
코드 원본 및 참고 자료
0. Abstraction
- 유사 유저(look-alike audience) 확장은 온라인 광고에서 고성능 잠재 고객(high performance audience)를 맞춤 설정할 수 있는 실질적으로 효과적인 방법임.
- 유사 유저 확장 시스템을 사용하면 광고주들은 정교한 광고 시스템에서 세부적으로 타겟팅 가능한 속성을 몰라도 기존 고객 목록을 제공함을서 맞춤형 고객층을 쉽게 생성할 수 있음.
- 이 논문에서는 유사 유저에게 수천개의 캠페인을 제공하는 야후의 광고 플랫폼의 새롭게 개발된 그래프 기반의 유사 유저 시스템을 다룸.
- 기존의 세가지의 다른 유사 유저 시스템들과 비교하기 위한 실험이 이루어짐.
- 실험 결과에 따르면 최근접 이웃 필터링(nearest-neighbor filtering)한 그래프 기반 방법이 앱 설치 광고 캠페인의 전환율에서 다른 방법보다 50% 이상 성능이 뛰어남.
1. Introduction
- 온라인 광고 캠페인에서 유사 유저 모델을 사용하면 광고주가 기존의 고객과 유사한 유저에게 도달할 수 있음.
- 이전 구매자 목록, 웹 서비스 구독자, 특정 앱 설치 프로그램, 브랜드 애호가, CRM 시스템 고객, 광고 클릭자, 특정 정치인 지지자, 스포츠 팀의 팬 등과 유사한 유저를 타겟팅하는 것과 같은 비지니스 목표를 서포트하는데 사용되어짐.
- 유사 유저 확장 기술의 장점은 온라인 광고의 다른 타겟팅 기술과 비교하였을 때 매우 관련있는 고객들에게 도달할 수 있는 방법을 대폭 단순화하였다는 것임.
- 광고주는 사용자 목록을 업로드하여 커스터마이즈된 오디언스(audience)를 사용
- 유사 유저 시스템의 인풋은 사용자 ID(예 : 브라우저 쿠키, 주소, 전화번호, 똔느 기타 식별자 목록) 리스트으로 시드(‘SEEDS’)라고 부름.
- 시드 사용자들은 지난 광고 캠페인 또는 더 강력한 구매력을 지닌 기존 고객으로 변환되어질 수 있음.
- 아웃풋은 유사 유저 모델에 따라 시드와 유사하게 보이는 사용자의 목록임.
- 유사 유저의 효과는 여러 비즈니스 관점에서 측정됨.
- 확장성(Scalability)
- 유사 유저 아웃풋의 최대 사이즈는 얼마인지?
- 합리적인 규모의 유저를 도출할 수 있는 상한과 하한은 얼마인지?
- 성능(Performance)
- 광고주가 시드 목록을 업로드한 후 시스템이 유사 유저를 얼마나 빠르게 생성할 수 있는지?
- 실제 광고 캠페인에서 유사 유저가 달성할 수 있는 ROI 상승도는 얼마인지?
- 투명성(Transparency)
- 시스템이 블랙박스로 작동하는지?
- 아니면 광고 캠페인 설정 중에 피드백과 인사이트를 얼마나 빨리 생성할 수 있는지?
- 몇 초 또는 며칠 안에 피드백과 인사이트를 생성할 수 있는지?
- 확장성(Scalability)
- 다시 말해 모델의 확장성, 성능, 투명성에 대해서 서로 다른 요구 사항이 주어졌을 때 유사유저 확장 시스템의 유일한 ‘최상’의 설계는 없음. 야후의 시스템의 주요한 기여는 다음과 같이 요약 가능함.
- 유사유저의 쿼리 시간이 쿼리 유저 수의 부분 선형(sub-linear)인 야후의 대규모 유사 유저 확장 시스템을 제시함. 유사 유저 시스템의 코어 모델은 user2user 쌍별 유사도들에 대한 그래프 마이닝과 머신러닝 기술에 기반하고 있음. 이 시스템에서는 4시간 이내에 30억명 이상의 사용자에게 3000개 이상의 캠페인을 할당할 수 있음.
- 실제 앱 설치 캠페인 데이터를 사용한 광범위한 실험을 통해 야후의 방법에 의해 추천된 유사 유저가 기존의 다른 유사 유저 모델보다 앱 설치율을 50% 이상 높였음.
