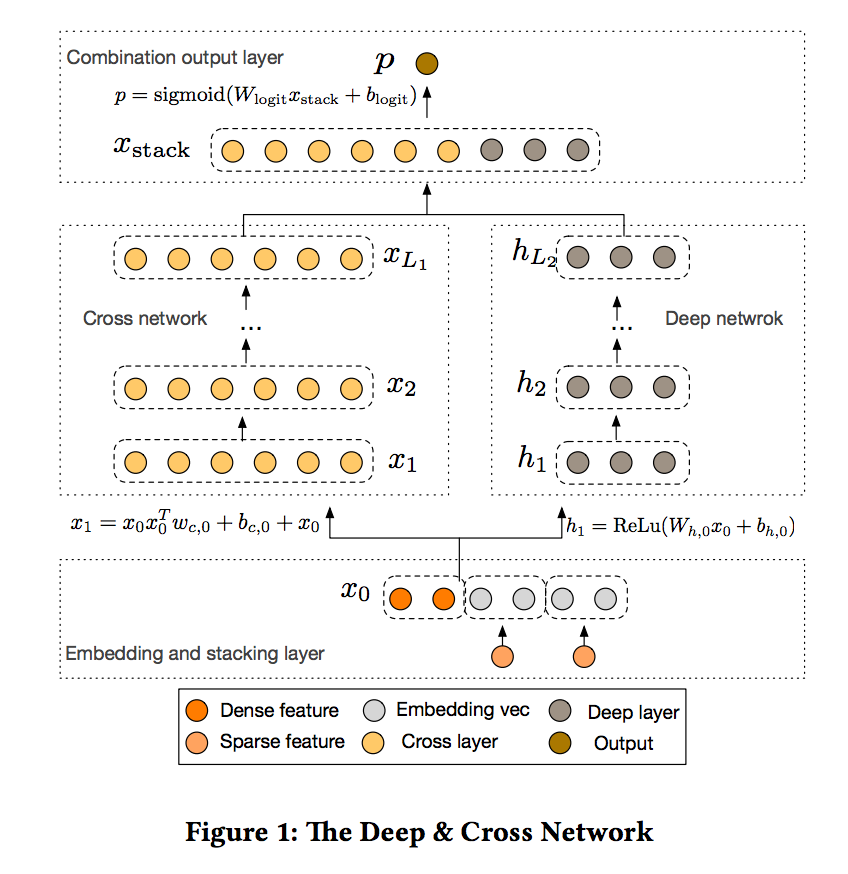
- 임베드 된 레이어는 row 피처 입력에 적용되어 낮은 차원의 밀도가 높은 실수값 벡터로 압축합니다. 필드가 1인 경우 피처 임베딩이 필드 임베딩으로 사용됩니다.
- 위의 예를 들어 피처 수의 포함은 필드 성별의 포함으로 간주됩니다. 필드가 다인 경우 피처 임베딩 합계가 필드 임베딩으로 사용됩니다. 임베딩 레이어는 그림 1에 설명되어 있습니다.
- 임베딩 레이어의 결과는 넓게 연결된 벡터입니다. 여기서 m은 필드 수를 나타내고 ei ∈ R^D는 하나의 필드를 포함합니다. 인스턴스의 피처 길이는 다양할 수 있지만 임베딩의 길이는 m x D와 같습니다. 여기서 D는 필드 임베딩의 차원입니다.
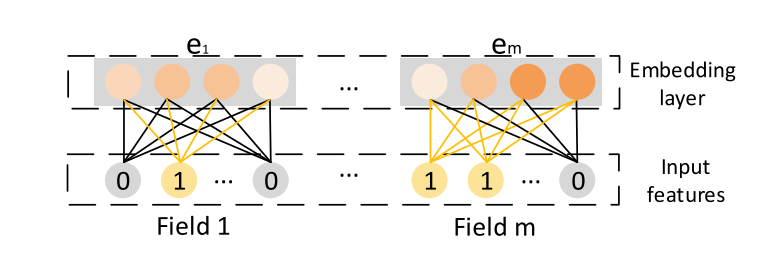
2.2 Implicit High-order Interactions
- FNN[46], 딥크로싱[37] 및 Wide & Deep[5]의 깊은 부분 필드 임베딩 벡터 e에서 피드 포워드 신경망을 이용하여 고차원 특징 상호 작용을 학습한다.
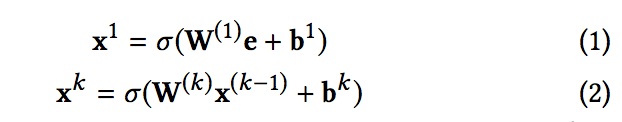
- 여기서 : k는 레이어 깊이, σ는 활성화 함수, x^k : k 번째 레이어의 출력입니다. FM or Product Layer를 제외하고는 시각적 구조는 매우 유사합니다. (그림 2)
- 아키텍처는 bit-wise fashion. 다시 말해서, 같은 안에 있는 요소조차 필드 임베딩 벡터는 서로 영향을 미칩니다. PNN[31] 및 DeepFM[9]는 위 아키텍처를 약간 수정합니다.
- 임베딩 벡터 e에 DNN을 적용하는 것 외에도 아키텍처에서 양방향 상호 작용 레이어를 추가합니다. 따라서 비트 및 벡터와의 상호 작용이 모델에 포함됩니다. PNN과 DeepFM의 주요 차이점은 PNN은 제품 계층의 출력을 DNN에 연결하는 반면, DeepFM은 FM 계층을 출력 장치에 직접 연결한다는 것
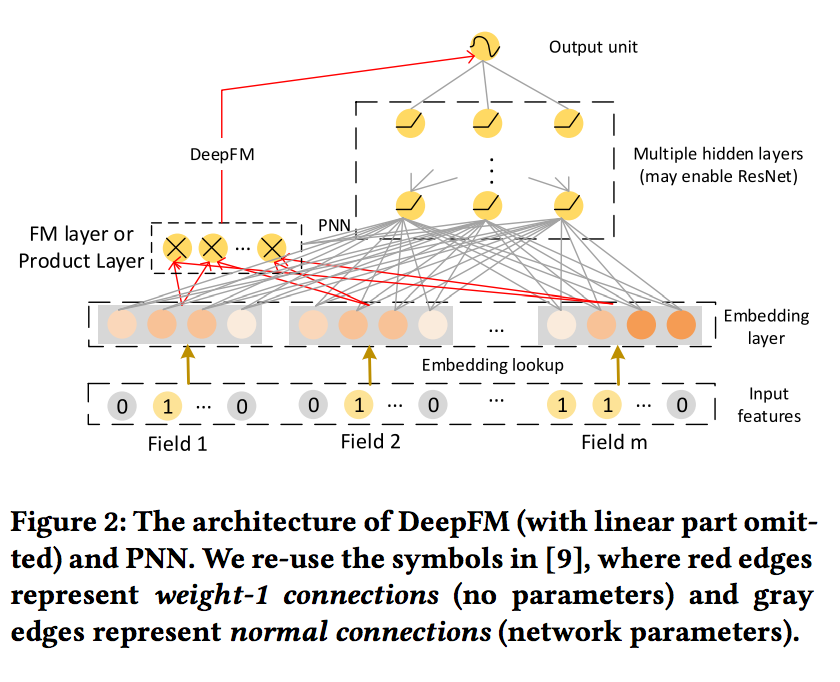
2.3 Explicit High-order Interactions
- 아키텍처가 크로스 네트워크(CrossNet)를 제안한다. 고차 피쳐 상호 작용을 명시적으로 모델링하는 것을 목표로 합니다. 기존의 완전히 연결된 피드 포워드와 달리 네트워크, 숨겨진 레이어는 다음과 같은 십자가에 의해 계산됩니다. 동작 : 여기서 wk, bk, xk ∈ R^mD는 각 k 번째 층의 가중치, 바이어스 및 출력이다.
