
이전 포스트 바로가기
BERT(Bidirectional Encoder Representations from Transformers)
- 논문 바로가기
- 소스코드 바로가기
- medium 연재기사
-
이렇게 어려운 SQuAD 2.0 task와 데이터셋이 발표되고 몇 달 지나지 않은 2018년 말 현재, SQuAD 리더보드에는 인간 수준에 근접하는 성능을 보이는 모델들이 다수 올라와 있습니다. 그 중 최상위권에서 공통적으로 모이는 모델은 ‘BERT(Bidirectional Encoder Representations from Transformers)’입니다. 아래 사진은 10위까지만 캡쳐하였지만 10위권 아래로도 한참 동안 ‘+BERT’라는 모델명은 이어집니다

- BERT는 2018년 10월 구글 AI Language팀에서 발표한 범용 언어 학습 방식으로, 기존 모델들은 사람이 언어를 인지하는 방향인 순방향(left-to-right)을 학습하게 되므로 좌우측의 문맥을 모두 고려하려면 순방향과 역방향(right-to-left)의 벡터를 단순 결합(concat)시켜야 하는 등 한계가 존재했는데 이를 해결하고 진정한 양방향(bi-directional) 학습을 하기 위한 새로운 시도를 하였다는 점에서 큰 의의가 있습니다. 또한 실제로 11개의 세부 NLP task에서 현존 최고 수준의 성능을 기록하기도 했습니다.
- 본 연구에서 새롭게 제안한 두 가지의 접근법은 페이퍼만 읽어서는 이해가 잘 되지 않을 수 있습니다. Reddit에 본 논문의 저자가 직접 작성한 아래의 글을 읽어보면 이들의 생각을 좀더 잘 파악할 수 있습니다
저자의 글(Reddit)
- 원문 링크: thread의 가장 위에 있는 글임
안녕하세요 저는 본 페이퍼의 메인 저자입니다. 기본 아이디어는 매우 단순합니다. 수년 동안 사람들은 사전학습(pre-training)된 DNN을 언어 모델로 사용하고 미세 튜닝(fine-tuning)하여 질의 응답, 자연어 추론, 감성 분석 등 다양한 downstream1 NLP task에서 좋은 결과를 얻어 왔습니다.
언어 모델은 일반적으로 left-to-right입니다. 예를 들어,
"남자는 가게에 갔다" ("the man went to a store")
P(the | <s>)*P(man | <s> the)*P(went | <s> the man)*...
문제는 일반적으로 세부 task의 경우 여러분은 언어 모델 만드는 것을 원하는 게 아니라 그 특정 상황(context)에 맞는 특정 단어의 상황별 언어 표현을 원한다는 것입니다. 각 단어가 왼쪽의 맥락만 볼 수 있다면 분명히 많은 것이 누락될 것입니다. 그래서 사람들이 사용한 트릭 중 하나는 오른쪽에서 왼쪽으로도 모델을 훈련시키는 것입니다.
P(store|</s>)*P(a|store </s>)*...
이제 여러분은 각 단어들에 대해 두 개의 언어 표현을 가지게 됩니다. 하나는 왼쪽에서 오른쪽으로, 다른 하나는 오른쪽에서 왼쪽으로, 그리고 세부 task를 위해 이들을 연결(concatenation)하여 사용합니다
하지만 직관적으로는 양방향성이 강한(deeply bi-directional)단일 모델을 훈련시키는 것이 훨씬 더 낫습니다.
불행히도 일반적인 LM과 같은 깊게 양방향성을 지닌 모델을 훈련시키는 것은 불가능합니다. 이는 단어들이 간접적으로 “자기 자신을 바라보는(see themselves)” 사이클을 만들어 예측이 비정상적으로(trivial) 발생할 수 있기 때문입니다.
대신 우리가 할 수 있는 것은 입력에서 단어의 일부분을 mask하고(가림, 바꿈) 문맥 내에서 해당 단어를 재구성하는 데 사용되는, de-noising auto-encoder라 불리는 매우 간단한 트릭입니다. 우리는 이것은 ‘masked LM’이라고 부르지만 종종 ‘Cloze task’라고도 불립니다.
