
Abstract
- sequence-to-sequence 모델(이하 seq-to-seq 모델)은 다양한 task에 대한 인상적인 결과를 얻었음
- 그러나 많은 데이터가 모델에 입력되거나 긴 입력 시퀀스와 출력 시퀀스가 있는 작업이 증가하는 경우, 점진적 예측을 필요로 하는 작업에는 적합하지 않음
- 이는 전체 입력 시퀀스에 대한 조건부로 출력 시퀀스를 생성하기 때문
- 본 논문에서 저자들은 전체 계산을 다시 하지 않고 입력 값이 도착할 때마다 점진적인 예측을 할 수 있는 뉴럴(neural) 트랜스듀서를 제시
- seq-to-seq 모델과 달리, 뉴럴 트랜스듀서는 부분적으로는 관찰된 입력 시퀀스에 근거하여, 부분적으로는 생성해 낸 시퀀스에 근거하여 다음 단계 분포를 계산
- 각 time step에서 트랜스듀서는 많은 출력 기호로써 0에서 다수을 내보내기로 결정할 수 있음
- 데이터는 인코더(encoder)를 사용해 처리되며 트랜스듀서에 입력값으로 제공
- 매 단계마다 기호를 방출하는 개별 결정은 기존의 역 전파로 배우기가 어려움. 그러나 동적 프로그래밍 알고리즘을 사용하여 목표하는 이산(discrete) 결정을 생성하여 트랜스듀서를 훈련할 수 있음
- 실험 결과는 뉴럴 트랜스듀서가 데이터가 들어올 때 출력 예측을 생성하는 데 필요한 설정에서 잘 작동한다는 것을 보여줌. 또한 뉴럴 트랜스듀서는 attention 메커니즘이 사용되지 않는 경우에도 긴 시퀀스에 대해 잘 수행됨
1. Introduction
- 이 논문에서는 seq-to-seq 학습 모델의 보다 일반적인 클래스인 뉴럴 트랜스듀서를 제시
- 뉴럴 트랜스듀서는 입력 블록이 도착하면 출력 덩어리(길이가 0일 수도 있는)를 생성 할 수 있으므로 온라인 조건을 만족(아래 Figuere 1의 (b) 참고)
- 이 모델은 seq-to-seq 모델을 구현하는 트랜스듀서 RNN을 사용하여 각 블록에 대한 출력을 생성
- 트랜스듀서 RNN에 대한 입력은 다음 두 가지에서 비롯
- 인코더 RNN
- recurrent state
- 즉, 트랜스듀서 RNN은 인코더 RNN에 의해 블록에 대해 계산된 자질(feature)과 이전 블록의 마지막 단계에서 트랜스듀서 RNN의 반복 상태에 조건부로 된 출력 시퀀스에 대한 로컬 확장을 생성
- 트랜스듀서 RNN에 대한 입력은 다음 두 가지에서 비롯
- 학습 중에는 입력 시퀀스에 대한 출력 기호 정렬(alignment)을 사용할 수 없음
- 이 제한을 극복하는 한 가지 방법은 정렬을 잠재 변수(latent variable)로 취급하고 이 선형 변수의 가능한 모든 값을 소외시키는(marginalize) 것
- 또 다른 접근법은 다른 알고리즘에서 정렬을 생성하고 이러한 정렬의 확률을 최대화하기 위해 모델을 훈련시키는 것