- CrossNet이 특별한 유형의 고차원 피처 상호 작용을 배우고 있으며, 여기서 CrossNet의 각 숨겨진 레이어는 x0의 스칼라 배수입니다.
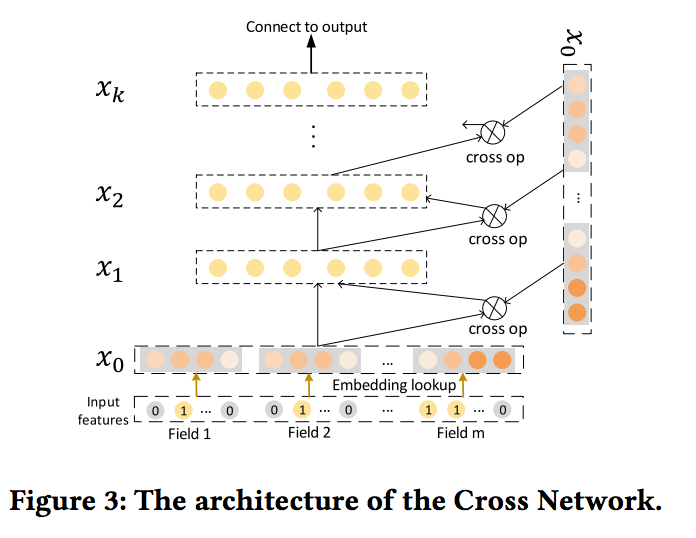
- 특징적인 상호 작용은 매우 효율적이며 (DNN 모델과 비교할 때 복잡성은 무시할 수 있음) 단점은 다음과 같습니다.
- CrossNet의 출력은 특수한 형태로 제한되며 각 숨겨진 레이어는 x0의 스칼라 배수입니다.
- 상호 작용은 비트 방식 (bit-wise fashion)으로 이루어집니다
3. OUR PROPOSED MODEL
3.1. Compressed Interaction Network
-
Compressed Interaction 이라는 새로운 교차 네트워크를 설계합니다.
- 상호 작용은 비트 단위가 아닌 벡터 단위로 적용됩니다.
- 고차원 특징 상호 작용이 명시적으로 측정된다
- 네트워크의 복잡성은 상호 작용의 정도에 따라 기하 급수적으로 증가하지 않습니다. 임베딩 벡터는 벡터와의 상호 작용을 위한 단위로 간주되므로, 이후에 필드 임베딩의 출력을 공식화합니다.
- 행렬 X ∈ R m × D로, 여기서 X의 i 번째 행은 i 번째 필드의 포함 벡터입니다.
- CIN에서 k 번째 레이어의 출력도 행렬입니다 (Xk) Xk ∈ R Hk × D, 여기서 Hk는 (embedding) 특징의 수를 나타낸다
- k 번째 레이어에서 벡터를 만들고 H0 = m 이라고 할 때. 각 계층에 대해 X k는 다음을 통해 계산됩니다.
- 여기서 1 ≤ h ≤ Hk, Wk, h ∈ R Hk-1xm은 h 번째 특징 벡터에 대한 모수 행렬이고 ◦는 Hadamard product을 나타냅니다.
- Hadamard product 예 : ⟨a1, a2, a3⟩ ◦ ⟨b1, b2, b3⟩ = ⟨a1b1, a2b2, a3b3⟩.
- Xk는 Xk-1과 X0 사이의 상호 작용을 통해 도출되므로, 피처 상호 작용이 명시적으로 측정되고 상호 작용의 정도는 층 깊이에 따라 증가합니다.
- CIN의 구조는 RNN(Recurrent Neural Network)과 매우 유사하며 다음 은닉층의 출력은 마지막 은닉층과 추가 입력에 의존합니다.
- 모든 레이어에 벡터를 포함하는 구조를 유지하므로 상호 작용은 벡터 수준에서 적용됩니다. 수학식 6은 컴퓨터 비전에서 잘 알려진 CNN (Convolutional Neural Networks)과 밀접한 관련이 있다는 것이 흥미롭다.