- Task 1: Masked LM 2
Input:
the man [MASK1] to [MASK2] store
Label:
[MASK1] = went; [MASK2] = a
특히 우리는 입력 값을 deep Transformer encoder에 넣고 가려진(masked) 위치에 해당하는 최종 hidden states를 사용하여 가려진(masked) 단어를 예측합니다. 이는 언어모델을 학습시키는 방식과 동일합니다.
LM에서 빠진 또 다른 것은, 많은 NLP task에서 중요하게 다루어져야 하는 문장 간의 관계를 이해하지 못한다는 것입니다. 문장 관계 모델을 사전학습(pre-train)시키기 위해 우리는 매우 간단한 이진 분류 task를 사용합니다. 이 작업은 두 문장 A와 B를 연결하고 B가 원문 텍스트에서 A 다음에 실제로 오는지 예측하는 것입니다.
- Task 2: Next Sentence Prediction
Input:
the man went to the store [SEP] he bought a gallon of milk
Label:
IsNext
Input:
the man went to the store [SEP] penguins are flightless birds
Label:
NotNext
그런 다음 우리는 많은 텍스트를 통해 매우 큰 모델을 훈련시켰습니다 (Wikipedia + 일부 NLP 연구자가 작년에 공개적으로 발표 한 무료 전자책 모음을 사용했습니다). downstream task에 적용(adapt)하려면 당신은 몇 번의 epoch 동안 당신의 task에 맞게 레이블을 미세 튜닝하면 됩니다.
이렇게 함으로써 우리는 우리가 시도한 모든 NLP 작업에 대해 SOTA보다 상당히 큰 개선을 얻었고, 우리의 모델은 task-specific한 변화를 거의 필요로 하지 않았습니다.
하지만 우리에게 정말 놀랍고 예상하지 못했던 결과는 우리가 큰 모델에서(12 Transformer blocks, 768-hidden, 110M parameters)3 정말정말 큰 모델로 변화시킬 때(24 Transformer blocks, 1024-hidden, 340M parameters)4 아주 작은 데이터 세트(작은 = 5,000개 미만의 레이블이 붙은 예)에서도 엄청난 개선이 이루어졌다는 점입니다.
우리는 또한 실제로 다음 2-3 주 이내에 주요 결과를 복제하는 푸시 버튼과 사전 훈련된 모델, 코드를 100% 공개할 것입니다. (단일 GPU에서 미세 튜닝을 반복하는 데 최대 몇 시간이 걸립니다).
페이퍼 리뷰를 준비하며
- 논문을 본격적으로 읽기 전에 주요 용어를 번역한 한국어 단어와, 관련된 참고자료를 아래에 모아 보았습니다
주요 용어 번역
- (language) representation: 언어 표현
- pre-train(ing): 사전 학습
- pre-trained representation: 사전 학습된 언어표현
- fine-tuning: 미세 튜닝(‘미세 조정’이라는 용어로도 번역되지만 어감상 저는 ‘미세 튜닝’이라고 번역했습니다)
- unidirectional: 일방향의
- bidirectional: 양방향의
- Transformer (model): 트랜스포머 모델
관련 주요 용어 & 참고 자료
- pre-trained model
- 유사한 문제를 해결하기 위해 만들어진 다른 모델. 처음부터 모델을 작성하는 대신 다른 유사한 문제에 대해 훈련된 모델을 출발점으로 사용하는 것