- CTC(Connectionist Temporal Classification)는 반복적인 신경망 (RNN)에 의해 생성된 단항 전위보다 쉽게 주 변화를 허용하는, 동적 프로그래밍 알고리즘을 사용하는 전자의(앞서 설명한 1번 방법) 전략을 따름
- 그러나 본 모델에서는 신경망이 단지 입력 데이터뿐만 아니라 정렬, 그리고 현재 단계까지 생성된 전체 결과물에 기반하여 다음 단계 예측을 하기 때문에 이 전략이 불가능
- 본 논문에서는 동적 프로그래밍 알고리즘을 사용하여 이 모델에서 최적에 근접한(approximate) 정렬을 계산할 수 있는 방법을 보여줌
2. Related works
- 본 연구는 전통적인 구조화된 예측 방법과 관련이 있으며, 음성 인식에서 흔히 볼 수 있음
- 이 작업은 HMM-DNN 및 CTC 시스템과 유사
- 이러한 접근법의 중요한 측면은 모델이 모든 입력 시간 단계에서 예측을 한다는 것
- 이러한 모델의 약점은 일반적으로 각 출력 단계에서 예측 사이에 조건부 독립성을 가정한다는 것
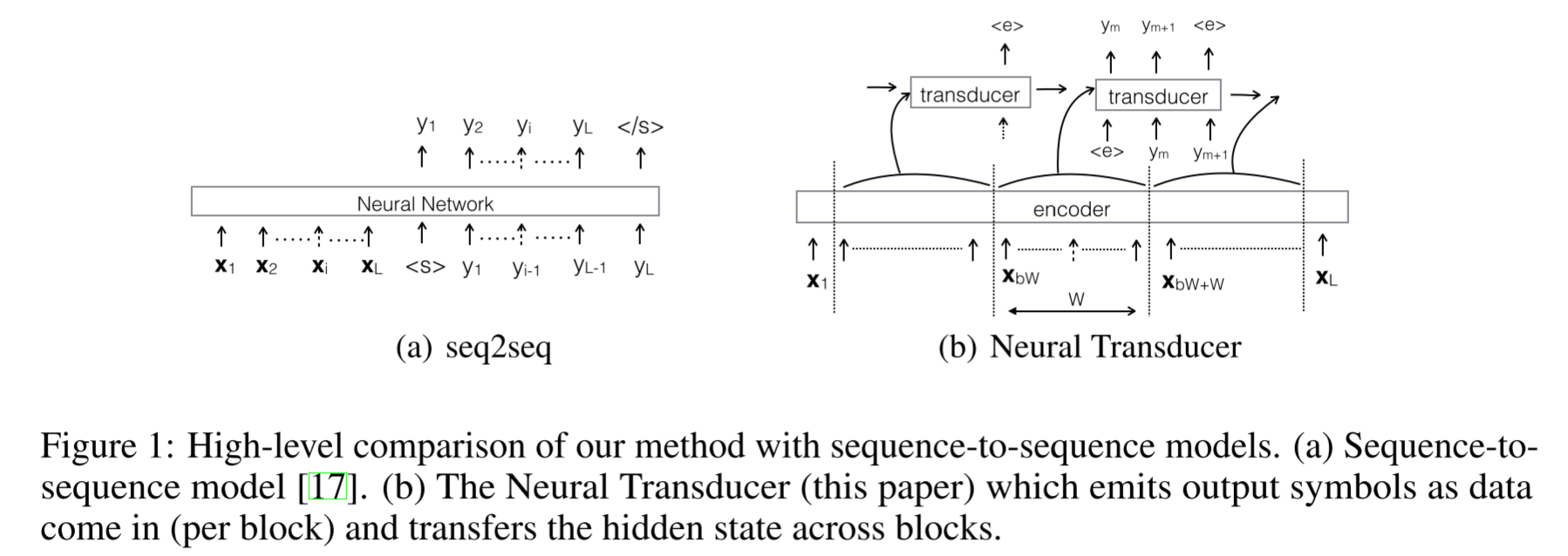
- seq-to-seq 모델은 이러한 가정을 하지 않고 다른 돌파구를 마련
- 출력 시퀀스는 지금까지 생성된 부분적인 출력 시퀀스와 전체 입력 시퀀스에 근거하여 다음 단계를 예측
- 위 Figure 1의 (a)는 이러한 아키텍처의 추상화된 수준의 모습
- 그러나 그림에서 볼 수 있듯이 이 모델은 음성 발화가 끝날 때까지 기다린 후 디코딩을 시작해야 한다는 한계
- 이러한 특징은 실시간 음성 인식이나 온라인 번역 등에는 매력적이지 않음
- Bahdanau et. el.은 moving windowed attention을 사용하여 음성 인식에서 이를 개선하려고 시도했지만 윈도우로 나누어진(windowed) 데이터 세그먼트에서 출력을 생성할 수 없는 경우 이 상황을 해결하는 메커니즘을 제공하지 않음
-
Figure 1(b)은 본 연구의 방법과 seq-to-seq 모델의 차이를 보여줌
- 본 모델과 상당히 관련된 모델은 시퀀스 트랜스듀서 [81, 92]
- 이 모델은 전사(transcription) 모델과 예측(prediction) 모델을 결합하여 CTC 모델을 보강
- 예측 모델은 언어 모델과 유사하며, 다음 스텝을 예측하는 모델로써 출력 토큰만을 다룸
- 이것은 매 시간 단계(time step)에서 독립적인 예측을 하는 CTC에 비해 모델을 더 표현력 있게 만들어 줌
- 그러나 본 논문에서 제시된 모델과 달리, 시퀀스 트랜스듀서에서의 두 모델은 독립적으로 작동
- 이 모델은 특성 time step에서의 예측 네트워크 자질들이 미래의 전사 네트워크 자질들을 바꿀 수 있는 메커니즘을 제공하지 않으며 그 반대의 경우도 마찬가지
