
참고자료
- 원 논문 (DeepFM: A Factorization-Machine based Neural Network for CTR Prediction)
들어가기 전에 알아야될 용어
- Factorization Machines
- FM은 고차원 데이터에서도 제품 변수 간의 상호작용을 통해 효율적으로 사용할 수 있는 지도학습으로 회귀분석과 분류분석 기법을 모두 할 수 있는 기계학습
- 다항식 회귀 또는 커널 방법과 동등하지만, 더 작고 빠른 모델 평가를 통해 정확도를 얻을 수 있음
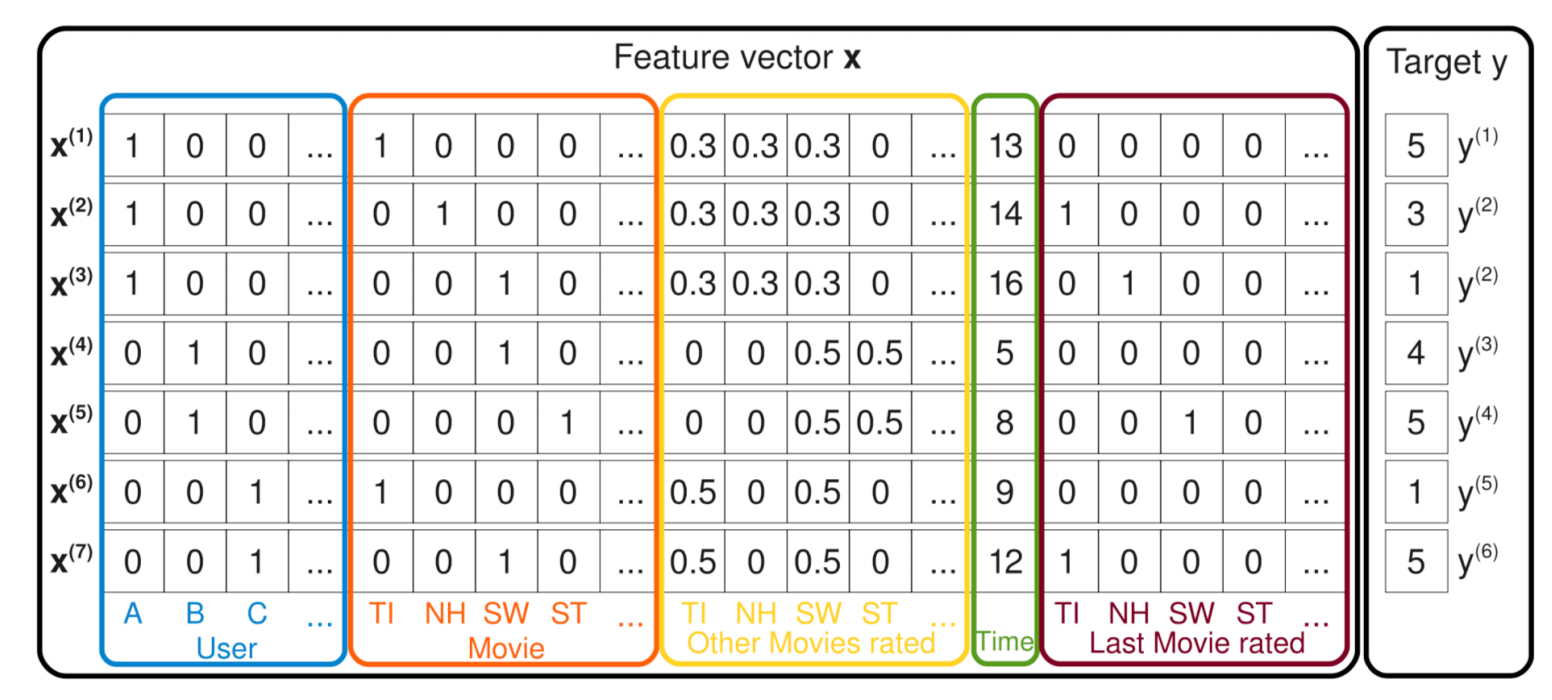

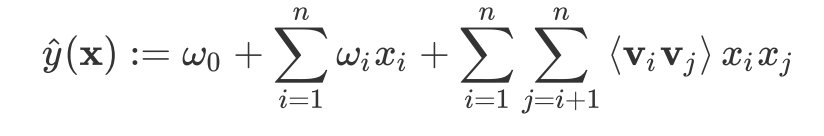
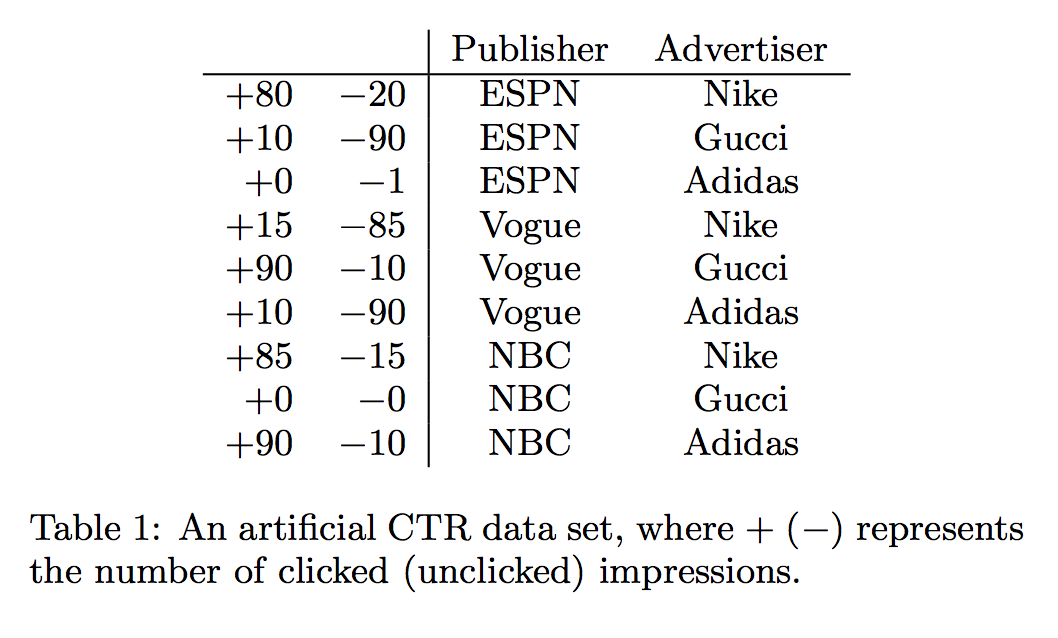

- Wide & Deep Learning
- deepCTR 라이브러리
ABSTRACT
- 추천 시스템에 대한 CTR(클릭률)을 극대화하려면 user behaviors의 뒤에 숨겨진 정교한 feature의 상호 작용을 학습하는 것이 중요합니다. 그동안의 진전에도 불구하고, 기존 방법은 저수준 또는 고차원의 상호 작용에 대한 강한 bias을 갖고 있거나 전문 기술을 필요로 합니다.
- 이 논문에서는 Low 및 High Feature의 상호 작용을 강조하는 end-to-end 학습 모델을 도출할 수 있다는 점
- 제안된 모델, DeepFM은 새로운 신경망 아키텍처인데 feature 학습을 위해서 factorization machines의 힘을 결합합니다. (추천 시스템 + 딥러닝)
- DeepFM은 Google의 최신 Wide & Deep 모델과 비교하여 기존의 feature 이외에도 feature 엔지니어링이 필요없는 “Wide” 부분과 “Deep” 부분을 공유합니다.
- 벤치마크 데이터와 상업용 데이터 모두에서 CTR 예측을 위해 기존 모델보다 DeepFM의 효율성과 효율성을 입증하기 위한 포괄적인 실험이 수행됩니다.
1. INTRODUCTION
- 사용자가 추천 항목을 클릭할 확률을 추정하는 것이 추천 시스템에서는 클릭율(CTR)의 예측이 중요합니다.