- 특정 task에 대한 데이터셋만으로 모든 언어에 대한 복잡한 관계를 학습하기는 어려우므로 사전학습된 모델에 자신의 데이터셋을 미세 튜닝해서 사용하게 됨
- 참고 링크
- fine-tuning
- ELMo(Embeddings from Language Model)
- 논문 링크
- 본 연구에서는 feature-based 모델의 예시로 비교되었음
- OpenAI GPT(Generative Pre-trained Transformer)
- 논문 링크
- 본 연구에서는 fine-tuning 모델의 예시로 비교되었음
Paper review
Abstract
- 저자들은 BERT(Bidirectional Encoder Representations from Transformers)라는 새로운 언어 표현(representation) 모델을 제안하였습니다. 기존 모델들과 달리 BERT는 깊은 양방향의 언어 표현(deep bidirectional representation)을 모든 레이어에 있어서 좌우측 문맥 모두에 결합적인(jointly) 조건으로 사전학습 하도록 설계되었습니다
- 사전학습 된 BERT representation은 하나의 추가적인 output 레이어를 통해 사전학습 될 수 있습니다
Introduction
- 사전 학습된 언어 표현을 세부 task에 적용하는 방법은 크게 두 가지가 있었습니다. 바로 ‘feature-based’와 ‘fine-tuning’입니다
- 자질 기반의(feature-based) 접근: ELMo(Peters et al., 2018) - 사전 학습된 representation을 추가적인 자질로서 특정 task에 대한 구조에 사용
- 미세 튜닝fine-tuning) 접근: GPT(Generative Pre-trained Transformer; Radford et al., 2018) - 특정 task에 대한 변수(parameter)를 최소화한 채 특정 task에 대한 모델은 사전학습 모델에서 변수(parameter)들을 fine-tuning함으로써 이루어집니다
- 선행 연구들에서는 두가지 접근법 모두 사전학습 단계에서는 동일한 목적함수를 공유합니다. 이 때 일반적인(general) 언어 표현을 학습하기 위해 일방향의 언어 모델을 사용하게 됩니다
- 저자들은 특히 fine-tuning 접근법의 경우 기존의 이러한 기법들이 사전 학습된 언어 표현의 힘을 심각하게 제한하고 있다는 점을 지적합니다
- 표준 언어 모델이 일방향이라는 점이 사전학습 단계에서 사용될 수 있는 모델 구조(architecture)를 선택하는 데 제한이 됨
- 예를 들어 OpenAI GPT의 저자들은 트랜스포머 모델의 self-attention 레이어에서 모든 토큰들이 이전 토큰들에 의해서만 다루어질 수 있는 좌측에서 우측(left-to-right) 구조를 사용
- 이러한 제한점들은 문장 단위의 task에서 차선책의 일환이었으며, fine-tuning 기반의 접근법을 SQuAD 질의응답처럼 토큰 레벨의 task에 적용할 때 완전히 무너질 수 있음. 양방향의 문맥이 모두 고려되어야 하기 때문
- 본 논문에서 저자들은 fine-tuning 접근법의 성능을 향상시킬 수 있는 BERT를 제안. BERT는 새로운 사전학습 목적을 제시함으로써 위에 언급한 일방향성 제약을 해소하고자 하였습니다
- 가려진 언어 모델(masked language model(MLM))
- Cloze task에서 영향 받음
- 무작위로 input 토큰 중 일부를 가리고, 그 문맥만을 이용해서 가려진 단어의 id를 예측