역주: 예측 네트워크가 계산될 때는 이미 전사(transcript) 네트워크에서 값이 다 넘어 온 다음이므로 예측 네트워크의 자질들이 전사 네트워크에 영향을 줄 수 없음
- 사실상 우리의 모델은 해당 모델과 seq-to-seq 모델을 일반화하였다고 할 수 있음
- 이 모델은 특성 time step에서의 예측 네트워크 자질들이 미래의 전사 네트워크 자질들을 바꿀 수 있는 메커니즘을 제공하지 않으며 그 반대의 경우도 마찬가지
- 우리의 공식은 학습 과정에서 정렬(alignment)을 추론하는 것을 요구
- 그러나 우리의 실험 결과는 정규화를 전혀 하지 않은 작은 데이터셋에서도 비교적 빠르고 정확도가 거의 손실되지 않은 채 계산이 수행될 수 있음을 보임
- 또한 alignment가 주어지면 다양한 작업에 대해 오프라인으로 쉽게 수행 될 수 있으므로 앞의 추론 단계 없이 모델이 상대적으로 더 빠르게 학습될 수 있음
3. Method
3.1 Model
- 는 시간 단계(time step) 길이의 입력 데이터
- 여기서 는 입력 time step 의 자질
- 를 블록 크기, 즉 변환기가 출력 토큰을 방출하는 주기성
- 는 블록 수
- 입력 시퀀스에 해당하는 타깃 시퀀스를 라고 놓음
- 또한 트랜스듀서가 입력 블록에 대해 인 길이의 출력 시퀀스 를 생성한다고 생각
- 각 시퀀스에는 어휘에 추가 된 기호가 패딩되어 있음
- 이것은 트랜스듀서가 다음 블록에서 데이터를 계속 사용하고 소비할 수 있음을 의미
- 블록에 대해 기호가 생성되지 않으면 이 기호는 CTC의 빈(blank) 기호와 유사
역주: 트랜스듀서는 사이즈의 블록을 입력으로 받아 0~M 사이즈의 출력 시퀀스를 방출. 출력의 길이가 0인 경우는 blank의 의미
트랜스듀서의 출력 시퀀스는 이 들어간 경우 인데 여기서 가 해당 블록에서의 출력 길이인 것
- 각 시퀀스에는 어휘에 추가 된 기호가 패딩되어 있음
- 시퀀스 는 다양한 정렬의 입력으로부터 변환(transduced) 될 수 있음
- 를 입력 블록에 대응하는 출력 시퀀스 의 모든 alignment를 모아 둔 집합
- 를 그러한 정렬 중 하나라고 할 때, 의 길이는 라는 블록 기호의 끝부분()이 있기 때문에 의 길이보다 만큼 더 길다는 점 유의
- 그러나 블록에서의 (출력 시퀀스)에 일치하는 시퀀스 의 수는 블록들에 대한 의 모든 가능한 alignment들보다 훨씬 더 큼
- 요소 가 align된 블록은 인덱스 이전에 나온 기호의 수를 세어 간단히 추론 할 수 있음
- ()을 번째 블록에서 방출된 의 마지막 토큰의 위치라고 가정
-
과 이라는 사실을 기억해야 함. 따라서 각 블록 에 대해 가 됨