- 많은 추천 시스템에서 목표는 클릭 수를 최대화하는 것이므로 사용자에게 반환된 항목은 추정된 CTR로 순위를 매길 수 있습니다.
- 온라인 광고와 같은 다른 응용 프로그램 시나리오에서는 수익을 향상시키는 것이 중요하므로 순위 전략은 모든 후보에 걸쳐 CTR × bid로 조정할 수 있습니다.
- “bid”는 사용자가 항목을 클릭하면 시스템이 받는 이득입니다. 두 경우 모두 CTR을 올바르게 추정하는 것이 중요함
- CTR 예측은 사용자 클릭 동작 뒤에 implicit 기능 상호 작용을 배우는 것이 중요합니다.
- 앱 시장에서의 연구를 통해 사람들이 식사 시간에 음식을 배달하기 위한 앱을 다운로드하는 것을 발견했는데, 앱 카테고리와 시간 스탬프 사이의 (2 차) 상호 작용이 CTR의 신호로 사용될 수 있음을 시사합니다.
- 두 번째 관찰로, 유투브(게임 분야)에서 RPG 게임을 하는 남자 청소년은 앱 카테고리, 사용자 성별 및 연령 (3차) 상호 작용이 CTR의 또 다른 신호임을 의미합니다.
- 일반적으로 사용자 클릭 동작 뒤에 있는 기능의 상호 작용은 매우 정교할 수 있습니다.
- 여기서 Low 및 High 기능 상호 작용이 중요한 역할을 해야 합니다.
- Google의 Wide & Deep 모델 [Cheng et al., 2016]의 통찰력에 따르면
- Low 및 High 기능 상호 작용을 고려하면 동시에 혼자서 고려하는 경우에 대한 추가 개선이 이루어집니다.

- 핵심 과제는 피쳐 상호 작용을 효과적으로 모델링하는 것
- 일부 기능 상호 작용은 쉽게 이해할 수 있으므로 전문가가 설계할 수 있음 (Ex. 앱 카테고리와 시간 스탬프 같은 관계)
- 그러나 대부분의 다른 기능 상호 작용은 데이터에 숨겨져 있으며 선험적인 것을 식별하기가 어렵습니다 (예 : 고전적인 association rule 인 “기저귀와 맥주”는 전문가가 발견하는 대신 데이터에서 채굴됨)
- 기계학습으로 자동으로 캡처할 수 있음. 이해하기 쉬운 상호 작용에도 불구하고 전문가가 모델링 할 가능성은 거의 없음. 특히 기능 수가 많을 때 그렇습니다.
- 단순함에도 불구하고 FTRL [McMahan et al., 2013]과 같은 일반화된 선형 모델은 실제로 괜찮은 성능을 보였습니다.
- 그러나 선형 모델은 피쳐 상호 작용을 학습할 수 있는 능력이 없으며 일반적인 방법은 피쳐 벡터에 쌍방향 피쳐 상호 작용을 수동으로 포함하는 것
- 이러한 방법은 고차원 피쳐 상호 작용을 모델링하거나 훈련 데이터에 나타나지 않거나 거의 나타나지 않는 것을 일반화하기가 어렵습니다 [Rendle, 2010].
- Factorization Machines (FM) [Rendle, 2010] 모델은 기능 간의 잠재 벡터의 inner product으로서 쌍방향 기능 상호 작용을 특징으로 하며 매우 유망한 결과를 보여줍니다.
- 원칙적으로 FM은 고차 피쳐 상호 작용을 모델링 할 수 있지만 실제로는 일반적으로 복잡성이 높기 때문에 2 차 피쳐 상호 작용만 고려됨
- 학습 기능 표현에 대한 강력한 접근 방식으로 깊은 신경망은 정교한 기능 상호 작용을 배울 수 있는 잠재력을 가지고 있음
- 일부 아이디어는 CNN과 RNN을 CTR 전제 조건 [Liu et al., 2015; Zhang et al., 2014]으로 확장하지만
- CNN 기반 모델은 인접 기능 간의 상호 작용에 편향되어 RNN 기반 모델은 순차적 의존성을 가진 클릭 데이터에 더 적합합니다.
- [Zhang et al., 2016]은 표현을 특징으로 하고 Factorization-machine이 지원하는 신경망 (FNN)을 제안합니다.
- 이 모델은 DNN을 적용하기 전에 FM을 사전적으로 학습하므로 FM의 기능에 의해 제한됩니다.
- 피쳐 상호 작용은 임베딩 레이어와 완전 연결된 레이어 사이에 Product 레이어를 도입하고 Product based 신경망 네트워크 (PNN)를 제안함으로써 [Qu et al., 2016]에서 연구됩니다.

- [Cheng et al., 2016]에서 언급했듯이, PNN과 FNN은 다른 딥러닝 모델과 마찬가지로 CTR 예측에 필수적인 저차 피쳐 상호 작용을 거의 포착하지 못합니다.
- Low & High 피쳐 상호 작용을 모델링하기 위해 [Cheng et al., 2016]은 선형 (“Wide” 모델과 “Deep” 모델을 결합한 흥미로운 하이브리드 네트워크 구조 (Wide & Deep)를 제안
- 이 모델에서는 각각 “Wide”과 “Deep”에 대해 두 가지 입력이 필요하며 “Wide”의 입력은 여전히 전문가의 기능 엔지니어링에 의존합니다.
- 기존 모델은 저차 또는 고차 피쳐 상호 작용에 편향되거나 피쳐 엔지니어링에 의존한다는 것을 알 수 있습니다.
- 이 논문에서 원시 기능 외에도 피쳐 엔지니어링 없이 모든 order의 feature 상호 작용을 End to End 방식으로 배울 수 있는 학습 모델을 도출할 수 있음을 보여줍니다.
- 우리의 주요 공헌은 다음과 같이 요약됩니다.
- FM과 DNN의 구조를 통합하는 새로운 신경망 모델 Deep FM을 제안
- FM과 같은 low-order feature의 상호 작용을 모델링하고 DNN과 같은 고차 피쳐 상호 작용을 모델링 함
- Wide & Deep Learning [Cheng et al., 2016]과 달리 DeepFM은 기능 엔지니어링 없이 End To End 훈련을 받을 수 있음.