- 또한, 대규모 유사 유저 시스템을 개발하는데 있어 경험을 논의 하거나 어려움을 토론할 수 있음. 가중된 user2user 유사도 그래프를 사용하여 앱설치율은 11% 더 향상시킬 수 있음을 증명함.
2. Existing Look-alike Methods & Systems
- 두 사용자 간의 유사성은 그들의 feature들에 의해 만들어짐.
- 한 유저 는 feature vector 로 특성화될 수 있음.
- 온라인 광고 시스템에서 각각의 feature 는 연속적(예: 특정 사이트에서 보낸 시간)이거나 또는 (거의 대부분의 경우) 범주 또는 이진형(예: 특정 모바일 앱 사용여부)임.
- feature는 유저의 속성, 사화적인 상호작용, 사전 구축된 잠재고객 세그먼트 등으로 부터 올 수 있음.
- 회사마다 비지니스와 사용자에 이해를 바탕으로 다른 feature를 사용하여 유저를 나타냄.
- feature vector의 크기는 수천~수백만까지 다양함
- 이 논문에서는 과 필요하다면 여러 이진 feature로 분류할 수 있는 연속적인 feature들이 고려됨.
- 비지니스 motivation은 간단하고 직선적이지만 유사 유저 모델링의 사전 작업이 상당히 부족하다는 Shen et al. (2015)의 견해에 동의함.
- 우리가 아는 한 유사 유저는 시스템은 온라인에서 사용되고 있음.
- 광고 산업은 세 가지 범주로 분류할 수 있음 : 단순한 유사도 기반 모델, 회귀 기반 모델, 세그먼드 추정 기반 모델
2.1 Simple Similarity-based Look-alike System
- 유사 유저를 찾는 간단한 방법은 시스템에서 모든 시드 사용자와 사용 가능한 쌍을 비교한 다음 거리(유사도) 측정에 따라 유사성을 결정하는 것
- 단순한 유사도 기반 유사 유저 시스템은 user2user 유사도를 사용하여 시드처럼 보이는 유저를 찾을 수 있음.
- 두 사용자 와 의 유사성은 feature vector 에 따라 정의됨.
- 코사인 유사도(연속 feature의 경우, 식 1)와 자카드 유사도(이진 feature의 경우, 식2)는 가능한 두가지 측정값임.

- seed 유저 set 와 주어진 유저 (feature vector ) 간의 유사도는 시드 유저로부터 가장 유사한 유저의 유사도로 계산되어질 수 있음.
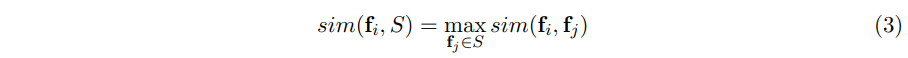
- 보다 복잡한 방법은 user2user 유사도를 확률적으로 집계하는 것임.
- 이 방법은 0과 1 사이에서 엄격하게 제한된 user2user 유사도들에 대해서만 작동함.
- 쌍 유사도는 유사한 결정을 촉발할 확률로 다루어짐.
- 따라서 유저와 시드셋의 유사도는 다음과 같이 측정될 수 있음
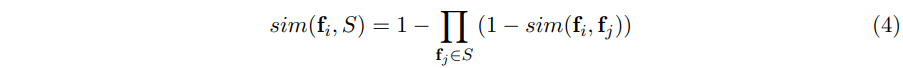
- 유사도 기반 방법은 소규모로 쉽게 구현할 수 있음.
- 사용자 feature space에 있는 모든 시드가 보유한 정보를 활용할 수 있는 이점이 있음.
- 그러나 이 방법에는 몇가지 주의 사항이 있음
- 첫번째는 확장성으로 많은 수의 사용자 간의 쌍별 유사도를 계산하는 것이 어려움. 무차별하게 대입하는 방법은 N명의 후보자와 k개의 feature를 갖는 M 시드에 대해 계산 복잡도 $O(kMN)$. 일반적인 온라인 광고 시장에서는 수십억명의 후보자와 사용자 당 수백 feature를 가진 수만 명의 씨드가 있음.