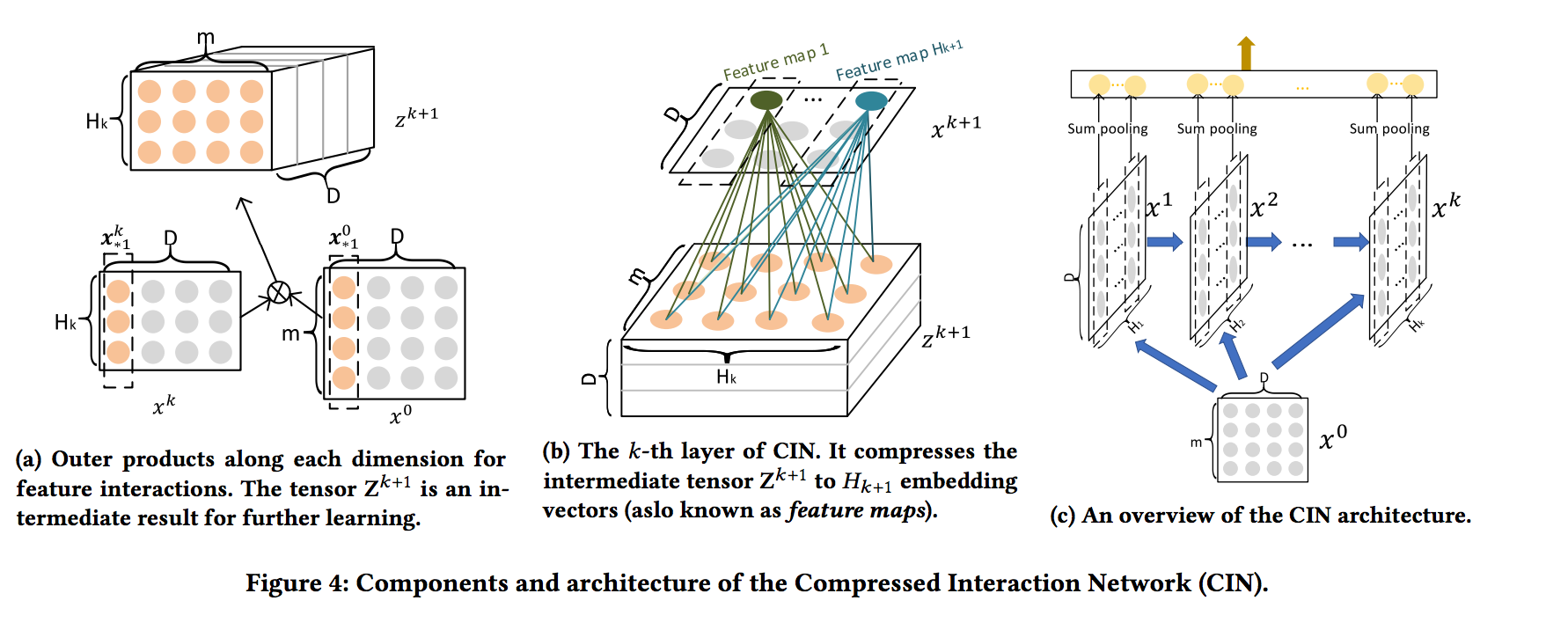
- 그림 4a에 표시된 것처럼 외부텐서 Zk + 1을 소개합니다. (은닉 레이어 Xk (along each embedding dimension) 및 원본 피처 매트릭스 X0의 outer products)
- Z k + 1은 특수한 유형의 이미지로 간주될 수 있으며 Wk, h는 필터입니다.
- 그림 4b에 표시된 것처럼 임베드 차원(D)를 따라 Z k + 1을 가로 질러 필터를 밀고 숨겨진 벡터 X^k+1를 얻습니다.
- 일반적으로 컴퓨터 비전에서 피쳐 맵이라고합니다. 따라서 X k는 Hk의 다른 기능 맵의 모음입니다.
- 용어 CIN의 명칭에서 “압축된”은 k 번째 숨겨진 층이 Hk-1 × m 벡터의 잠재적 공간을 Hk 벡터로 압축함을 나타낸다.
- 그림 4c는 CIN의 구조에 대한 개요를 제공한다. 숨겨진 모든 계층 X
k, k ∈ [1, T]는 출력 장치와 연결되어 있습니다.
- 먼저 숨겨진 레이어의 각 feature 맵에 합계 풀링을 적용합니다
- 따라서, k 번째 숨겨진 계층에 대해 길이 Hk를 갖는 풀링 벡터 p k = [pk1, pk2, …, pk Hk]를 갖는다.
- 숨겨진 레이어의 모든 풀링 벡터는 출력 단위에 연결되기 전에 연결됩니다.
- 이진 분류에 직접 CIN을 사용하는 경우 출력 단위는 시그모이드 노드입니다. (w0 : regression parameters)
3.2. CIN Analysis
-
제안된 CIN을 분석하여 모델 복잡성 & 잠재적 효과를 연구합니다
- 3.2.1 공간 복잡성
- k번째 계층에서의 h번째 특징 맵은 정확히 Wk, h의 크기 인 Hk-1 × m 파라미터를 포함한다.
- 따라서, k번째 층에는 Hk × Hk-1 × m 파라미터가 존재한다.
- 출력 단위의 마지막 회귀 계층을 고려하면 Hk 매개 변수, CIN에 대한 총 매개 변수 수는 Hk × (1 + Hk-1 × m) (k=1~T).
- CIN은 차원 D. 반면에 레이어 DNN에는 m × D × H1 + HT + Hk × Hk−1 (k=2~T) 매개 변수이며 매개 변수 수는 포함 치수 D에 따라 증가합니다.
- 일반적으로 m과 Hk는 크지 않으므로 Wk,h의 스케일은 허용됩니다.
- 필요한 경우 L차 분해를 이용하여 Wk, h를 두 개의 작은 행렬 Uk, h ∈ R Hk-1 × L 및 Vk, h ∈ R m × L로 대체할 수 있습니다.
- 여기서 L ≪ H 및 L ≪ m 이하, 각각의 숨겨진 층은 간략화를 위해 동일한 개수 (H)의 피쳐 맵을 갖는다고 가정합니다.
-
L 차 분해를 통해 CIN의 공간 복잡성이 감소합니다. 대조적으로, 평범한 DNN의 공간 복잡도는 필드 임베딩의 차원(D)에 민감하다.
- 3.2.2 시간 복잡성.
- 텐서 Zk + 1 (도 4a에 도식된 바와 같이)을 계산하는 비용은 O (mHD) 시간이다.
- 하나의 숨겨진 계층에 H 기능맵이 있으므로 T 계층 CIN을 계산하는 데 O (mH^2DT) 시간이 걸립니다.
- 대조적으로, A T-layers 평범한 DNN은 O (mHD + H^2T) 시간이 걸립니다. 따라서 CIN의 주요 단점은 시간 복잡성에 있습니다.
- 3.2.3 다항식 근사
- 다음으로 CIN의 고차 상호작용 속성을 살펴봅니다. 간단히 하기 위해, 숨겨진 레이어의 피처맵 수가 필드수 m과 같다고 가정합니다.
- [m]은 m보다 작거나 같은 양의 정수 세트를 나타냅니다.

- l 및 k와 관련된 모든 계산은 이미 이전 숨겨진 레이어에서 완료되었습니다.
- 명확성을 위해 수식 11의 요소를 확장합니다. 각 기능맵을 관찰 할 수 있습니다 두번째 레이어 모델에서 O(m2) 매개 변수와의 3 방향 상호 작용
- 고전적인 k차 다항식에는 O(mk) 계수가 있습니다. CIN은 일련의 기능맵 측면에서 O(km3) 매개변수 만 사용하여 이 다항식 클래스에 근사합니다.
- 이 클래스의 각 벡터 polylnomial에는 O(mk) 계수가 있습니다. 그때, 우리의 CIN은 다음과 같이 계수 wα에 접근합니다. 여기서, B = [B1, B2, …, Bα]는 다중 인덱스이고 Pα는 모든 인덱스 순열의 집합입니다.