- DeepFM은 [Cheng et al., 2016]과 달리 Wide 부분과 Deep 부분이 동일한 입력과 임베딩 벡터를 공유하기 때문에 효율적으로 훈련할 수 있습니다. [Cheng et al., 2016]에서 입력 벡터는 넓은 부분의 입력 벡터에 수동으로 설계된 쌍방향 피쳐 상호 작용을 포함하므로 큰 크기가 될 수 있으며 복잡성을 크게 증가시킴
- 벤치마크 데이터와 상업용 데이터 모두에서 DeepFM을 평가. CTR 예측을 위해 기존 모델보다 지속적으로 개선됨
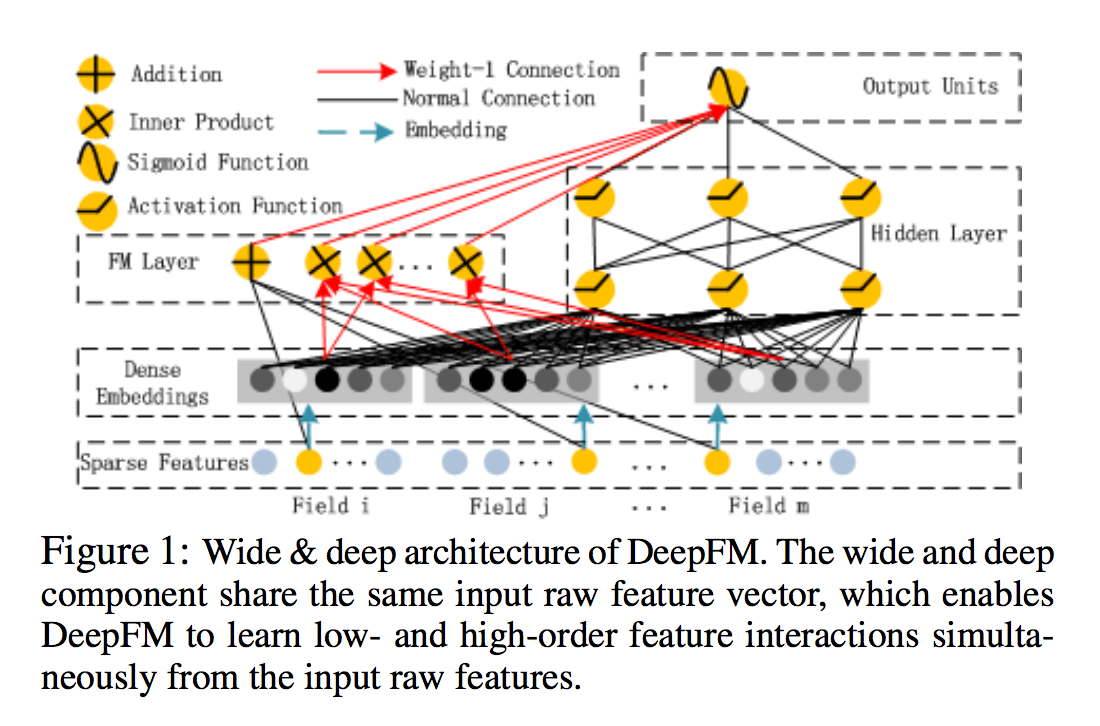
2. Our Approach
- 훈련을 위한 데이터 세트가 n 인스턴스 (x, y)로 구성되어 있다고 가정, 일반적으로 한 쌍의 사용자와 항목이 포함 된 m 필드 데이터 레코드이고 y 0, 1은 사용자 클릭 동작을 나타내는 관련 레이블입니다 (y = 1은 사용자가 항목을 클릭했다는 것을 의미하고 y = 0은 그렇지 않은 경우)
- 범주 필드 (예 : 성별, 위치) 및 연속 필드 (예 : 연령)를 포함 할 수 있음
- 각 범주형 필드는 one-hot encoding의 벡터로 표현되며 각 연속 필드는 값 자체 또는 이산 후 one-hot encoding의 벡터로 표시됩니다
- 각 인스턴스는 (x, y)로 변환. 여기서 x = [x field1, x field2, …, x filedj, …, x fieldm]은 x f ieldj가 j 번째 필드의 벡터 표현
- 일반적으로 x는 고차원적이며 극도로 희박함
- CTR 예측의 임무는 주어진 컨텍스트에서 특정 앱을 클릭할 확률을 추정하기 위해 예측 모델 y = CTR 모델(x)을 구축하는 것
2.1 DeepFM
- 저차원 및 고차원 기능 상호 작용을 배우는 것을 목표로 Factorization-Machine based neural network(DeepFM)을 제안
- 그림에 묘사된 것처럼 DeepFM은 동일한 입력을 공유하는 FM 구성 요소와 딥러닝 구성 요소의 두 가지 요소로 되어 있음
- 기능 i의 경우 스칼라 wi가 순서의 중요성을 측정하는 데 사용됨, 잠재 벡터 Vi는 다른 기능과의 상호 작용의 영향을 측정하는 데 사용됩니다.
- Vi는 FM 구성 요소에서 order2 피쳐 상호 작용을 모델링하고 고차 피쳐 상호 작용을 모델링하기 위해 깊은 구성 요소로 구성됨
- wi, Vi 및 네트워크 매개 변수를 포함한 모든 매개 변수는 결합된 예측 모델을 위해 훈련됨. 여기서 y (0, 1)는 예측된 CTR이고 yFM은 FM 구성 요소의 출력이며 yDNN은 깊은 구성 요소의 출력
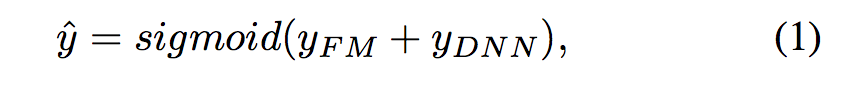
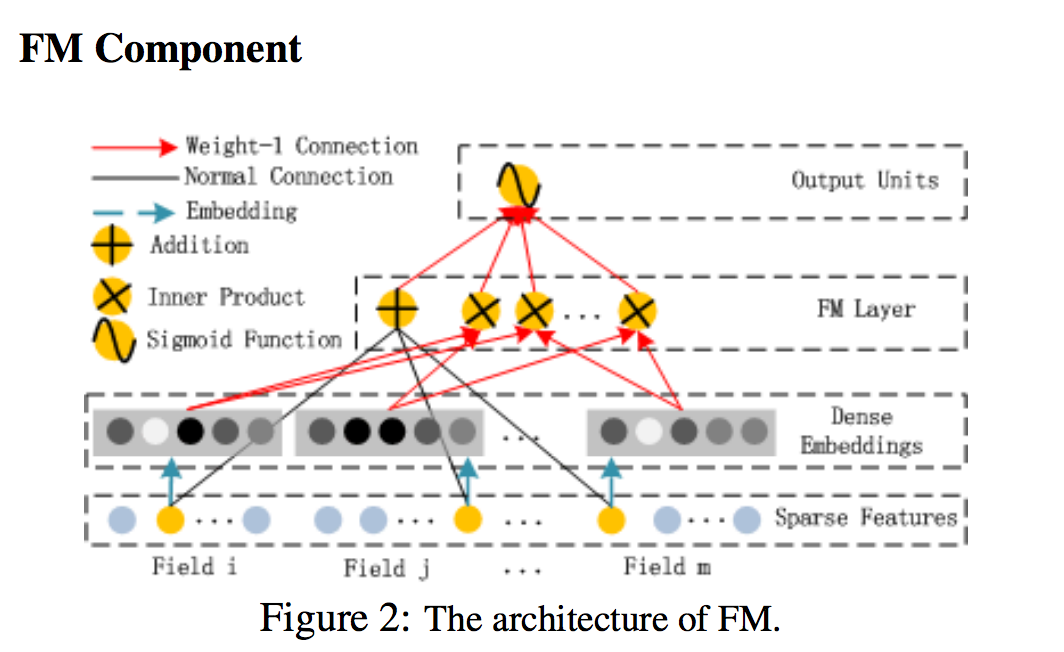
- FM 구성 요소는 [Rendle, 2010] 추천 시스템을 위해서 기능 상호 작용을 배우기 위해 제안된 factorization machine
- 기능 간의 선형 (차수 1) 상호 작용 외에도 FM 모델은 쌍방향 (차수 2) 상호 작용을 각각의 피쳐 잠재 벡터의 내부 곱으로 특징으로 함
- 데이터 세트가 희박할 때 이전 접근법보다 훨씬 효과적으로 주문 order 2 Feature 상호 작용을 캡처할 수 있음
- 이전 접근법에서 피쳐 i와 피쳐 j의 상호 작용 매개 변수는 피쳐 i와 피쳐 j가 모두 동일한 데이터 레코드에 나타날 때만 훈련 될 수 있음
- FM에서 latent 벡터 Vi와 Vj의 내부 곱을 통해 측정됨. 이 유연한 디자인 덕분에 FM은 데이터 레코드에 i (또는 j)가 나타날 때마다 잠재 벡터 Vi (Vj)를 훈련시킬 수 있음
- 따라서 훈련 데이터에 나타나지 않거나 거의 나타나지 않는 기능 상호 작용은 FM에서 더 잘 학습됩니다.