- 두번째 주의 사항은 시드 사용자의 다른 feature들이 동일하게 다루어지기 때문에 (유사도 기반) 모델은 가장 관련이 높은 후보자를 식별하는 능력이 구별되지 않는 것임. 예를 들어 광고 클릭 또는 전환에 대한 예측 능력은 고려되지 않음. 그래서 덜 중요한 후보자가 덜 중요한 feature의 유사도로 인해 유사 유저로 간주될 수 있음.
2.2 Regression-based Look-alike System
- 온라인광고를 위한 또 다른 유형의 유사 유저 시스템은 Qu et al. (2014) 로지스틱 회귀에 의한 것임.
- 특정 벡터 를 가진 주어진 사용자 의 경우 로지스틱 회귀 모델을 학습하고 다음과 같이 시드와 유사할 확률을 모델링할 수 있음.
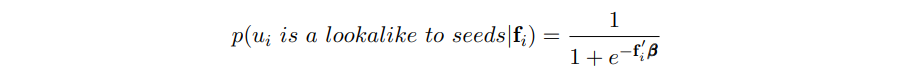
- 시드는 일반적으로 긍정적인 예로 취급됨.
- 반면 부정적인 예를 선택하는 몇가지 옵션이 있음.
- 가장 간단한 네거티브 예제 세트는 비 시드 사용자의 샘플일 수 있음.
- 잠재적인 광고 변환기가 비 시드 사용자에게도 포함될 수 있으므로 최선의 선택이 아님.
- 다른 선택은 광고 서버 로그를 처리하여 과거에 광고주의 광고를 보았지만 전환되지 않은 사용자를 찾는 것임.
- 그러난 콜드 스타트 문제로 어려움을 겪고 있음. 시드가 새로운 광고주의 것이구나 새로운 광고 캠페인에 사용될 경우 광고를 본 사용자가 없음.
- 피처의 수가 많은 경우 최종 모델에서 0이 아닌 값의 수를 줄이기 위해 L1 정규화를 손실 함수에 적용하여 피처를 선택함.
- 실제로 Vowpal Wabbit와 같은 기계학습 패키지는 하둡 클러스터에서 대규모로 로지스틱 회귀를 훈련하고 대규모 사용자에게 이러한 확률을 예측할 수 있는 유연하고 확장 가능한 솔루션을 제공함.
- 이 모델링 방법의 장점은 시드에 의해 전달된 정보가 모델로 압축되고 사용자를 닮은 모양으로 평가하기 위해 시드의 특징 벡터를 기억할 필요가 없음.
- 큰 이점 외에 회귀 모델링 방법을 유사 유저 문제에 적용할 경우 몇가지 주의 사항이 있음.
- LR은 많은 연결, 교차, 또는 기타 종속성을 feature에 포함시킬 수 있는 선형 모델이지만 사용자들을 클러스터링하는데는 효율적이지 않을 수 있음.
- 제안된 시스템과 비교하기 위해 LR 기반 유사 유저 시스템을 구현함.
2.3 Segment Approximation-based Look-alike System
- 다른 유형의 유사 유저는 사용자 세그먼트에 기초하며, 여기서 사용자 세그먼트는 사용자 관심 카테고리와 같이 사용자의 특성일 수 있음.
- 예를들어 사용자가 NBA 게임을 좋아하는 경우 이 사용자는 스포츠 세그먼트에 속하는 것으로 간주됨.
- 다른 방법과 비교하여, 세그먼트 근사 기반 시스템은 사전 구축된 사용자 세그먼트를 사용자의 feature로 사용함.
- 세그먼트 근사 기반 방법의 아이디어는 가능한 많은 시드 사용자가 공유한 최상위 세그먼트를 찾는 것임.
- 여기서는 Turn Inc, Shen et al.(2015)의 가장 최근 발표된 세그먼트 근사 기반 방법 중 하나를 설명함.
- 그들의 접근 방식에서는 각 사용자는 의 세그먼트츠의 bag으로 표시됨.
- 유사 유저 확장에 대한 최적화 목표는 광고주가 제공한 세그먼트 셋 C(시드 사용자에 표시된 세그먼트)를 고려할 때 다음 세가지 특성을 만족한 세그먼트 셋이 인 신규 사용자를 추천하는 것임.