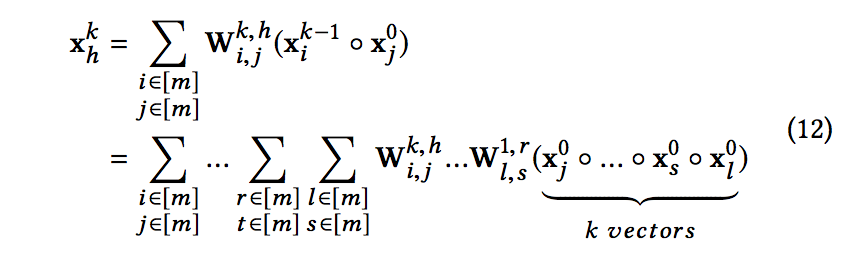
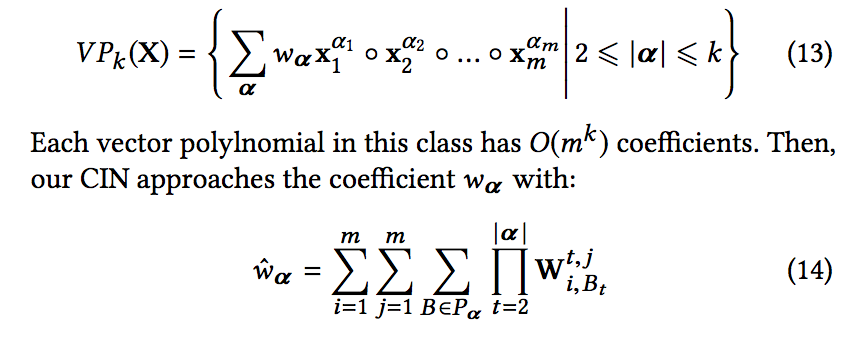
3.3. Combination with Implicit Networks
- 2.2장에서 논의한 것처럼, DNN은 암시적 고차 기능 상호 작용을 학습합니다.
- CIN과 DNN은 서로 보완할 수 있으므로 모델을 보다 강력하게 만드는 직관적인 방법은 두 구조를 결합하는 것입니다.
- 결과 모델은 Wide & Deep 또는 DeepFM 모델과 매우 유사합니다. 아키텍처는 그림 5에 표시되어 있습니다.
- 새로운 모델 eXtreme Deep Factorization Machine (xDeepFM)의 이름을 지정합니다.
- 한편으로는 하위 및 상위 기능 상호 작용이 모두 포함되어 있습니다. 반면에 암시적 기능 상호 작용과 명시적 기능 상호 작용이 모두 포함됩니다. 결과 출력 단위는 다음과 같습니다.

- σ는 시그모이드 함수이고 a는 원시 피처입니다. x k dnn, p +는 각각 일반 DNN 및 CIN의 출력입니다.
- w * 및 b는 학습 가능한 매개 변수입니다. 이진 분류의 경우 손실 함수는 로그 손실입니다.
- 여기서 N은 총 훈련 인스턴스 수입니다. 최적화 프로세스는 다음 목적 함수를 최소화하는 것입니다.
- λ는 정규화 항을 나타내고 Θ는 선형 회귀분석, CIN 및 DNN에 포함된 파라미터
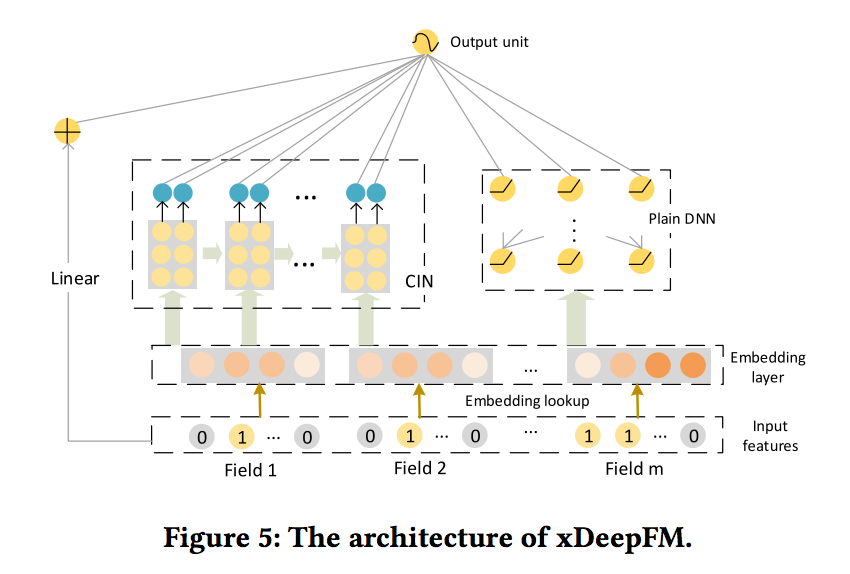
- 3.3.1 Relationship with FM and DeepFM
- 모든 필드가 1이라고 가정하십시오. 그림 5에서 CIN 부분의 깊이 및 기능맵이 모두 1로 설정된 경우 xDeepFM은 FM 계층에 대한 선형 회귀 가중치를 학습하여 DeepFM의 일반화임을 알 수 있습니다
- DeepFM에서는 FM 레이어는 계수없이 출력 장치에 직접 연결됩니다. DNN 부품을 추가로 제거하고 동시에 피쳐 맵에 상수 합계 필터 (파라미터 학습없이 입력 합계를 가져옴)를 사용하면 xDeepFM이 기존 FM 모델로 다운 그레이드됩니다.
4. EXPERIMENTS
- 이 섹션에서는 다음과 같은 질문에서 광범위한 실험을 수행합니다.
- (Q1) 제안된 CIN은 어떻게 high-order feature interactions 학습을 수행됩니까?
- (Q2) 추천 시스템에 대해 명시적 및 암시적 고차 기능 상호 작용을 결합해야 합니까?
- (Q3) 네트워크 설정이 xDeepFM의 성능에 어떤 영향을 줍니까?
