
RNN 관련된 논문을 보다 보면 ‘alignment’라는 용어가 많이 등장합니다. 한국어로는 주로 ‘정렬’이라고 번역되는데, 한곳에 정리된 자료를 찾지 못해 archive 차원에서 정리합니다.
본 포스트에서의 ‘RNN’은 입력과 출력이 모두 시퀀스인, many-to-many형태라고 생각하시면 됩니다. 이러한 형태의 task로는 음성인식, 질의응답, 기계번역 등이 있습니다.
Sequence alignment in Bioinformatics
우선 ‘Sequence alignment’의 영문 위키피디아 정의를 살펴보면 아래와 같습니다.
In bioinformatics, a sequence alignment is a way of arranging the sequences of DNA, RNA, or protein to identify regions of similarity that may be a consequence of functional, structural, or evolutionary relationships between the sequences. Aligned sequences of nucleotide or amino acid residues are typically represented as rows within a matrix. Gaps are inserted between the residues so that identical or similar characters are aligned in successive columns. Sequence alignments are also used for non-biological sequences, such as calculating the edit distance cost between strings in a natural language or in financial data. - Wikipedia
생물 정보학에서 서열 정렬(alignment)은 DNA, RNA 또는 단백질의 서열을 배열하여 서열 간의 기능적, 구조적 또는 진화적 관계의 결과일 수 있는 유사성 영역을 확인하는 방법입니다. 뉴클레오타이드 또는 아미노산 잔기의 정렬된 서열은 일반적으로 매트릭스 내의 행으로 표현됩니다. 잔기 사이에 간격이 삽입되어 동일하거나 유사한 문자가 연속적인 열에 정렬됩니다. 시퀀스 정렬은 자연 언어 또는 재무 데이터의 문자열 간의 편집 거리 비용을 계산하는 것과 같은 비 생물학적 시퀀스에도 사용됩니다.