- 그림 2가 보여 주듯이, FM의 출력은 추가 단위와 다수의 내부 제품 단위의 합
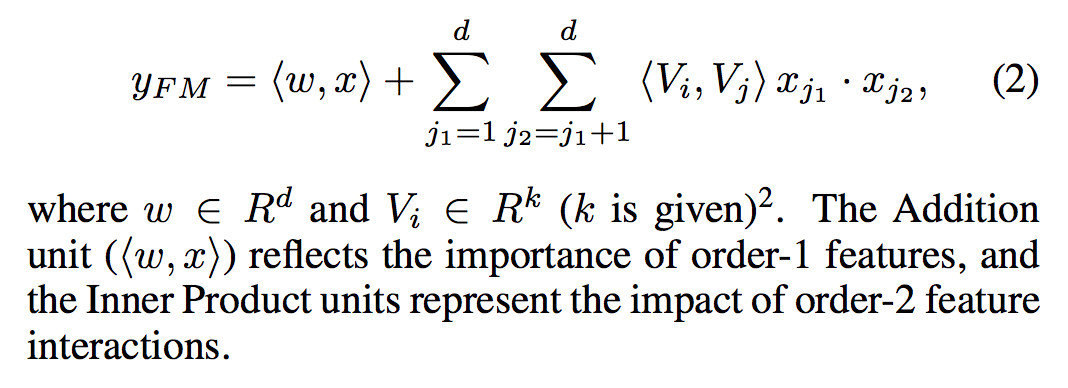
- 모든 수치에서 검정색의 정규 연결은 학습할 weight와의 연결을 의미함.
- 파란색 대시 화살표는 학습할 잠재 벡터를 의미
- 장치의 출력은 두 개의 입력 벡터의 곱. 함수는 CTR 예측에서 출력 함수로 사용됨. relu 및 tanh와 같은 활성화 함수는 신호를 비선형으로 변환하는 데 사용됨
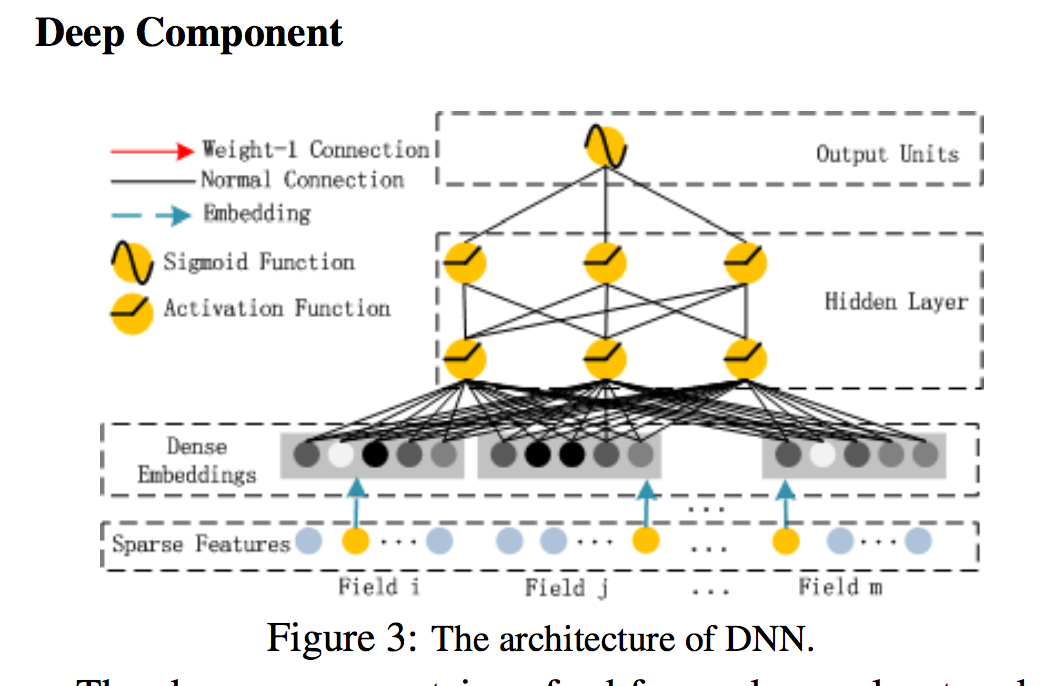
- DNN 요소는 피드 포워드 신경망으로 고차 기능 상호 작용을 배우는 데 사용됨
- 그림 3에서 볼 수 있듯이 데이터 레코드(벡터)가 신경망에 학습. 순전히 연속적이고 밀도가 높은 입력으로 이미지 [He et al., 2016] 또는 오디오 [Boulanger-Lewandowski et al., 2013] 데이터를 가진 신경망과 비교할 때 CTR 예측의 입력은 매우 다르므로 새로운 네트워크 아키텍처 설계가 필요합니다.
- 특히, CTR 예측을 위한 원시 피쳐 입력 벡터는 일반적으로 매우 희박하고, 초고차원, 범주형 연속 혼합 및 필드 (예 : 성별, 위치, 연령)로 그룹화됨
- 입력 벡터를 첫 번째 숨겨진 레이어로 더 인풋하기 전에 저차원의 고밀도 실수 값 벡터로 압축하기 위한 임베딩 레이어를 제안
- 그림 4는 입력 계층에서 임베딩 계층까지 하위 네트워크 구조를 강조 표시함
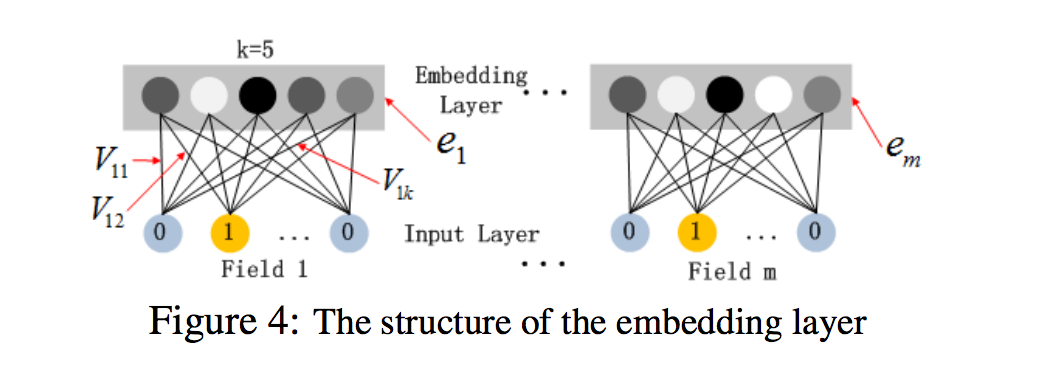
- 이 네트워크 구조의 두 가지 흥미로운 특징
- 1) 서로 다른 입력 필드 벡터의 길이가 다를 수 있지만 임베딩은 동일한 크기 (k)
- 2) FM의 잠재 피쳐 벡터 (V)는 이제 서버에서 입력 필드 벡터를 임베딩 벡터로 압축하는 데 사용되는 네트워크 가중치로 사용됩니다. [Zhang et al., 2016]
- V는 FM에 의해 사전 훈련되고 초기화로 사용됨
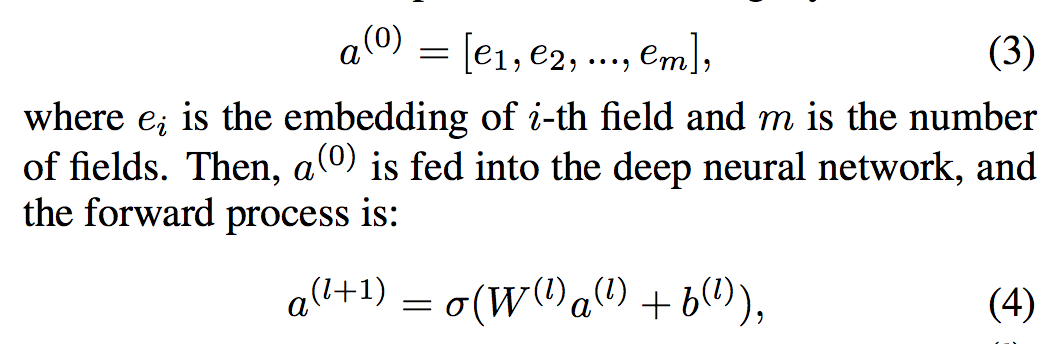
- 작업에서 [Zhang et al., 2016]에서와 같이 네트워크를 초기화하기 위해 FM의 잠재 피쳐 벡터를 사용하는 대신 다른 DNN 모델 외에도 전반적인 학습 아키텍처의 일부로 FM 모델을 포함합니다
- 따라서 FM에 의한 사전 훈련의 필요성을 제거하고 대신 전체 네트워크를 End to End 방식으로 훈련시킴
- FM 구성 요소와 딥 구성 요소는 동일한 기능 임베딩을 공유하므로 두 가지 중요한 이점을 제공
- 1) 원시 기능에서 low 및 high 기능 상호 작용을 모두 배웁니다.