4.1. Experiment Setup
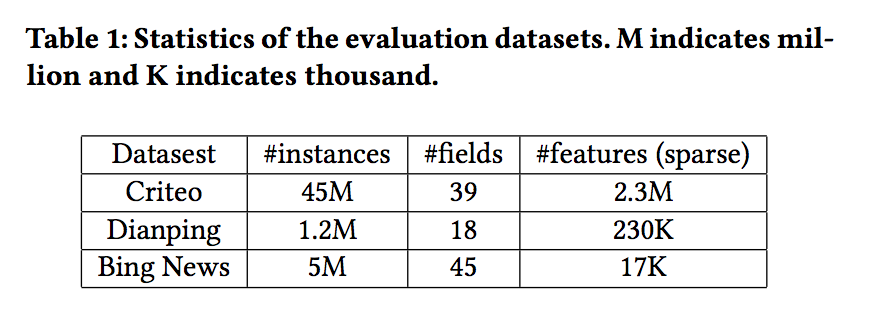
- 4.1.1 데이터 세트. 다음 세 가지 데이터 세트에서 제안 된 모델을 평가합니다.
-
크리테오 데이터셋 : 유명한 업계 벤치마킹 데이터 세트입니다. 광고 클릭률을 예측하고 공개적으로 액세스 할 수 있는 모델을 개발합니다. 사용자와 방문한 페이지가 주어지면 목표는 특정 광고에서 사용자가 클릭 할 확률을 예측하는 것입니다.
-
Dianping 데이터셋 : Dianping.com은 중국에서 가장 큰 소비자 리뷰 사이트입니다. 리뷰, 체크인 및 상점의 메타 정보(지리적 메시지 및 상점 속성 포함)와 같은 다양한 기능을 제공합니다. 식당 추천 실험을 위해 6개월의 사용자 체크인 활동을 수집합니다. 사용자의 프로필, 식당의 속성 및 사용자의 마지막 3번의 방문 POI(관심 지점)를 고려하여 식당을 방문 할 확률을 예측하려고 합니다. 사용자의 체크인 인스턴스에있는 각 레스토랑에 대해 POI 인기도에 따라 부정적인 인스턴스로 3 킬로미터 이내에 있는 4 개의 레스토랑을 샘플링합니다.
-
Bing 뉴스 데이터셋 : Bing News2는 Microsoft Bing 검색 엔진의 일부입니다. 실제 상용 데이터 세트에서 모델의 성능을 평가하기 위해 뉴스 읽기 서비스에서 5일 연속 노출 로그를 수집합니다. 첫 3일 동안의 데이터를 훈련 및 검증에 사용하고 다음 2일 동안 테스트에 사용합니다.
- Criteo 데이터 셋과 Dianping 데이터셋의 경우 훈련, 검증 및 테스트를 위해 인스턴스를 8 : 1 : 1로 무작위로 나눕니다.
- 세 가지 데이터 세트의 특성이 표 1에 요약되어 있습니다. 표 1 : 평가 데이터 세트의 통계. M은 백만을 나타내고 K는 천을 나타냅니다
- 4.1.2 평가 지표
- 모델 평가에는 AUC (ROC 곡선 아래 영역)와 Logloss (교차 엔트로피)라는 두 가지 메트릭이 사용됩니다.
- 두 측정 항목은 서로 다른 두 angels의 성능을 평가합니다.
- AUC는 긍정적 인스턴스가 무작위로 선택된 부정적인 인스턴스보다 순위가 높아질 확률을 측정합니다.
- 예측된 인스턴스의 순서만 고려하며 클래스 불균형 문제에는 영향을 받지 않습니다.
- 이와 달리 Logloss는 각 인스턴스의 예측 점수와 실제 레이블 사이의 거리를 측정합니다.
- 때때로 예측 확률을 사용하여 순위 전략 (일반적으로 CTR × 입찰가로 조정)의 이점을 추정해야 하므로 Logloss에 더 의존하는 경우가 있습니다.
- 4.1.3 기준선
- xDeepFM을 LR (logistic regression), FM, DNN (plain deep neural network), PNN (iPNN 및 oPNN에서 더 좋은 것을 선택), Wide & Deep, DCN (Deep & Cross Network)과 DeepFM비교합니다.
- 섹션 2에서 소개하고 논의한 바와 같이, 이 모델은 xDeepFM과 관련이 있으며 일부 모델은 추천 시스템을 위한 최신 모델입니다.
- 기능 상호 작용을 자동으로 학습하는 데 중점을 두고 있으므로 수작업으로 제작된 교차 기능은 포함하지 않습니다.
- 4.1.4 재현성
- Tensorflow를 사용하여 메소드를 구현합니다. 각 모델의 하이퍼 파라미터는 유효성 검사 세트에서 그리드 검색을 통해 조정되며 각 모델에 대한 최상의 설정은 해당 섹션에 표시됩니다.
- 학습 속도는 0.001로 설정됩니다. 최적화 방법을 위해 Minibatch 크기가 4096 인 Adam을 사용합니다.
- DNN, DCN, Wide & Deep, DeepFM 및 xDeepFM의 경우 λ = 0.0001의 L2 정규화를 사용하고 PNN의 경우 Dropout 0.5를 사용합니다.
- 레이어 당 뉴런 수의 기본 설정은 다음과 같습니다.
- (1) DNN 레이어의 경우 400
- (2) Criteo 데이터 세트의 CIN 레이어의 경우 200, Dianping 및 Bing News 데이터 세트의 CIN 레이어의 경우 100
- 신경망 구조에 중점을 두기 때문에 모든 모델에 대한 필드 임베드의 크기를 고정된 값 10으로 설정합니다. 5개의 Tesla K80 GPU와 병렬로 서로 다른 설정을 실험합니다. 소스 코드는 https://github.com/Leavingseason/xDeepFM 에서 확인할 수 있습니다.