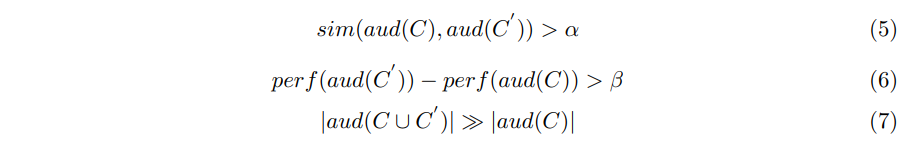
- 여기서 는 C에 세그먼트가 있는 오디언스 셋이고, 는 의 클릭률과 전환율에 따른 성능을 의미함.
- 직관적으로 아래와 같은 의미임
- (1) 확장된 오디언스 셋 는 시드 오디언스 의 충분히 유사함(유저가 겹친다는 관점에서)
- (2) 확장된 오디언스 셋 은 시드 오디언스 와 비교해 더 좋아야 함.
- (3) 확장된 오디언스 셋 의 크기는 시드 오디언스 보다 훨씬 커야 함.
- 위의 속성을 만족하는 세그먼트가 여러 개 있을 수 있으므로 세그먼트의 중요성을 구별하기 위한 스코어링 기능이 필요함.
- Shen et al. (2015) 은 셋 커버 알고리즘의 적용인 그리디 방법과 가중 criteria에 기반한 알고리즘을 논의함.
- 새로 추천된 카테고리(or 세그먼트) 갱신에 대해 위의 세가지 기능(수식 5,6,7)을 결합하여 점수를 계산함.
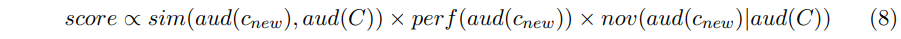
- 사전 구축된 세그먼트의 품질이 높고 적용 범위가 좋은 경우 세그먼트 근사가 잘 작동함.
- 특히 대규모 브랜딩 광고주의 경우에 잘 작동하고, 소규모 광고주에는 유용하지 않을 수 있음.
- 사전 빌드 프로세스에서는 유사 유저 생성을 지연시킬 수 있는 또 다른 계산 파이프라인이 도입되었음.
- 대규모 비교를 위한 또 다른 방법으로 위에서 설명한 알고리즘을 구현함.
3. Graph-Constraint Look-Alike System
- 이 섹션에서는 단순 유사성과 회귀 기반 방법을 장점을 모두 활용할 수 있도록 그래프 제약 유사 유저 시스템의 세부 정보를 제공함.
- 먼저, 전역 user2user 유사도 그래프를 구축되어 후보 유저를 가장 가까운 시드의 이웃으로 제한할 수 있음.
- 그런 다음 후보 유저는 광고 캠페인의 관련된 기능의 중요성에 따라 순위가 결정
- 모든 사용자에 대해 광고 캠페인 당 유사 잠재 고객을 교육하고 점수를 매기는 것은 효율성이 낮은 프로세스임.
- 일반적으로 비슷한 오디언스의 규모는 백만~천만이며, 이는 10억 사용자 풀에서 0.1%~1%임.
- 관련없는 사용자를 많이 계산하면 많은 양의 계산 리소스가 낭비됨.
- 또한 관련없는 99%의 사용자에 대한 feature 가중치를 얻는 훈련을 유저를 샘플링하는 어려운 문제에 직면함.
- 그래서 글로벌 그래프 구성과 캠페인별 모델링 두 단계로 유사유저를 생성하는 것을 제안함.
3.1. Phase I: Global Graph Construction
- 이 단계에서 시스템에서 가능한 모든 유저에 대해서 uesr2user 유사성 그래프가 작성되며, 두 사용자 사이의 edge는 자카드 유사도(식 2)를 나타냅니다.
- 목표는 이 글로벌 그래프를 사용하여 특정 시드의 유사 유저 후보자들을 찾는 것임.
- 우리의 접근 방식의 핵심 공식은 다음과 같이 정의된 쌍별 가중된 user2user 유사도임.
- 는 유저 와 의 feature vector
- 가중치 행렬 는 개별 feature와 쌍별 feature들의 결합 둘 다에 대한 선형 상관 관계의 중요성을 통합함.
- 예를 들어 가중 행렬 가 대각행렬(diagonal)면 쌍별 가중된 user2user 유사도는 가중된 코사인 유사도임. 비대각 행렬 는
- 고차 feature 조합들은 거대한 sparse feature 공간에서 거의 유용하게 관찰되지 않음.