- 2) Wide & Deep [Cheng et al., 2016]에서 요구되는대로 입력의 전문가의 기능 엔지니어링이 필요하지 않음
2.2 Relationship with the other Neural Networks
- 다양한 응용 분야에서의 딥러닝 학습의 엄청난 성공에서 영감을 얻은 CTR 예측을 위한 몇 가지 딥러닝 모델이 최근에 개발되었음
- 해당 섹션에서는 제안된 DeepFM을 CTR 예측을 위한 기존 딥러닝 모델과 비교
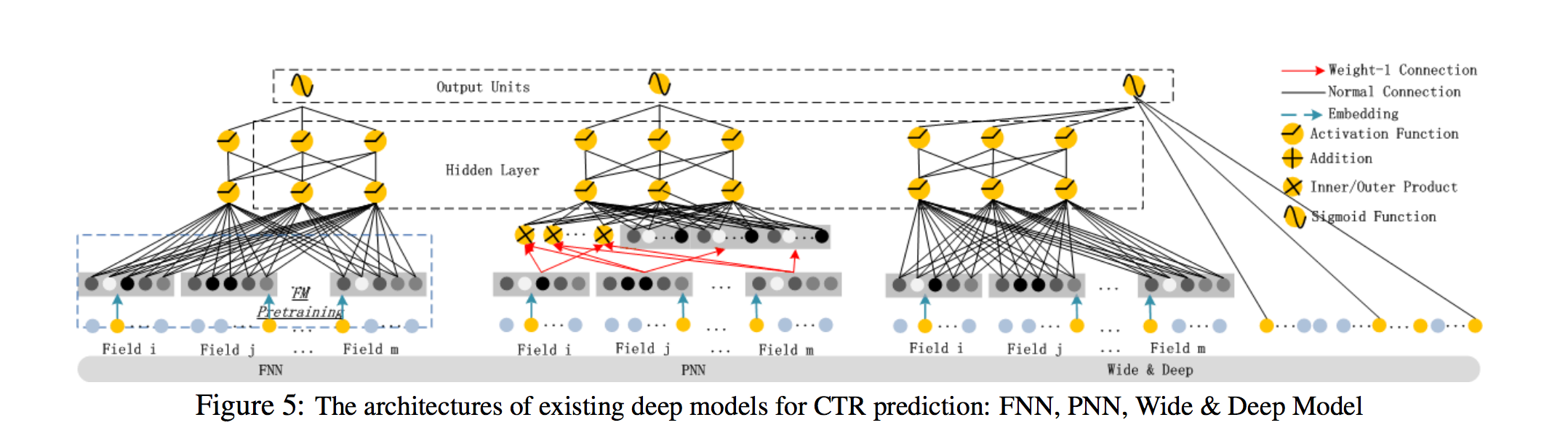
- FNN : 그림 5 (왼쪽)가 보여 주듯이, FNN은 FM 초기화된 피드 포워드 신경망 [Zhang et al., 2016]입니다.
- FM 사전 훈련 전략은 두 가지 제한을 초래함
1) 임베딩 매개 변수가 FM의 영향을 받을 수 있음 2) 사전 훈련 단계에서 도입된 오버 헤드에 의해 효율성이 감소됨- 또한 FNN은 고차 피쳐 상호 작용만 캡처
- 대조적으로 DeepFM은 사전 훈련을 필요로 하지 않으며 고차 및 저차 기능 상호 작용을 모두 학습
- PNN : 고차 피쳐 상호 작용을 포착하기 위해 PNN은 임베딩 레이어와 첫 번째 숨겨진 레이어 [Qu et al., 2016] 사이에 Product 레이어 추가.
- PNN (다양한 유형의 제품 작동)에 따르면 IPNN, OPNN 및 PNN의 세 가지 변형이 있음
- IPNN은 벡터의 Inner 곱을 기반으로 하며 OPNN은 Outer 곱을 기반으로 하며 PNN은 Inner 및 Outer 곱을 기반으로 함
- 계산을 보다 효율적으로 하기 위해 저자는 Inner Product과 Outer Product의 근사 계산을 제안함
- 1) Inner Product은 일부 뉴런을 제거하여 대략 계산
- 2) Outer Product은 m k-차원 피쳐 벡터를 하나의 k 차원 벡터로 압축하여 대략 계산
- Outer Product의 근사 계산은 결과를 불안정 하게 만드는 많은 정보를 잃어 버리기 때문에 Outer Product이 Inner Product 보다 신뢰성이 낮다는 것을 알게됨
- Inner Product이 더 신뢰할 만하지만, output of the product layer이 첫 번째 숨겨진 층의 모든 뉴런에 연결되어 있기 때문에 여전히 높은 계산 복잡성을 겪음
- PNN과 달리 DeepFM의 Product layer 출력은 최종 출력 계층(하나의 뉴런)에만 연결됨
- FNN과 마찬가지로 모든 PNN은 low-order 피쳐 상호 작용을 무시
Wide & Deep
- Google에서 Low 및 High 기능 상호 작용을 동시에 모델링하기 위해 제안됨
- “Wide” 부분에 대한 입력에 대한 전문가의 기능 엔지니어링이 필요로 함 (예 : 앱 권장 사항의 사용자 설치 앱 및 인상 앱의 교차 제품)
- 대조적으로, DeepFM은 입력 원시 기능에서 직접 학습하여 입력을 처리할 수 있는 전문가 지식이 필요하지 않음
- 이 모델의 직접적인 확장은 LR을 FM으로 대체하는 것 (3 절에서이 확장을 평가합니다
- 이 확장은 DeepFM과 유사하지만 DeepFM은 FM과 DNN 구성 요소 사이에 피쳐를 임베딩
- 피쳐 임베딩 영향 (역전파 방식으로)의 공유 전략은 표현을 보다 정확하게 모델링 하는 low 피쳐 상호 작용에 의한 피쳐 표현을 제공
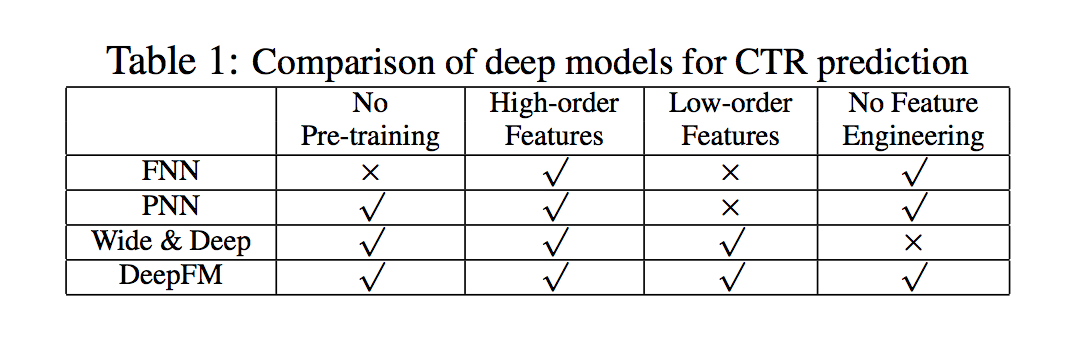
- 요약하면 DeepFM과 다른 Deep learning 모델 간의 관계는 표 1에 나와있음
- 보다시피 DeepFM은 사전 훈련 및 피쳐 엔지니어링이 필요없는 유일한 모델이며 low 및 High 피쳐 상호 작용을 모두 캡처
3. Experiments
- 이 섹션에서는 제안된 DeepFM과 다른 최첨단 모델을 경험적으로 비교
- 평가 결과는 제안된 DeepFM이 다른 최첨단 모델보다 효과적이며 DeepFM의 효율성은 다른 모델보다 우수한 모델과 유사하다는 것을 나타냄
3.1 Experiment Setup Datasets
-
다음 두 데이터 세트에서 제안된 DeepFM의 효율성과 효율성을 평가함
- 1) Criteo Dataset : Criteo 데이터 세트 5에는 4 천 5 백만 명의 사용자 클릭 기록이 포함됨
- 13개의 연속적인 특징과 26개의 범주형 특징
- 데이터 세트를 무작위로 두 부분으로 나눔. 90%는 훈련용이고 나머지 10% 는 테스트용
- 2) Company * Dataset 세트
- 실제 산업 CTR 예측에서 DeepFM의 성능을 확인하기 위해 회사 데이터 세트에 대한 실험을 수행
- 컴퍼니 앱 스토어의 게임 센터에서 7일 연속 사용자 클릭 기록을 수집하고 다음 날에는 테스트를 위해 수집
- 수집된 전체 데이터 세트에는 약 10억 개의 기록이 있음
- 데이터 세트에는 앱 기능 (예 : 식별, 범주 등), 사용자 기능 (예 : 사용자의 다운로드 된 앱 등) 및 컨텍스트 기능 (예 : 작동 시간 등)이 있습니다.