4.2. Performance Comparison among
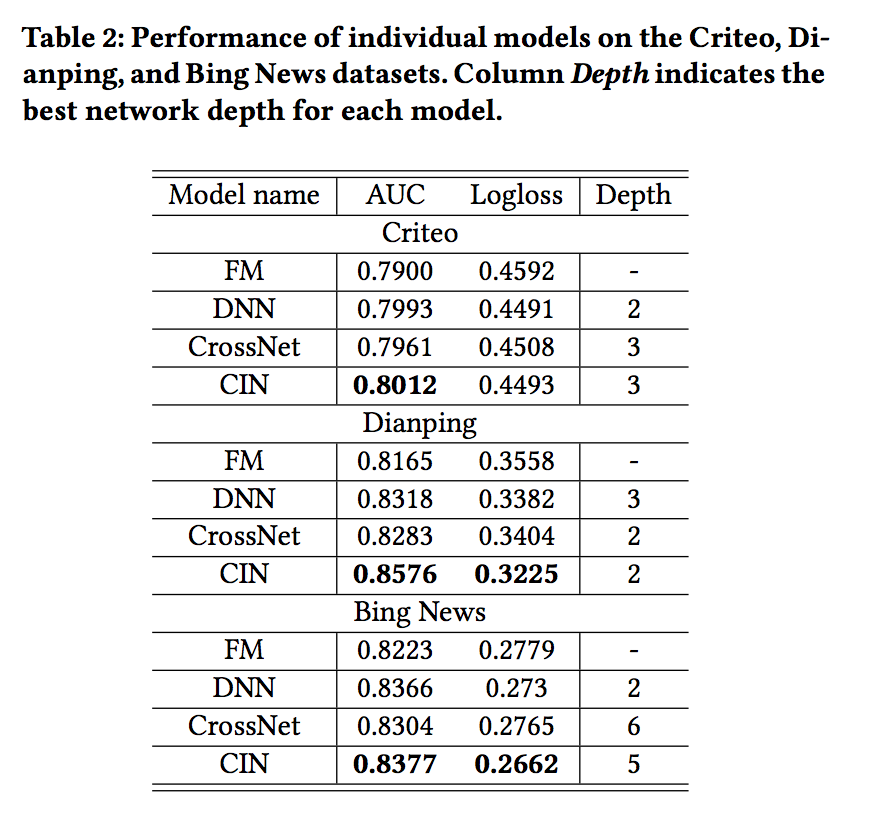
- FM은 2차 기능 상호 작용을 명시적으로 측정하고 DNN 모델 고차 기능 상호 작용을 암시적으로 측정하고, CrossNet은 소수의 매개 변수를 사용하여 고차 기능 상호 작용을 모델링하려고 시도하고 CIN은 명시적으로 고차 기능 상호 작용을 모델링합니다
- 실제로 데이터 세트에 의존하기 때문에 하나의 개별 모델이 다른 모델보다 우수하다는 이론적 보증은 없습니다.
- 실제 데이터 세트는 상위 기능의 상호 작용을 필요로 하지 않는 경우에는 예를 들어, FM은 최고의 개별 모델이 될 수 있습니다.
- 따라서 이 실험에서 어떤 모델이 가장 성능이 좋을지 기대하지 않습니다. 표 2는 세 가지 실제 데이터 세트에 대한 개별 모델의 결과를 보여줍니다.
- 놀랍게도 CIN은 다른 모델보다 일관되게 성능이 뛰어납니다.
- 한편, 결과는 실제 데이터 세트의 경우 스파스 기능에 대한 고차 상호 작용이 필요하다는 것을 나타내며 DNN, CrossNet 및 CIN이 세 데이터 세트 모두에서 FM을 능가한다는 사실을 통해 확인할 수 있습니다.
- 반면에 CIN은 최상의 개별 모델 상호 작용을 모델링 할 때 CIN의 효과를 보여주는 최고의 개별 모델입니다.
- k-layer CIN은 k-degree 특징 상호 작용을 모델링 할 수 있습니다.
- CIN이 Bing News 데이터 세트에서 최상의 결과를 얻기 위해서는 5 개의 레이어가 필요하다는 것도 흥미롭습니다.
4.3. Performance of Integrated Models (Q2)
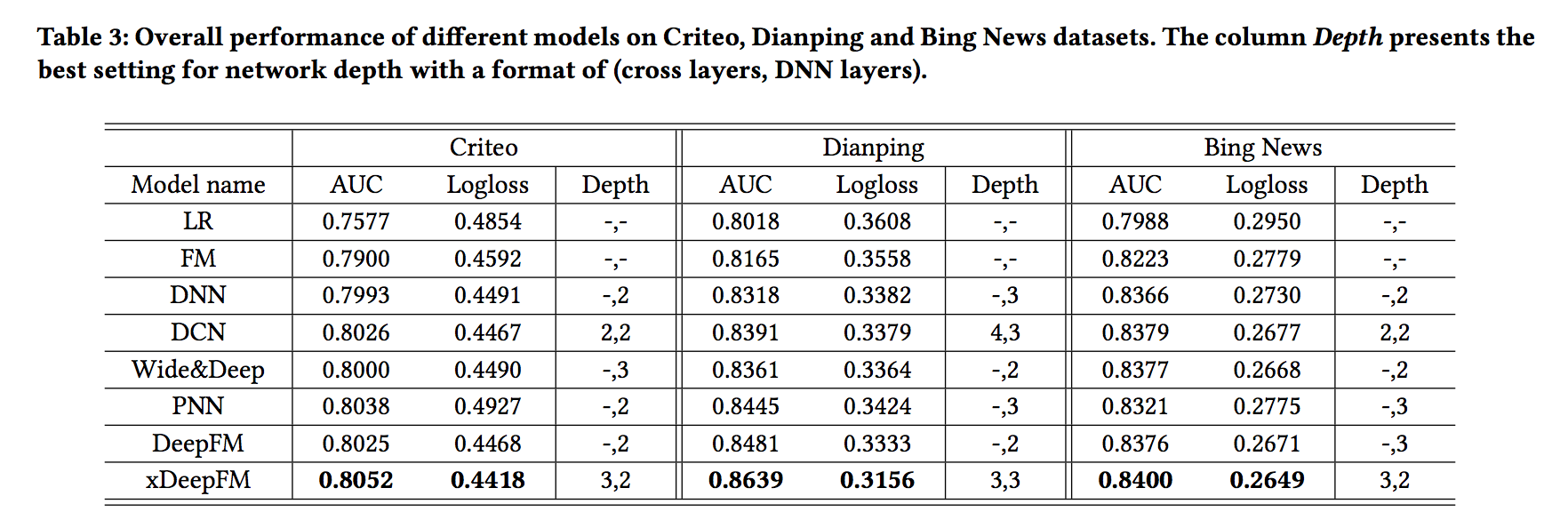
- xDeepFM은 CIN과 DNN을 End to End 모델로 통합합니다.
- CIN과 DNN은 학습 기능 상호 작용의 두 가지 고유한 속성을 다루며, 함께 명시적이고 암시적인 학습을 위해 이들을 함께 결합하는 것이 실제로 필요한지 여부에 관심이 있습니다.
- 개별 모델에 국한되지 않는 몇 가지 강력한 기준을 비교하고 그 결과를 표 3에 표시합니다.
- LR이 나머지 모델보다 훨씬 나쁘다는 것을 알 수 있습니다.
- FM 기반 모델이 희소 피쳐를 측정하는 데 필수적이라는 것을 보여줍니다.
- Wide & Deep, DCN, DeepFM 및 xDeepFM은 DNN보다 훨씬 뛰어납니다.
- 단순성에도 불구하고 하이브리드 구성 요소를 통합하는 것이 예측 시스템의 정확성을 높이는 데 중요하다는 것을 직접적으로 반영합니다.
- 제안된 xDeepFM은 모든 데이터 세트에서 최상의 성능을 달성합니다.