- 따라서, feature modeling은 유사 유저 시스템을 over-engineering 하지 않도록 개별과 쌍별 feature로만 제한됨.
- 가중치 매트릭스의 규모는 전체 유저 수와 비교하였을 때 상대적으로 작은 feature의 수에 의해 결정됨.
- 이 속성을 사용하면 각 광고 캠페인에 대해 특정 가중치 행렬을 구축하여 feature를 더 많이 튜닝할 수 있음.
- 글로벌 user2user 유사성 그래프를 구축하는데 어려움은 사용자 쌍별 유사도 계산()과 유사한 사용자 쿼리()의 높은 시간 복잡도에 있음.
- 이러한 어려움을 해결하기 위해 우리는 잘 알려지는 LSH를 사용하여 한 번에 사용자 데이터를 읽어 비슷한 사용자를 동일한 클러스터에 배치하고 부분 선형 시간으로 유사 유저 쿼리를 가능하게 함.
3.1.1 MinHash Locality Sensitive Hashing (LSH)
- Rajaraman et al. (2012)의 LSH를 사용하면 각 유저는 두 단계로 한번에 처리됨.
- 첫번째 단계는 일련의 해시 함수를 사용하여 feature vector를 원래 사용자의 feature보다 훨씬 적은 양의 값으로 구성되는 similaritypreserving signature로 변환함.
- 그런 다음 두번째 단계는 이 signature를 기반으로 유저를 클러스터에 할당함.
- signature 값은 그룹화된 확률로 서로 유사한(사전 정의된 유사도 임계값을 사용함으로써) 유저 클러스터를 사용하도록 그룹화됨.
- 주어진 input 유저에게 쿼리한 그 때 유저를 해시하여 속하는 클러스터를 찾을 수 있으며 해당 클러스터의 사용자가 유사 유저가 됨.
- 클러스터 구성 및 유사 유저 검색은 쌍별 유저 조작 없이 유저별에 기반한 프로세스임.
- 따라서 LSH는 단순 유사성 기반 유사 유저 시스템을 크게 단순화함.
- 아래에서는 MinHash LSH의 예로 두 단계의 디테일을 설명함.
MinHash.
- LSH에서는 해싱 테크닉을 사용하여 유저 feature space를 줄이면서 원래의 유사도를 높은 확률로 유지함.
- 코사인 유사도를 근사하기 위해 random projection을 사용하고, 자카드 유사도를 근사하기 위해 Min-Hash를 사용하는 등 다양한 해싱 방식을 적용할 수 있음.
- 이 경우 유저의 자카드 유사도는 binary feature로 계산되기 때문에 MinHash가 사용됨.
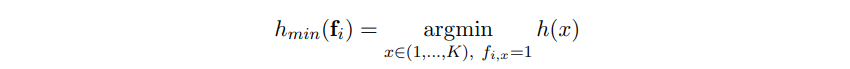
- 는 차원의 유저의 feature vector
- 는 feature들의 index
- 해시 함수 는 feature의 index를 난수로 매핑함.
- 는 최소 해시 값을 갖는 feature index로 정의함.
- 는 해시 signature
- MinHash가 자카드 유사도를 유지하는 것이 증명되어 있음(Rajaraman et al. (2012)의 3 장 참조)
- 이는 두 유저 간의 동일한 Minhash 값을 가질 확률이 자카드 유사도와 동일함을 의미함
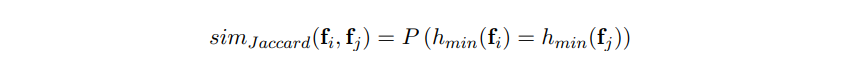
- 다시 말해, 두 유저의 자카드 유사도가 이면, MinHash 함수 H의 총 합은 두 유저가 독립적으로 해시되는데 사용됨.
- 그러면 두 유저간의 signature는 동일할 것임.
LSH
- MinHash 함수 H에 의해 생성된 sinature는 H차원 벡터를 형성함.
- 모든 명의 유저에 대한 signature는 Rajaraman et al. (2012)의 signature 행렬로 알려진 NXH 행렬로 되어있음.