- 이 섹션에서는 을 계산하는 방법을 보일 예정
- 이후 섹션 3.5에서 를 계산하고 최적화하는 방법을 기술
- 먼저 다음과 같이 (1), 즉 블록 의 끝까지 출력 시퀀스 를 볼 확률을 계산
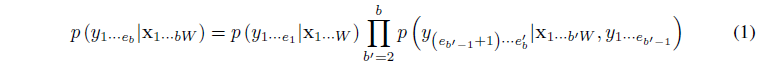
- 이 방정식의 각 항은 그 자체로 체인 룰 decomposition에 의해 계산
- 예를 들어 임의의 블록 에 대해 아래와 같음
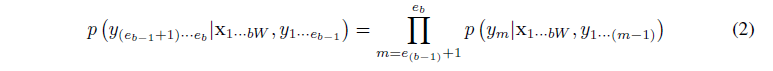
- 수식 (2)의 next step 확률 term, 는 트랜스듀서에 의해 계산
- 를 입력으로 받아 인코더에서 인코딩된 값, 그리고 이전 방출(emission) 단계에서 트랜스듀서의 입력값으로 쓰이는 label prefix 두 가지가 이용
3.2 Next step prediction

Figure 2: 음성을 위한 뉴럴 트랜스듀서 구조의 개요. 입력 음향(acoustic) 시퀀스는 인코더에 의해 처리되어 각 단계 에서 hidden state 벡터 를 생성. 트랜스듀서는 각 단계에서 블록을 입력으로 받고 seq-to-seq 모델을 사용하여 최대 개의 출력 토큰을 생성. 트랜스듀서는 이전 시간 단계의 출력값에 대한 반복(recurrent) 연결을 사용해 블록을 가로질러 상태(state)를 유지. 아래 그림은 블록 에 대한 토큰을 생성하는 트랜스듀서를 보여줌. 이 블록에서 출력되는 sub시퀀스는
- 이하의 내용은 위 Figure 2를 참고
- 이 예제(Figure 2의)는 출력 단계(output step) 에서 단위 과 을 갖는 두 개의 히든 레이어가 있는 트랜스듀서
- 이 그림에서는 블록 에 대한 다음 단계 예측(next step prediction)을 표현
- 이 블록의 경우, 첫 번째 출력 기호의 위치는 이고, 마지막 출력 기호의 위치는
- 예를 들어
- 트랜스듀서는 아래 순서를 통해 를 사용하여 신경망의 매개 변수 다음 단계 예측을 계산
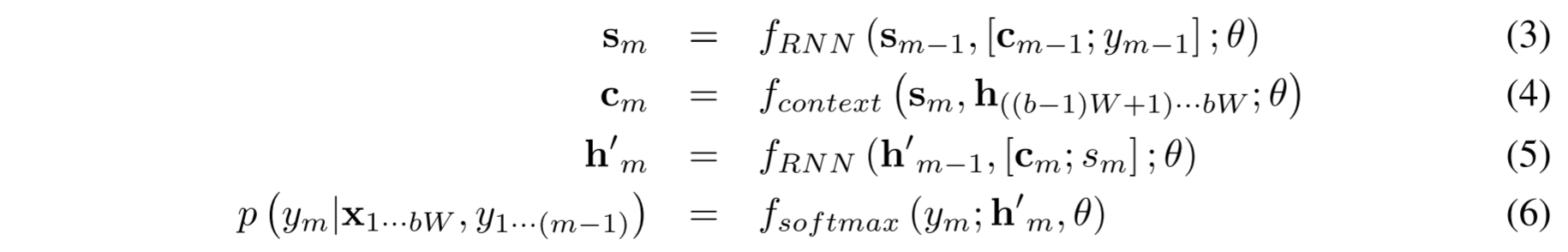
- 여기서 (, ;)은 마지막 단계에서 반복 상태 벡터 와 현재 시간 단계에서의 입력값 를 사용하여 단계에서 계층에 대한 마지막 상태 벡터 을 계산하는 RNN 함수 (예 : LSTM 또는 sigmoid 또는 tanh RNN)
- 는 소프트맥스 층에서 계산되는 소프트맥스 분포이며, 및 fcontext sm, h (b1) W + 1) · bW; 는 컨텍스트 함수이며, 현재 시간 단계에서 상태 에서 출력 단계 에서 트래스듀서에 입력을 계산하고, 인코더의 자질 현재 입력 블록 입니다. 우리는 주의 메커니즘이 있거나 없거나, 상황에 맞는 벡터를 계산하는 다양한 방법을 실험했습니다. 이것들은 3.3절에 설명되어 있습니다.