- 평가 측정법
- 실험에서 AUC (ROC 넓이)와 Logloss (교차 엔트로피)의 두 가지 평가 메트릭을 사용합
- 모델 비교 우리는 LR, FM, FNN, PNN (3 가지 변형), Wide & Deep 및 DeepFM과 같은 실험에서 9 가지 모델을 비교합니다.
- Wide & Deep 모델에서는 피쳐 엔지니어링 노력을 없애기 위해 LR을 FM으로 대체하여 원래의 와이드 앤 딥 모델을 넓은 부분으로 채택
- Wide & Deep의 두 변종된 모델을 구별하기 위해 각각 LR&DNN과 FM&DNN이라는 이름을 붙임
- 매개변수 설정
- Criteo 데이터 세트의 모델을 평가하기 위해 FNN 및 PNN의 매개 변수 설정을 따름
- (1) dropout 0.5, (2) network structure 400-400-400
- (3) optimizer Adam (4) activation function IPNNN의 경우 tanh, 다른 딥러닝 모델의 경우 relu
- 공정하게 말하자면, 제안된 DeepFM은 동일한 설정을 사용
- LR과 FM의 optimizer는 각각 FTRL과 Adam이며 FM의 잠재 차원은 10입니다.
- 회사 데이터 세트의 각 개별 모델에 대한 최상의 성능을 달성하기 위해 3.3절에서 논의한 신중한 매개변수 연구를 수행
3.2 Performance Evaluation
- 두 데이터 세트의 섹션 3.1에 나열된 모델을 평가하여 효율성과 효율성을 비교, 딥러닝 학습 모델의 효율성은 실제 응용 프로그램에 중요함
- Criteo 데이터 세트의 다른 모델의 효율성을 다음과 같은 공식으로 비교함 (ㅣtraining time of deep CT R modelㅣ / ㅣ training time of LRㅣ)
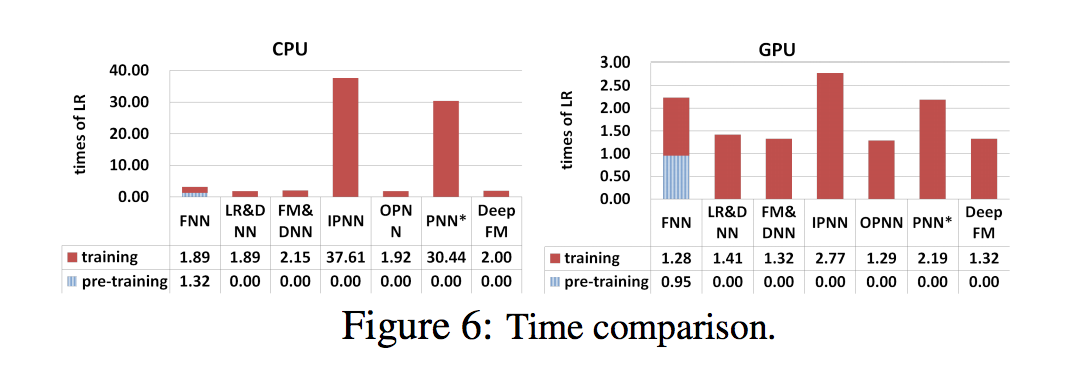
- 결과는 CPU (왼쪽) 및 GPU (오른쪽)에 대한 테스트를 포함하여 그림 6에 나와있음
- 1) FNN의 사전 훈련으로 인해 효율성이 떨어짐
- 2) IPNN 및 PNN의 속도가 다른 모델보다 높지만 GPU의 속도는 여전히 계산 비용이 많이 듦, 비효율적인 inner 제품 작업
- 3) 가장 효율적인 DeepFM을 달성
- Criteo 데이터 세트 및 회사 데이터 세트에 대한 CTR 예측 성능은 표 2에 나와 있음
- 학습 기능 상호 작용은 CTR 예측 모델의 성능을 향상시킴. 이 관찰은 LR (기능 상호 작용을 고려하지 않는 유일한 모델)이 다른 모델보다 성능이 저하된다는 사실에서 비롯된 것
- 최고의 모델로서 DeepFM은 회사 및 Criteo 데이터 세트에서 AUC (Logloss 측면에서 1.15 % 및 5.60 %) 측면에서 LR을 0.86 % 및 4.18 % 능가
- 고차 및 저차 피쳐 상호 작용을 동시에 배우고 CTR 예측 모델의 성능을 적절하게 향상시킵니다
- DeepFM은 저차 피쳐 상호 작용 (즉, FM) 또는 고차 피쳐 상호 작용 (즉, FNN, IPNN, OPNN, PNN)만을 배우는 모델보다 성능이 뛰어납니다.
- 두 번째로 좋은 모델과 비교하여 DeepFM은 회사 및 Criteo 데이터 세트에서 AUC (Logloss 측면에서 0.42 % 및 0.29 %) 측면에서 0.37 % 이상과 0.25 % 이상을 달성합니다.
- 고차 및 저차 기능 상호 작용을 동시에 학습하면서 고차 및 저차 기능 상호 작용을 위해 동일한 기능을 공유하면 CTR 예측 모델의 성능이 향상됩니다.
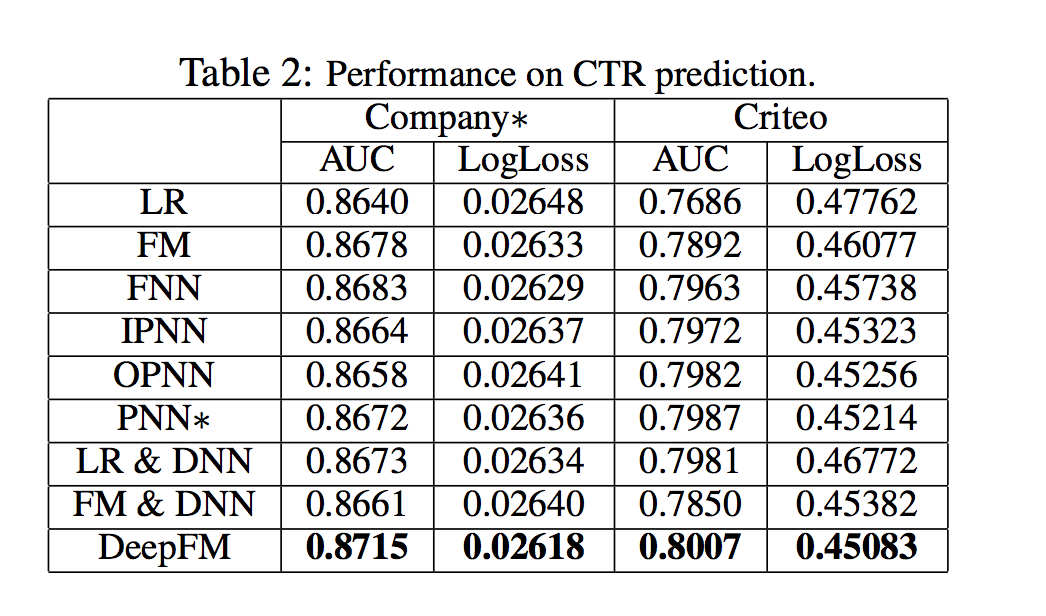
- DeepFM은 별도의 기능 임베딩(LR & DNN 및 FM & DNN)을 사용하여 고차 및 저차 기능 상호 작용을 배우는 모델보다 성능이 뛰어납니다.