- 이기 때문에 signature 행렬은 HXK의 행렬의 raw 유저 feature 행렬로 볼 수 있음.
- %%H$$ 차원 signature를 사용하여 LSH 방법은 검색 목적을 위한 버킷으로 유사 유저를 클러스터링하는 다양하고 유연한 방법을 제공함.
- 가장 보편적인 방법은 ‘AND-OR’ 스키마이며, 여기서 signature 차원이 b 밴드들로 분할됨.
- 각 밴드는 r signature 차원으로 구성되며, 여기서 임.
- 유저는 밴드 내에서 동일한 r차원 signature가 있는 경우에만 동일한 버킷으로 클러스터됨.
- 유저는 밴드에서 하나의 버킷에만 속할 수 있고, 각 유저에게는 총 b개의 버킷이 있음.
- 시드 사용자가 속하는 버킷 라는 버킷에 속하는 모든 유저는 전체 유저 모집단과 비교하여 적은 양의 유사 유저 후보로 검색됨.
- 검색된 후보 유저는 필요한 경우 정확한 순위를 매길 수 있음.
-
b 및 r의 값은 일반적으로 적용되는 데이터 유사도 분포와 원하는 item2item 유사도 기준에 근거하여 경험적으로 결정됨.
- 위에서 소개한 LSH 기술을 사용하여 시스템 구현의 복잡성을 줄일 수 있음.
- MinHash LSH를 수행한 후 각 유저 는 hash signature로 생성된 버킷 ID 목록이 있음.
- 모든 시드의 hash signature를 조회하고 유사 유저를 글로벌 그래프에서 가져와서 캠페인의 유사 유저 후보를 생성할 수 있음.
- 적당한 크기의 후보자들은 최종 유사 유저의 5배~10배까지 다양함.
- 너무 작은 후보 세트 목록은 유사 유저를 놓칠 수 있음.
- 후보 세트가 너무 크면 2단계에서 계산 비용이 증가함.
- 그래프에서 가져온 후보 유저가 적은 경우(예: 소량의 시드로 인해) 회귀 또는 세그먼트 근사 기반 방법을 통해 원하는 크기의 유사 유저를 확보할 수 있음.
- 이 논문에서는 충분한 수의 후보(예 : 천만명 이상)을 가져올 수 있는 경우만을 고려했음.
3.2 Phase II: Campaign Specific Modeling
- 이 단계에서의 목표는 간단한 캠페인별 모델을 학습하고 1단계의 오디언스를 정제하는 것임.
- 후보들은 캠페인별 feature 가중치로 계산되고 순위가 가장 높은 사용자가 최종 유사 유저가 됨.
- 다른 광고 캠페인들은 다른 유저의 feature들에 관심을 가질 수 있음.
- 소매점의 광고 캠페인은 교육보다는 사용자의 위치에 더 관심을 가질 수 있음.
- 보험 광고 캠페인은 소셜 상태보다 사용자의 재무상태를 더 중요하게 생각함.
- 광고 캠페인에 최적화된 weight 행렬(식 9)은 관련없는 feature들은 무시하고 광고 ROI를 높일 수 있는 유사 유저를 생성하는데 도움이 됨.
- 직관적으로 관련 feature들은 시드를 다른 유저와 구별할 수 있는 더 많은 변별력을 가져야함.
- feature 선택, feature 순위 지정 및 레이블이 지정된 데이터 모델링을 위해 다양한 정형화된 방법과 알고리즘이 있음.
- 인기 있는 것은 예를 들면 로지스틱 회귀(정규화 사용)와 의사결정트리처럼 간단한 feature 선택과 선형 모델임.
- 여기서는 간단한 방법이 매우 효율적으로 실행될 수 있고 반복적이지 않은 feature 선택 방법이기 때문에 간단한 feature 선택 방법을 예로 들어 설명함.
- 또한 선형 모델과 다른 복잡한 방법과 비교하여 sparse한 유저의 feature space에서 상당히 우수한 성능을 제공함.
- 그러나 계산 비용과 응답시간이 bottlenck이 아니라면 다른 방법을 사용하는 게 더 좋음.
- 간단한 feature 선택 방법은 diagonal 가중 행렬 를 계산함.
- 는
- 는 user와 비교한 셋 와 시드 셋 으로부터 계산된 feature 의 중요성임.



댓글남기기