- 명시적 및 암묵적 고차 기능 상호 작용을 결합해야하며 xDeepFM이 이러한 클래스의 조합을 학습하는 데 효과적임을 보여줍니다.
- 또 다른 흥미로운 관찰은 모든 신경망 기반 모델이 최상의 성능을 위해 매우 깊은 네트워크 구조를 요구하지 않는다는 것입니다.
- 깊이 하이퍼 파라미터의 일반적인 설정은 2와 3이며 xDeepFM의 최상의 깊이 설정은 3입니다. 학습한 상호 작용이 최대 4 차임을 나타냅니다.
4.4. Hyper-Parameter Study (Q3)
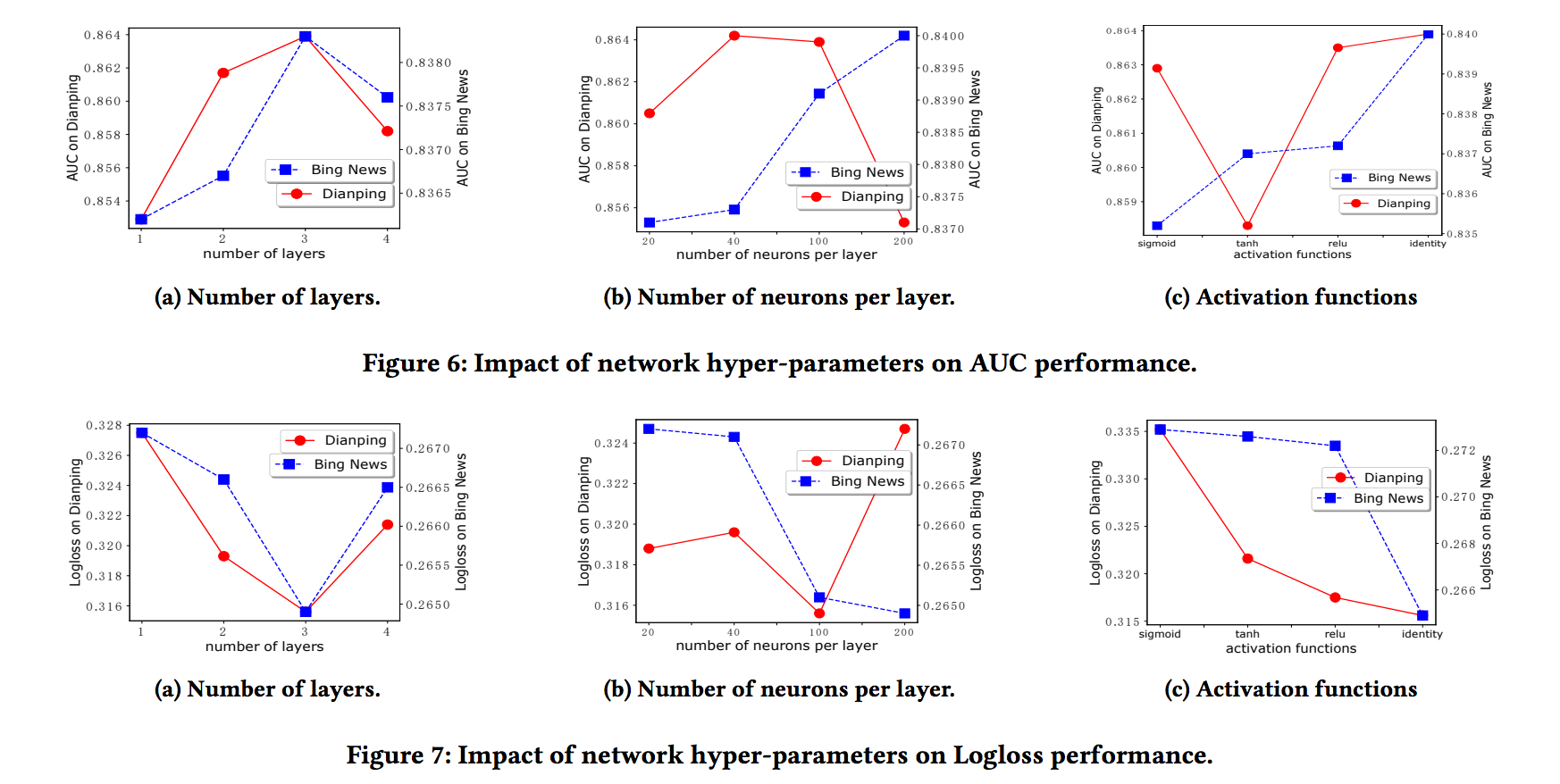
- 이 섹션에서 (1) 숨겨진 레이어의 수를 포함하여 xDeepFM에 대한 하이퍼 파라미터의 영향을 연구합니다. (2) 층당 뉴런의 수; 및 (3) 활성화 기능.
- CIN 파트의 설정을 변경하면서 DNN 파트에 대한 최상의 설정을 유지하여 실험을 수행합니다. (네트워크 Depth)
- 그림 6a 및 7a는 숨겨진 계층 수의 영향을 보여줍니다.
- xDeepFM의 성능은 처음에 네트워크 깊이에 따라 증가한다는 것을 알 수 있습니다.
- 그러나 네트워크 깊이가 3보다 크게 설정되면 모델 성능이 저하됩니다. 숨겨진 계층을 더 추가 할 때 훈련 데이터 손실이 계속 감소한다는 사실을 알 수있는 과적합으로 인해 발생합니다.
- 레이어 당 뉴런 수를 추가하면 CIN의 기능 맵 수가 증가합니다.
- 그림 6b 및 7b에서 볼 수 있듯이 Bing News 데이터 세트의 모델 성능은 뉴런 수를 20에서 200으로 늘릴 때 꾸준히 증가하는 반면 Dianping 데이터 세트에서는 100이 레이어 당 뉴런 수에 더 적합한 설정입니다. 이 실험에서 우리는 네트워크의 깊이를 3으로 고정시킵니다.
- 식 (Eq.)에 나타난 바와 같이 CIN의 뉴런에서 활성화 기능으로서의 정체성을 이용한다는 것에 주목한다.
- 딥러닝 문헌의 일반적인 관행은 숨겨진 뉴런에 비선형 활성화 기능을 사용하는 것입니다.
- 따라서 CIN에서 다른 활성화 기능의 결과를 비교합니다 (DNN의 뉴런의 경우 활성화 기능을 relu로 유지함) 식별 기능은 실제로 CIN의 뉴런에 가장 적합한 기능이다.