- 왼쪽에서 오른쪽(left-to-right) 언어 모델 사전학습과 달리 MLM objective는 깊은 양방향 트랜스포머 모델을 학습함으로써 왼쪽과 오른쪽 맥락을 융합시킬 수 있음
- 다음 문장 예측(next sentence prediction)
- 텍스트 쌍 언어 표현을 결합하여 사전학습 할 수 있게 함
- 문장 간의 관계를 반영할 수 있게 됨
- 가려진 언어 모델(masked language model(MLM))
- 저자들이 뽑은 본 논문의 기여점은 아래와 같습니다
- 언어 표현에 있어서 양방향 사전학습의 중요성을 증명함
- 사전 학습된 언어 표현은 특정 task를 목적으로 무겁게 제작된 모델 구조의 필요성을 없애준다는 것을 증명
- BERT 모델은 11개의 NLP task에 대해 현존 최고 수준을 보임
BERT
Model Architecture
- 선행연구(Vaswani et al., 2017)5에 기술된 모델 기반의 양방향 트랜스포머 인코더(bidirectional Transformer encoder)
- 최근 트랜스포머 모델의 사용이 매우 흔해졌고 우리의 모델 적용은 원본과 아주 똑같으므로 본 논문에서는 구조 설명을 생략함
- 여기서는 레이어의 개수(예를 들어 트랜스포머 블록)를 로, 은닉(hidden) 사이즈를 로, self-attention을 로 표기
- 모든 경우에 저자들은 feed-forward/filter 사이즈를 로 설정(예를 들어, H=768이면 3072, H=1024이면 4096). 두 가지 모델 사이즈에 따라 결과를 각각 제시하고자 하였음
- :
- :
- 는 비교를 위해 OpenAI GPT와 동일한 사이즈로 선택되었습니다. 하지만 중요한 것은 GPT Transformer가 모든 토큰이 그 왼쪽의 것에 의해서만 다루어지는 GPT Transformer와 달리 BERT 트랜스포머 모델은 양방향 self-attention을 사용한다는 점입니다
- 본 논문에서 ‘양방향 트랜스포머 모델(bidirectional Transformer)’ 종종 ‘Transformer encoder’로, 왼쪽 맥락만 고려하는 버전은 ‘Transformer decoder’로 지칭됩니다
- text generation에 사용될 수 있기 때문
- BERT, OpenAI GPT, ELMo의 비교는 아래 그림과 같습니다

Input Representation
- 본 논문에서 입력 representation은 하나의 토큰 시퀀스로, 개별 문장 또는 문장 쌍(예를 들어 [질문, 답]) 두 가지를 모두 명료하게 재현할 수 있습니다. 여기에서 ‘sentence’라는 용어는 실제 언어적 ‘문장’이 아닌, 인접한 텍스트에서의 임의의 구간을 뜻할 수 있습니다. ‘sequence’는 BERT에 대한 input 토큰 시퀀스를 지칭하는데, 이는 개별 sentence일 수도 두 sentence가 하나로 묶인 것일 수도 있습니다
-
주어진 토큰에 대해 상응하는 토큰, 세그먼트, 위치 임베딩을 합하여 구성됩니다. 아래 그림을 참고하세요
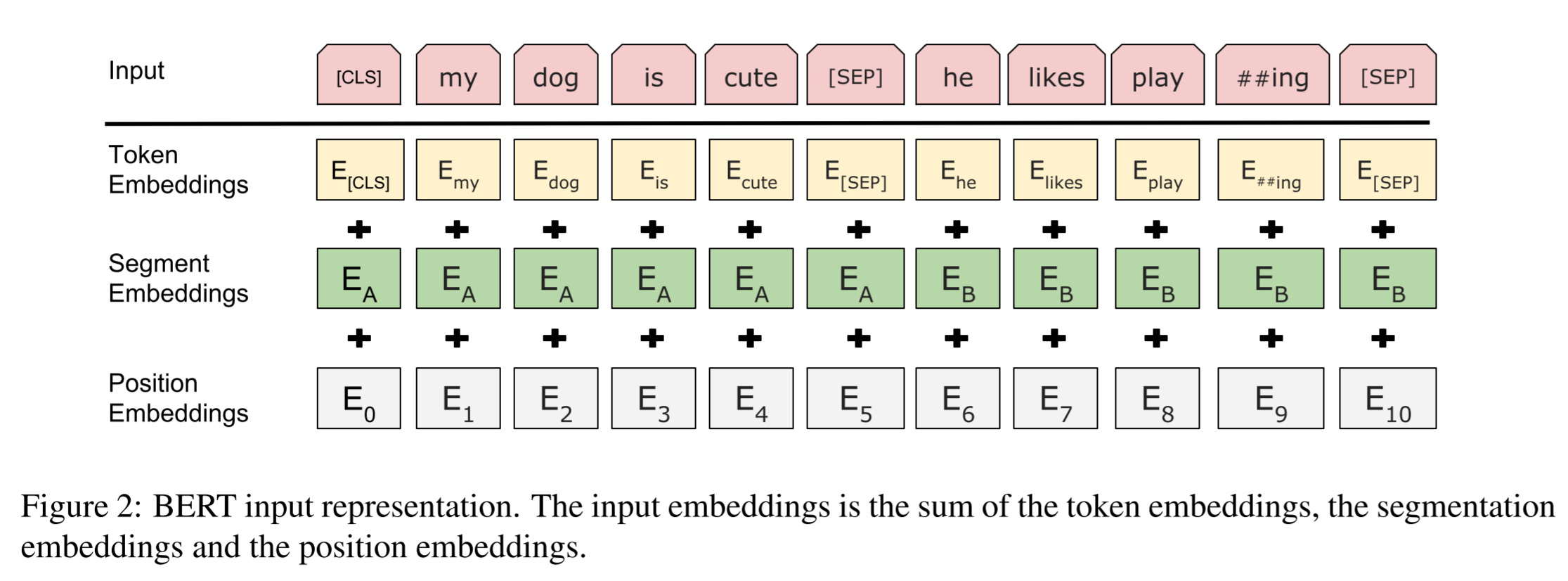
- 좀더 세부적으로 살펴보면 아래와 같습니다
- 저자들은 30,000개 토큰 사전과 WordPiece 임베딩을 사용(Wu et al., 2016). 분할된 단어 조각(split word piece)들을
##으로 표기 - 학습된 위치 임베딩을 길이 512 이하의 supported 시퀀스와 함께 사용