- 이 두 모델과 비교하여 DeepFM은 회사 및 Criteo 데이터 세트에서 AUC (Logloss 측면에서 0.61 % 및 0.66 %) 측면에서 0.48 % 이상 및 0.33 % 이상을 달성합니다.
- 전반적으로, 제안된 DeepFM 모델은 AUC 및 Logloss on Company 데이터 세트 측면에서 각각 0.37 % 및 0.42 % 이상 경쟁 모델을 이김
- 사실 오프라인 AUC 평가가 약간 개선되면 온라인 CTR이 크게 증가할 수 있음
- [Cheng et al., 2016]에서 보고한 바와 같이 LR과 비교하여 Wide & Deep은 AUC를 0.275 % (오프라인) 향상시키고 온라인 CTR의 개선은 3.9 %입니다.
- 컴퍼니 앱스토어의 일일 매출은 수백만 달러이므로 CTR의 리프트는 매년 수백만 달러를 추가로 제공함
3.3 Hyper-Parameter Study
- 다양한 딥러닝 모델의 다양한 하이퍼 매개 변수가 회사 데이터 세트에 미치는 영향을 연구
-
순서는 다음과 같음
- 1) 활성화 기능
- 2) Dropout
- 3) number of neurons per layer
- 4) number of hidden layers
- 5) network shape
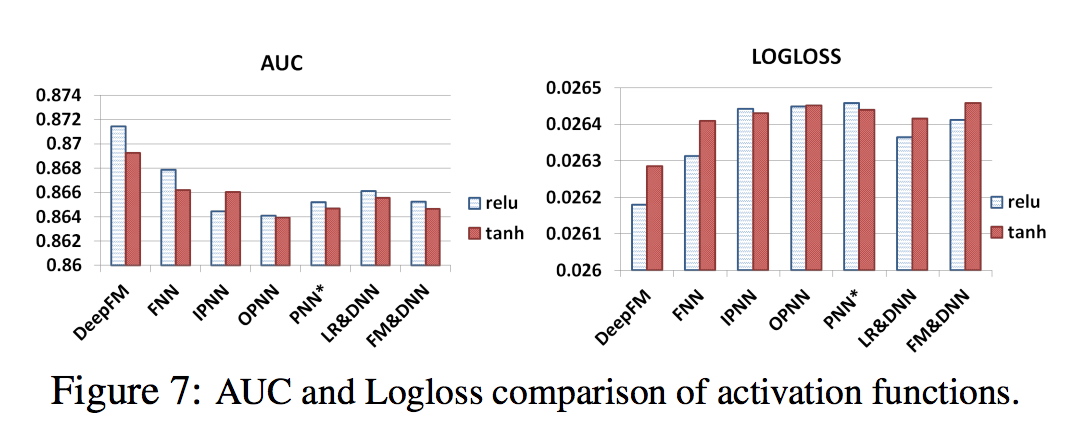
- [Qu et al., 2016]에 따르면, relu와 tanh는 시그모이드보다 Deep Learning 모델에 더 적합함
- 이 논문에서 relu와 tanh를 적용할 때 딥 모델의 성능을 비교합니다.
- 그림 7에서 볼 수 있듯이 relu는 IPNN을 제외한 모든 딥 모델에 대해 tanh보다 적합합니다. 가능한 이유는 Relu 함수가 희박함을 유도한다는 것
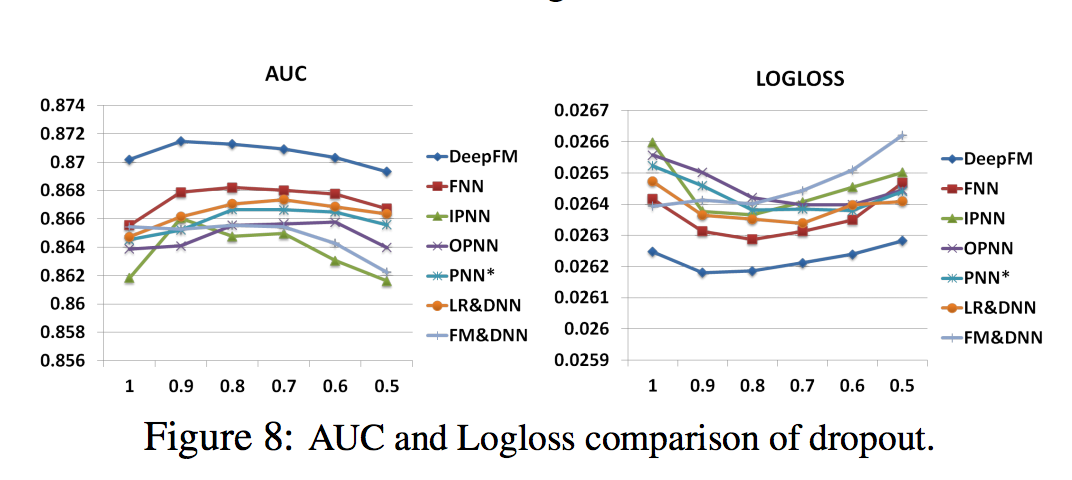
- Dropout [Srivastava et al., 2014]는 뉴런이 네트워크에 유지 될 확률을 나타냄
- Dropout은 신경망의 정밀도와 복잡성을 손상시키는 정규화 기술
- Dropout를 1.0, 0.9, 0.8, 0.7, 0.6, 0.5로 설정했다. 그림 8에서 볼 수 있듯이, 모든 모델은 Dropout이 적절하게 설정되면 (0.6에서 0.9까지) 최고 성능에 도달할 수 있음
- 결과 모델에 합리적인 무작위성을 추가하면 모델의 견고성이 강화될 수 있음을 보여줌
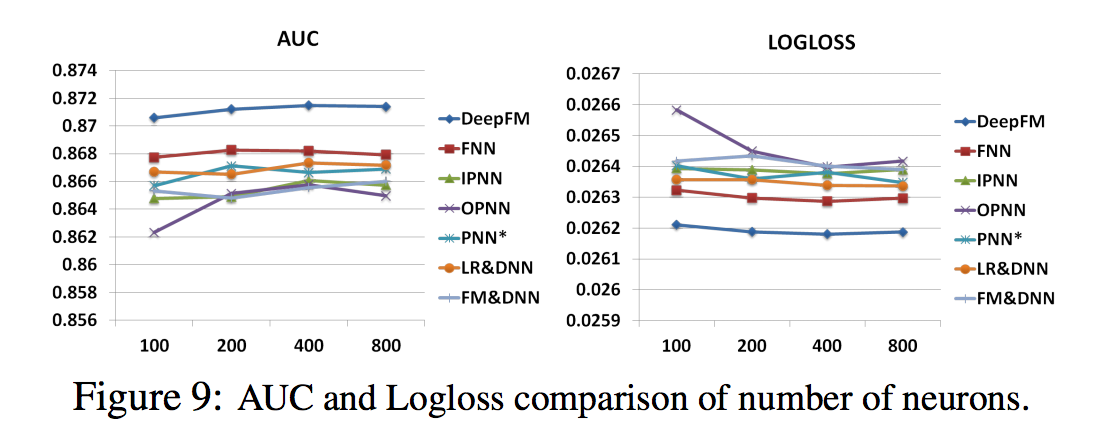
- 다른 요인들이 동일하게 유지될 때, 층당 뉴런의 수를 증가시키는 것은 복잡성을 초래
- 그림 9에서 볼 수 있듯이 뉴런의 수를 늘리면 항상 이득을 얻을 수는 없음
- 예를 들어, DeepFM은 층 당 뉴런 수가 400에서 800으로 증가할 때 안정적으로 수행됨
- 더 나쁜 것은 OPNN이 뉴런 수를 400에서 800으로 늘릴 때 더 나쁜 결과를 나타냄, 지나치게 복잡한 모델이 과도하게 적합하기 쉽기 때문. 데이터 세트에서 레이어당 200개나 400개의 뉴런이 좋은 선택
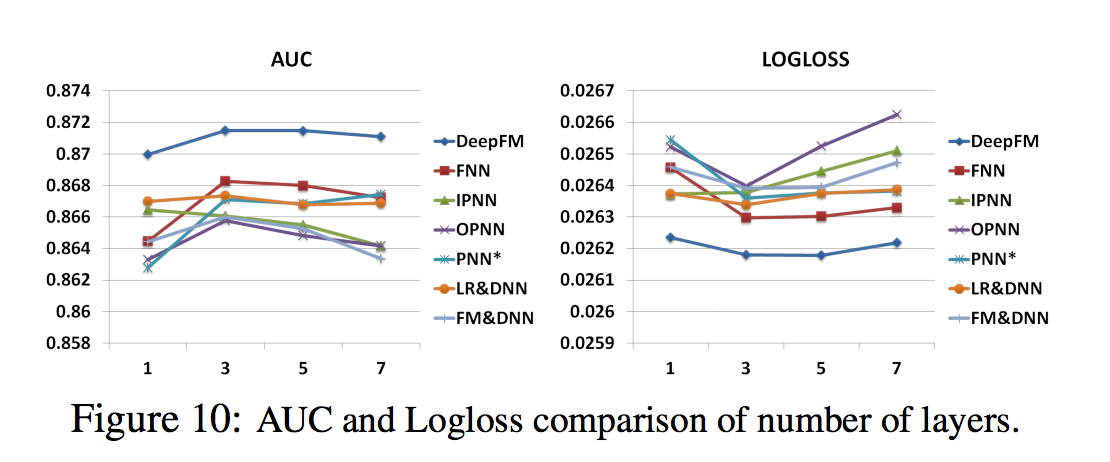
- 그림 10에 제시된 숨겨진 계층의 수는 숨겨진 계층의 수가 증가함에 따라 처음에는 모델의 성능이 향상되지만 숨겨진 계층의 수가 계속 증가하면 성능이 저하. 현상은 또한 과적합 때문에 일어난다
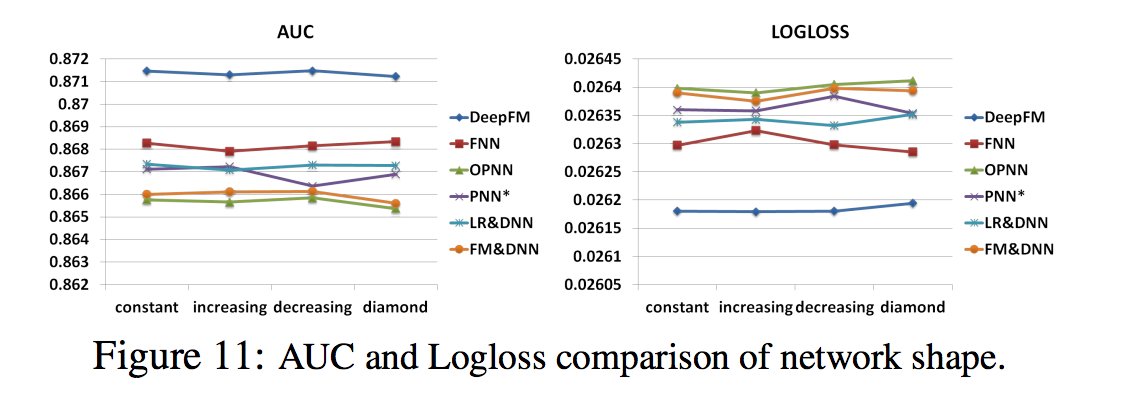