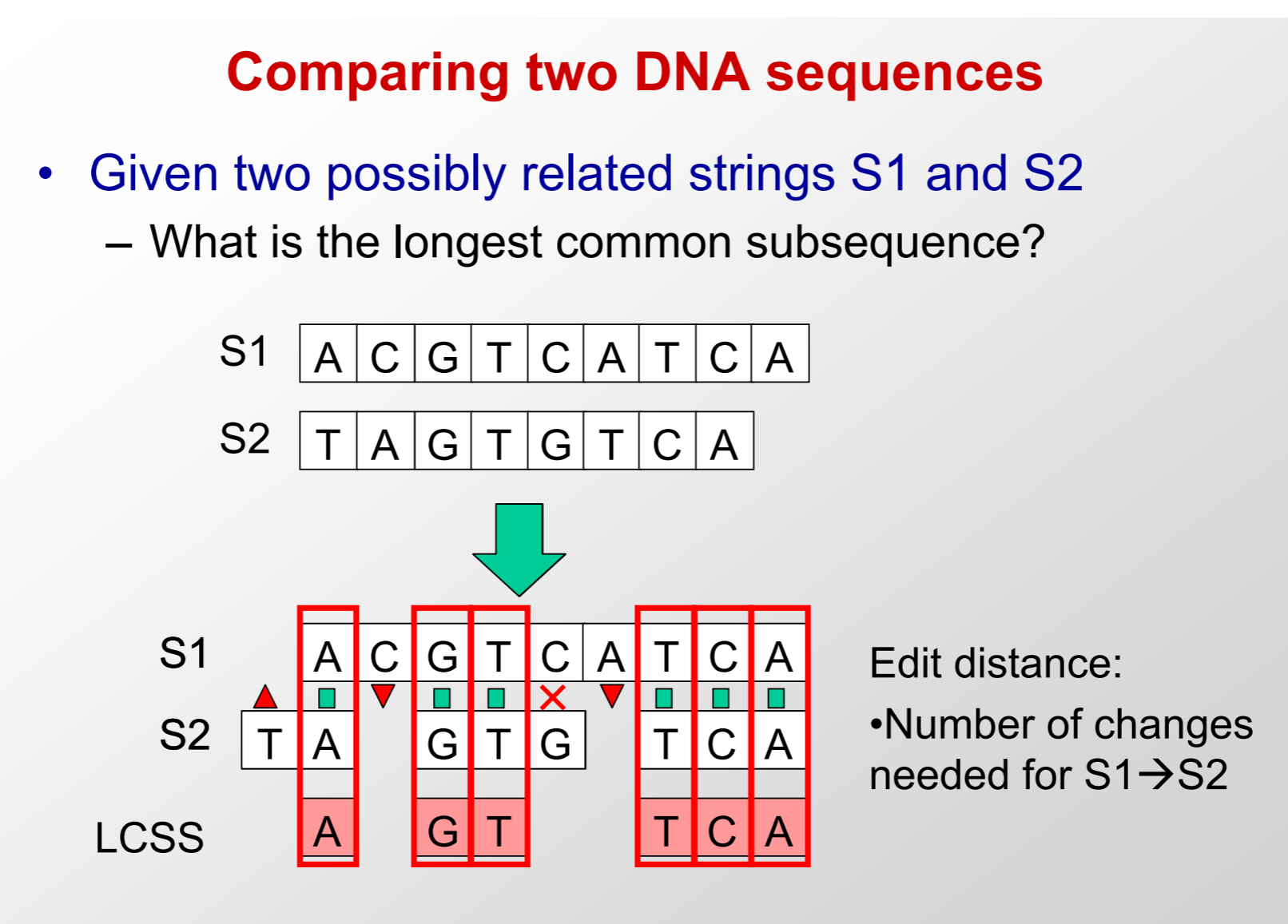
생물학 배경지식이 없는 사람은 이해하기 어려운… 설명인데 그림으로 보면 대략 두 개의 시퀀스가 존재할 때(생물정보학에서는 단백질의 서열을 뜻하겠지요) 중요한 위치들(위 설명에 따르면 ‘동일하거나 유사한 문자가 연속적인 열에 정렬’되는 구간)을 맞춰주거나 가장 긴 부분 시퀀스(subsequence)를 찾아주는 것을 뜻합니다(사실 저도 생물학을 잘 모르기 때문에 그런 것처럼 보입니다).
아래 그림 중 위쪽은 ClustalO가 만들어낸 포유류 히스톤 단백질의 시퀀스 정렬(sequence alignment)입니다. 각기 다른 포유류들의 단백질 시퀀스 중에서 동일하게 나타나는 구간들이 있는데 이를 맞춰 줌으로써 공통점과 차이점을 쉽게 발견할 수 있습니다. 그 아래 그림은 MIT의 강의 자료인데, 두 문자열 시퀀스 S1과 S2에서 edit distance를 이용해 subsequence를 찾는 과정을 보여줍니다.

Sequence alignment in RNN
RNN 관련 논문에서는 아래와 같은 표현들이 자주 등장합니다.
During training, alignments of output symbols to the input sequence are unavailable. One way of overcoming this limitation is to treat the alignment as a latent variable and to marginalize over all possible values of this alignment variable. 1
훈련 중에는 입력 시퀀스에 대한 출력 기호를 정렬(alignment)하는 것은 불가능합니다. 이 제한을 극복하는 한 가지 방법은 정렬을 잠재(latent) 변수로 취급하고 이 정렬 변수의 가능한 모든 값을 소외시키는(marginalize) 것입니다.
한마디로 ‘입력 시퀀스에 대한 출력 시퀀스의 정렬(alignment)’이라는 것인데, stackexchange의 한 질문에 답이 잘 되어있어서 이를 한국어로 옮겨 봤습니다.
단일 RNN에서 RNN은 일련의 입력을 받아 일련의 출력을 제공하며 일반적으로 입력값과 동일한 개수의 출력값을 생성내 냅니다.