5. RELATED WORK
5.1. Classical Recommender Systems
- 5.1.1 Non-factorization Models
- 웹 규모 추천 시스템 (RS)의 경우 입력 기능은 일반적으로 희소, 범주 연속 혼합 및 고차원입니다.
- FTRL을 사용한 로지스틱 회귀와 같은 선형 모델은 관리, 유지 관리 및 배포가 용이하므로 널리 채택됩니다.
- 선형 모델은 피처 상호 작용을 자동으로 학습할 수 있는 능력이 없기 때문에 데이터 과학자는 더 나은 성능을 달성하기 위해 교차 피처 엔지니어링에 많은 노력을 기울여야합니다.
- 일부 숨겨진 기능은 수동으로 설계하기가 어렵다는 점을 고려하여 일부 의사 결정 기능을 활용하여 기능 변환을 구축 할 수 있습니다.
- 5.1.2 Factorization Models
- 앞에서 언급한 모델의 주요 단점은 트레이닝 세트에서 보이지 않는 기능 상호 작용을 일반화 할 수 없다는 것
- FM는 각 특징을 낮은 차원의 잠재 벡터에 삽입함으로써이 문제를 극복합니다.
- ID를 특징으로 고려하는 MF (Matrix Factorization)는 특별한 종류의 FM으로 간주 될 수 있습니다.
- 두 개의 잠복 벡터의 곱을 통해 추천 사항이 있으므로 훈련 세트에서 사용자와 항목의 동시 발생이 필요하지 않습니다.
- MF는 RS 문헌에서 가장 인기있는 모델 기반 협업 필터링 방법입니다. 선형 모델과 MF 모델이 모두 포함된 부가 정보를 활용하여 MF를 확장한다.
- 반면 많은 추천 시스템의 경우 사용자의 시청 기록 및 탐색 활동과 같은 암시적 피드백 데이터 집합만 사용할 수 있습니다.
- 따라서 연구자들은 암시적 피드백을 위해 인수 분해 모델을 BPR (Bayesian Personalized Ranking) 프레임 워크로 확장했다.
5.2. Recommender Systems with Deep Learning
-
딥러닝 기술은 컴퓨터 비전, 음성 인식 및 자연어 이해에서 큰 성공을 거두었습니다. 결과적으로, 점점 더 많은 연구자들이 추천 시스템에 DNN을 사용하는 데 관심이 있습니다.
- 5.2.1 Deep Learning for High-Order Interactions
- 고차 교차 피쳐를 수동으로 구축하는 것을 피하기 위해 연구원은 필드 임베딩에 DNN을 적용하므로 범주형 피쳐 상호 작용의 패턴을 자동으로 학습할 수 있습니다.
- 대표 모델에는 FNN, PNN, DeepCross, NFM, DCN, Wide & Deep 및 DeepFM가 있습니다.
- 이 모델은 제안 된 xDeepFM과 관련이 있습니다. 섹션 1과 섹션 2에서 검토 했으므로 이 섹션에서 자세히 설명하지 않습니다.
- 제안된 xDeepFM이이 모델들과 비교하여 두 가지 특별한 속성을 가지고 있음을 증명했습니다 : (1) xDeepFM은 명시적 및 암시적 방식으로 고차적 특징 상호 작용을 학습합니다. (2) xDeepFM은 비트 단위가 아닌 벡터 단위의 기능 상호 작용을 학습합니다.
- 5.2.2 Deep Learning for Elaborate Representation Learning
- 이 섹션에는 학습 기능 상호 작용에 덜 중점을 두기 때문에 다른 딥 러닝 기반 RS가 포함됩니다.
- 일부 초기 작업에서는 주로 시각 데이터 및 오디오 데이터와 같은 보조 정보를 모델링하기 위해 딥러닝을 사용합니다. 최근에는 심층 신경망이 협업 필터링을 모델링하는 데 사용됩니다.
- RS의 (CF)은 MF의 내부 제품이 신경망 구조를 통해 임의의 기능으로 대체될 수 있도록 NCF (Neural Collaborative Filtering)를 제안한다.
- autoencoder 패러다임에 기초한 CF 모델이며, autoencoder 기반 CF가 몇가지 고전적인 MF 모델보다 성능이 우수하다는 사실을 실험적으로 입증했습니다.
- autoencoder는 더 나은 잠재적 인자를 생성할 목적으로 CF와 부가 정보를 공동으로 모델링하기 위해 추가로 사용될 수 있습니다.
- 신경망을 사용하여 여러 도메인의 잠재 요인을 공동으로 훈련시킵니다. 항목 수준과 구성 요소 수준 모두에서보다 정교한 선호도를 배우기 위한 ACF (Attentive Collaborative Filtering)를 제안합니다.
- 전통적인 RS가 관심 다양성과 지역 활성화를 효과적으로 포착할 수 없기 때문에 주의 깊은 활성화 메커니즘으로 사용자의 다양한 관심사를 나타내는 깊은 관심 네트워크 (DIN)를 소개합니다.
6. CONCLUSIONS
- 본 논문에서는 고차원적 특징 상호 작용을 명시적으로 배우는 것을 목표로 하는 Compressed Interaction Network(CIN)라는 새로운 네트워크를 제안한다.
- CIN에는 두 가지 특별한 장점이 있습니다.
- (1) 특정 범위-도 기능 상호 작용을 효과적으로 학습할 수 있습니다.
- (2) 벡터 상호 작용 수준에서 기능 상호 작용을 학습합니다.
- 몇 가지 인기있는 모델에 따라 CIN과 DNN을 End-to-End 프레임 워크에 통합하고 결과 모델 eXtreme Deep Factorization Machine (xDeepFM)을 명명했습니다.
- 따라서 xDeepFM은 명시적 및 암시적 방식으로 고차원 피쳐 상호 작용을 자동으로 학습할 수 있으므로 수동 피쳐 엔지니어링 작업을 줄이는 데 큰 의미가 있습니다.
- 포괄적인 실험을 수행한 결과 xDeepFM이 3개의 실제 데이터 세트에서 최신 모델보다 일관되게 성능이 우수함을 보여줍니다.
- 향후 작업에는 두 가지 방향이 있습니다.
- 첫째, 현재 우리는 단순히 multivalent 필드를 포함하기 위해 합계 풀링을 사용합니다. 후보 항목에 따라 관련 활성화를 캡처하기 위해 DIN 메커니즘의 사용법을 살펴볼 수 있습니다.
- 둘째, 3.2.2 절에서 논의 된 바와 같이 CIN 모듈의 시간 복잡도는 높다. GPU 클러스터에서 효율적으로 학습할 수 있는 xDeepFM의 분산 버전을 개발하는 데 관심이 있습니다.



댓글남기기