3.3 Computing
- 저자들은 두 가지의 모델로 실험: MLP-attention 모델, DOT-attention 모델, LSTM-attention 모델
- MLP-attention 모델: 컨텍스트 벡터가 이전 연구들[5, 1, 3]과 유사한 attention 모델로 계산
- 이 모델에서 컨텍스트 벡터 는 두 단계로 계산
- 먼저 정규화된 attention 벡터 이 트랜스듀서 state 에서 계산되고 다음은 현재 블록의 인코더의 hidden state 가 선형 적으로 결합되어 컨텍스트 벡터로 사용
- 을 계산하기 위해 다층 퍼셉트론은 트랜스듀서 state 과 인코더 의 각 쌍에 대해 스칼라 값을 계산
- attention 벡터는 스칼라 값, 에서 계산 - 수식으로는 아래와 같음
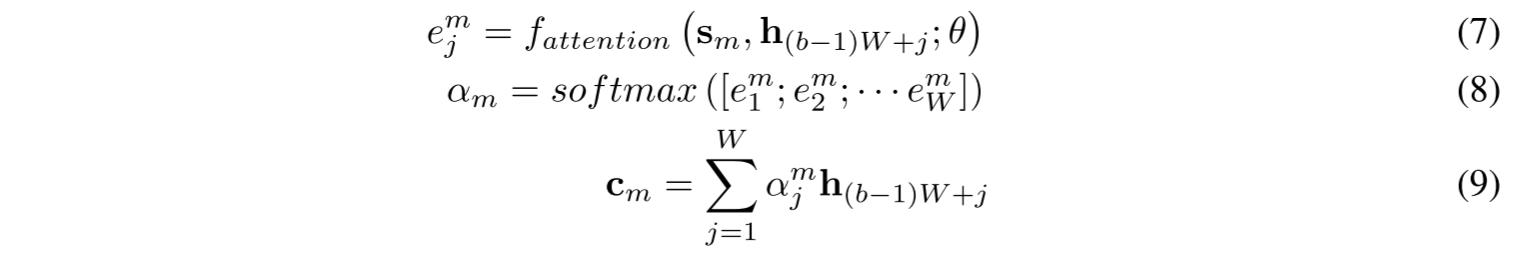
- DOT-attention 모델: 에 대한 간단한 모델을 사용하여 실험을 수행
- 앞선 두 가지 attention 모델의 단점
- attention 모델이 한 출력 time step에서 다음 step로 초점을 앞으로 이동할 수 있도록 해 주는 명시적 메커니즘이 없음
- 상이한 입력 프레임에 대해 소프트맥스 함수에 대한 입력으로 계산된 에너지 는 각 time step에서 서로 독립적이기 때문에 소프트맥스 함수를 통해서가 아니면 서로 변조(modulate)할 수 없음
- ex, 강화(enhance) 또는 억제(suppress)
- Chorowski et.al.[6]은 마지막 단계에서 attention를 사용하는 한 단계에서 attention에 영향을 미치는 컨볼루션 연산자를 사용하여 이 문제를 개선
- LSTM-attention 모델: 저자들은 새로운 attention 메커니즘을 사용하여 이 두 가지 단점을 해결하려고 시도
- 이 모델에서 를 소프트맥스로 공급하는 대신, 하나의 hidden layer를 가진 RNN으로 공급. 이 RNN이 각 time step에서 소프트맥스 attention 벡터를 출력
- 따라서 모델은 특정 time step 내에서뿐 아니라 여러 time step에 걸쳐 attention 벡터를 변조할 수 있어야 함
- 이러한 형태의 attention 모델은 Chorowski et al.(2015)의 컨볼 루션 연산자보다 더 일반적
- 하지만 문맥 윈도우 크기가 일정한 경우에만 적용할 수 있음
3.4 Addressing End of Blocks
- 모델은 각 블록에서 작은 출력 토큰 시퀀스만 생성하므로 트랜스듀서를 한 블록에서 다음 블록으로 이동시키는 메커니즘을 다루어야 함
- 저자들은 이 방법을 각기 다른 세 가지 방법으로 실험
- 트랜스듀서 신경망이 훈련 데이터로부터 모델을 암묵적으로 학습하기를 바라면서 에 대한 명시적인 메커니즘을 적용하지 않음
- 를 구분하기 위해 기호 를 라벨 시퀀스에 추가하고 이 기호를 타깃 사전에 추가
- 따라서 방정식 6의 소프트맥스 함수는 암묵적으로 토큰을 방출하거나 트랜스듀서를 다음 블록으로 앞으로 이동시키는 것을 학습
- attention 벡터에 별도의 로지스틱 함수를 사용하여 트랜스듀서를 앞으로 이동시키는 모델을 모델링
- 현재 단계가 블록의 마지막 단계인지 여부에 따라 로지스틱 함수의 목표는 0 또는 1이 됨
참고문헌
- Graves, Alex, et al. “Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks.” Proceedings of the 23rd international conference on Machine learning. ACM, 2006.
- Sequence Modeling With CTC
- RL (강화학습) 기초 - 5. Dynamic Programming
-
Alex Graves. Sequence Transduction with Recurrent Neural Networks. In International Conference on Machine Learning: Representation Learning Workshop, 2012. ↩
-
Alex Graves, Abdel-rahman Mohamed, and Geoffrey Hinton. Speech Recognition with Deep Recurrent Neural Networks. In IEEE International Conference on Acoustics, Speech and Signal Processing, 2013. ↩




댓글남기기