Inputs: i1 i2 i3 i4 i5 i6 i7 Outputs: o1 o2 o3 o4 o5 o6 o7‘출력’이란 예를 들어 입력 값에 대한 그 다음 time step에서의 예측값일 수 있습니다. 이것은 문장의 다음 단어를 예측하는 것과 같은 task에 적용됩니다. 여기서는 이 첫 번째 단어이고 가 두 번째 단어입니다. 은 에 대한 예측이고 는 에 대한 예측값입니다. 입력값들과 출력값들의 사이에 one-to-one 관계가 존재합니다.
그러나 프랑스어에서 영어로 번역을 하는 경우 입력 단어 및 출력 단어의 수가 일치하지 않을 수 있습니다. (아래 예시에서 프랑스어의 두 단어로 이루어졌던 문장이 영어로 번역하면 세 단어로 늘어나게 됨)
Il pleut It is raining (2 words => 3 words)sequence-to-sequence 모델에서는 두 개의 RNN을 연속적으로(back-to-back) 구성하여 이 문제를 해결합니다. 첫 번째 RNN은 임의의 시퀀스를 입력값으로 받아 모든 입력 단어를 받은 후 RNN의 은닉 상태(hidden state)인 단일 임베딩 벡터에 매핑합니다.
i1 i2 i3 i4 i5 i6 i7 ... => embedding-vector그런 다음 두 번째 RNN은 이 임베딩 벡터로 초기화된 다음 종료 토큰을 출력할 때까지 추가 입력없이 단어를 자유롭게 예측합니다.
embedding-vector => o1 o2 o3 ... termination-token이 두 가지를 함께 사용하면 어떠한 길이의 시퀀스를 펌핑함으로써 출력 시퀀스가 입력과는 다른 길이일 수 있습니다. 예를 들어 아래와 같은 형태가 됩니다.
i1 i2 i3 => embedding-vector => o1 o2 o3 o4 o5 termination-token
Alignment in sequence-to-sequence model
위 설명에서 언급된 sequence-to-sequence 모델(이하 seq-to-seq 모델)을 이해하면 alignment에 대해서도 쉽게 이해할 수 있기 때문에 아래에 해당 모델을 간략히 설명하고 마치도록 하겠습니다. 기본적인 many-to-many 형태의 RNN은 아래 그림처럼 입력 시퀀스의 첫번째 요소가 바로 다음 요소를(출력 시퀀스의 첫 번째 요소) 예측하도록 학습하므로 입력 시퀀스와 출력 시퀀스의 길이가 같아야 합니다.(또는 최소한 출력 시퀀스의 길이가 ‘알려져 있어야’ 합니다)
아래 그림은 ‘h -> e -> l -> l -> o’ 의 순서로 문자를 예측하는 모델을 학습하는 과정을 보여줍니다. ‘h’를 입력으로 그 다음 ‘e’를 예측하도록 학습하고, 다시 ‘e’가 ‘l’을 예측하도록 학습하므로, 시퀀스 내의 개별 엘리먼트 관점에서 보면 각각이 one-to-one 관계를 갖는다고 볼 수 있습니다.