- 네트워크 형상은 constant, increasing, decreasing, diamond 등 네 가지 네트워크 모양을 테스트
- 네트워크 모양을 변경하면 숨겨진 레이어의 수와 뉴런의 총 수를 수정
- 예를 들어, 숨겨진 층의 수가 3이고 뉴런의 총 수가 600일 때 상수 (200-200-200), 증가 (100-200-300), 감소 (300-200-100), 다이아몬드 (150-300- 150)
- 그림 11에서 볼 수 있듯이, ‘constant’ 네트워크 형태는 이전 연구와 일치하는 다른 세 가지 선택사항보다 경험적으로 더 좋음
4. Related Work
- 논문에서 CTR 예측을 위해 새로운 Deep learning이 제안됨. 가장 관련있는 도메인은 추천 시스템에서 CTR 예측 및 Deep learning
- 1절과 2.2절에서는 CTR 예측을 위한 몇 가지 깊은 학습 모델이 이미 언급되어 있기 때문에 그에 대해 논의하지 않음
- CTR 예측 이외의 추천시스템 과제에는 몇 가지 Deep learning 모델이 제안되어 있음
- 예를 들어, [Covington et al., 2016; Salakhutdinov et al., 2007; van den Oord et al., 2013; Wu et al., 2016; Zheng et al., 2016; Wu et al., 2017; Zheng et al., 2017). [Salakhutdinov et al., 2007; Sedhain et al., 2015; Wang et al., 2015]는 딥러닝 학습을 통해 협업 필터링을 개선할 것을 제안
- [Wang and Wang, 2014; van den Oord et al., 2013]는 음악 추천의 성능을 향상시키기 위해 딥러닝 학습을 통해 컨텐츠 기능을 추출
- [Chen et al., 2016]은 이미지 기능과 디스플레이 광고의 기본 기능을 모두 고려하기 위해 딥러닝 네트워크를 고안
- [Covington et al., 2016]은 YouTube 비디오 추천을 위한 2 단계 딥러닝 학습 프레임 워크를 개발
5. Conclusions
- 이 논문에서 CTR 예측을 위한 Factorization-Machine 기반 신경망인 DeepFM을 제안하여 최첨단 모델의 단점을 극복하고 더 나은 성능을 달성했음
- DeepFM은 딥러닝 구성 요소와 FM 구성 요소를 공동으로 학습
- 1) 사전 훈련이 필요하지 않습니다
- 2) 고차 및 저차 기능 상호 작용을 모두 배웁니다
- 3) 피쳐 엔지니어링을 피하기 위해 피쳐 임베딩의 공유 전략을 소개합니다.
- Deep FM과 최첨단 모델의 효율성과 효율성을 비교하기 위해 두 개의 실제 데이터 세트(크리테오 데이터셋과 상업용 앱 스토어 데이터 세트)에 대한 광범위한 실험을 실시
- 1) DeepFM이 두 데이터 세트에서 AUC 및 Logloss 측면에서 최첨단 모델보다 성능이 뛰어났다는 것을 보여줍니다.
- 2) DeepFM의 효율성은 최첨단에서 가장 효율적인 딥 모델과 비교할 수 있습니다
- 미래 연구를 위한 두 가지 흥미로운 방향이 있음
- 하나는 가장 유용한 고차원 기능 상호 작용을 학습하는 능력을 강화하기 위해 일부 전략 (예 : 풀링 레이어를 도입하는 것)을 탐구하는 것
- 다른 하나는 대규모 문제를 위해 GPU 클러스터에서 DeepFM을 훈련시키는 것




댓글남기기