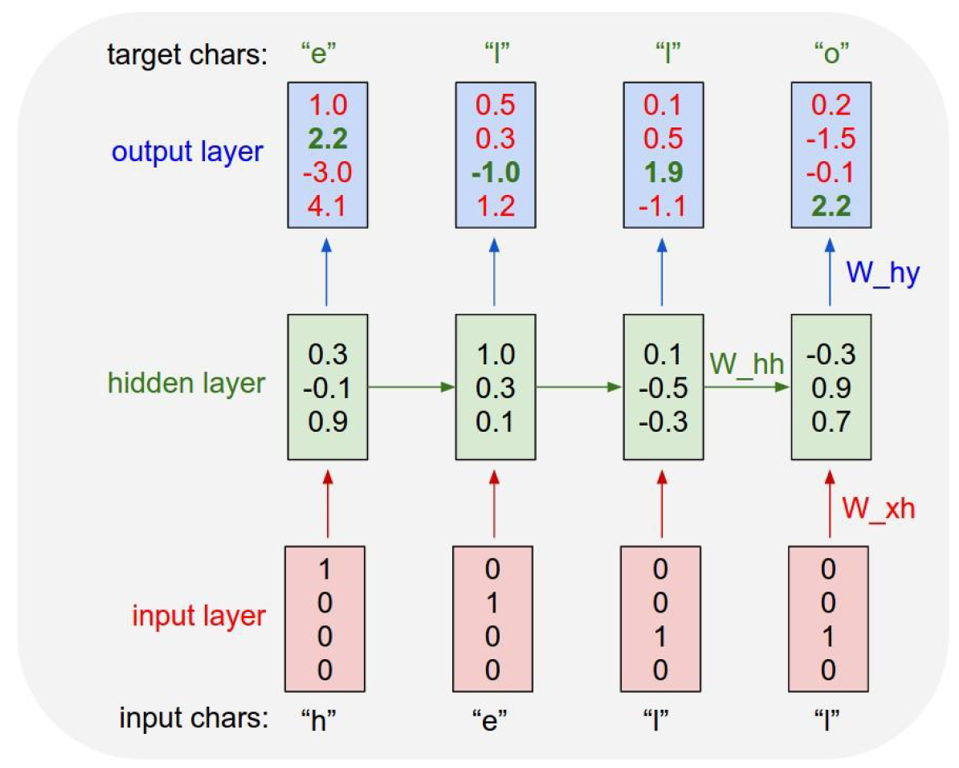
2014년 구글에서 발표하여 굉장한 호응을 얻었던 seq-to-seq 모델은2 입력 벡터와 출력 벡터의 길이가 동일해야만 했던(또는 미리 출력 시퀀스의 일이를 알고 있어야 했던) 기존 RNN의 한계를 극복하기 위해 두 개의 RNN 모델을 연속으로 붙여 이용하는 발상의 전환을 시도했습니다.
시퀀스는 입력 및 출력의 차원(dimensionality)이 알려져 있고 길이가 고정되어야 하기 때문에 DNN에 있어서 도전입니다. 본 논문에서 우리는 Long Short-Term Memory (LSTM) 구조의[16] 간단한 적용이 일반적인 sequence to sequence 문제3를 해결할 수 있음을 보여줍니다. 이 아이디어에서는 하나의 LSTM를 이용해 한 time step에 한 개씩 입력 시퀀스를 읽어들여 큰 고정 차원 벡터 표현을 얻은 다음, 또다른 LSTM을 사용하여 해당 벡터에서 출력 시퀀스를 추출하는 것입니다 (그림 1 참고). 두 번째 LSTM은 본질적으로 입력 시퀀스에 기반한다는 점을 제외하고는 RNN 언어 모델이라 할 수 있습니다[28, 23, 30]. LSTM이 장거리 시간 의존성(long range temporal dependency)을 가진 데이터에서 성공적으로 학습할 수 있는 능력은 입력과 해당 출력 사이의 상당한 시간 지연으로 인해 이 응용 프로그램에 대한 자연스러운 선택입니다. - Sequence to sequence learning with neural networks
아래 그림은 모델의 간략한 구조를 보여줍니다(논문 내 Figure 1). “ABC”라는 텍스트를(시퀀스 형태로) 입력을 받아 “WXYZ”를 출력으로(역시 시퀀스 형태로) 내보내는 과정에서 입력 시퀀스를 받아들이는 RNN은 출력으로 고정된 길이의 벡터를 생성하게 되고, 이를 다시 입력으로 받아 두 번째 RNN이 진짜 예측값 시퀀스를 출력하게 됩니다.
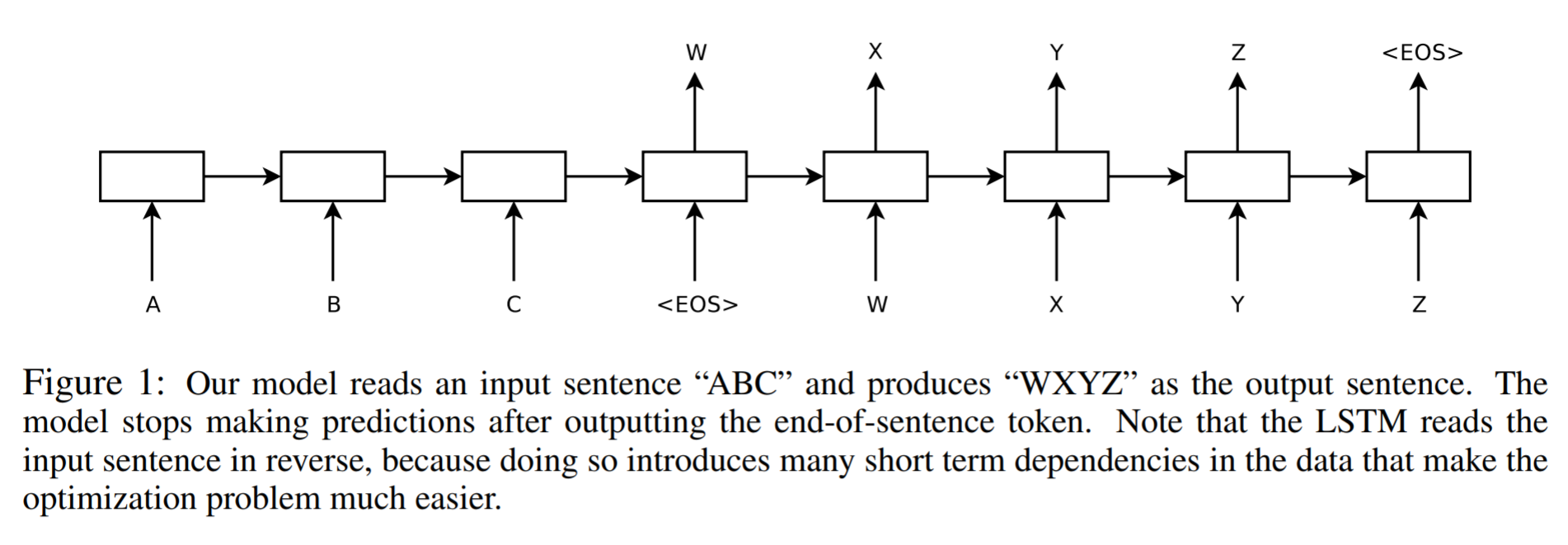
이 구조의 다른 이름은 ‘encoder-decoder(인코더-디코더)’ 모델입니다. 저자들은 고정 차원 벡터를 얻는 첫 번째 RNN을 ‘encoder’로, 고정 차원 벡터에서 최종 예측값 출력을 얻는 RNN을 ‘decoder’로 지칭했으며, 본 논문에서는 인코더와 디코더에 모두 LSTM을 사용했습니다. 인코더-디코더 모델은 입력 벡터와 출력 벡터의 차원이 같아야 했던 기존의 정렬(alignment) 한계를 극복하기 위해 고안된 방식입니다.
참고 문헌
- Wikipedia - Sequence alignment
- Sequence Alignment and Dynamic Programming
- Stackexchange - What does alignment between input and output mean for recurrent neural network
- Sutskever, Ilya, Oriol Vinyals, and Quoc V. Le. “Sequence to sequence learning with neural networks.” Advances in neural information processing systems. 2014.
-
Jaitly, Navdeep, et al. “A neural transducer.” arXiv preprint arXiv:1511.04868 (2015). ↩
-
Sutskever, Ilya, Oriol Vinyals, and Quoc V. Le. “Sequence to sequence learning with neural networks.” Advances in neural information processing systems. 2014. ↩
-
입력값과 출력값이 둘 다 시퀀스인, 말 그대로 시퀀스에서 시퀀스로 변환되는 형태의 task. 예를 들어 번역, 질의응답, 음성인식 등이 있음 ↩




댓글남기기