- (classification embedding): 모든 시퀀스의 첫번째 토큰으로 특수한 분류 임베딩. 이 토큰에 상응하는 최종 hidden states(예를 들어 Transformer의 output)는 분류 task를 위한 총(aggregate) 시퀀스 representation으로 사용됨. 분류 task가 아닌 경우 이 벡터는 무시됨
- : sentence 쌍이 하나의 시퀀스로 묶임. 저자들은 이 문장들을 두 가지 방법으로 차별화함
- 특수한 토큰 으로 이들을 분리
- 학습된 문장 임베딩을 첫번째 문장의 모든 토큰에 더하고 문장 임베딩을 두번째 문장의 모든 토큰에 더해 줌
- 개별 문장 input의 경우 문장 의 임베딩만 사용
- 저자들은 30,000개 토큰 사전과 WordPiece 임베딩을 사용(Wu et al., 2016). 분할된 단어 조각(split word piece)들을
Pre-training Tasks
3.3.1 Task #1: Masked LM
- 직관적으로 생각했을 때, 깊은 양방향 모델이 단방향 모델이나 양쪽 방향을 각각 학습하여 연결한 얕은 기법보다 더 강력하다고 충분히 생각할 수 있습니다
- 그러나 일반적인(standard) 언어 모델은 양방향 조건이 다중 레이어 상황에서는 자기 자신을 바라보는 사이클이 생길 수 있기 때문에 왼쪽에서 오른쪽 또는 오른쪽에서 왼쪽 둘 중 한 방향으로만 학습할 수 있습니다
- masked LM(MLM)
- 가려진(masked) 토큰들에 상응하는 최종 은닉 벡터들은 일반적인 LM으로써 어휘에 대한 output softmax에 반영됩니다
- 저자들은 실험에서 전체 WordPiece 토큰 중 15%를 무작위로 가림
- ‘denoising auto-encoder(Vincent et al., 2008)’과 반대로 본 연구에서는 전체 input을 재구성하는 게 아니라 가려진 단어들만 예측
- 이를 통해 양방향 pre-trained 모델을 얻을 수 있었으나 두 가지 불리한 면이 존재
- 토큰이 fine-tuning 단계에서 전혀 나타나지 않기 때문에 pre-training과 fine-tuning 간 부조화 발생
- 이를 완화하기 위해 본 연구에서는 항상 “가려지는” 단어들을 토큰으로 대체하지 않고 학습 데이터 생성기가 무작위로 15%의 토큰을 선택하도록 함
- 예를 들어
my dog is hairy라는 문장에서hairy가 선택되었다고 해 보자. 생성기는 선택된 단어를 항상 로 대체하지 않고 아래와 같은 과정을 거친다
- 80%: 단어를 토큰으로 대체(예를 들어
my dog is hairy→my dog is [MASK]) - 10%: 단어를 랜덤한 다른 단어로 대체(예를 들어
my dog is hairy→my dog is apple) - 10%: 단어를 변화 없이 그대로 유지(예를 들어
my dog is hairy→my dog is hairy). 이것의 목적은 representation이 실제 관찰된 단어에 대한 편향을 갖게 하려는 것 - Transformer encoder는 어떤 단어를 예측하도록 지시받을 지, 어떤 단어가 랜덤한 다른 단어로 대체될 지 알 수 없으므로 모든 input 토큰에 대한 distributional contextual representation을 가지고 있어야 함 - 또한 무작위 대체가 전체 토큰 중 단 1.5%에서만 발생하기 때문에(예를 들어 15%의 10%) 이는 모델의 언어 이해 능력에 해를 끼치지 않음
- 모델이 수렴하기 위해 더 많은 pre-training 스텝이 요구될 수 있는 각 배치에서 토큰의 15%만 예측된다는 점
- 본 논문의 5.3 섹션에서 저자들은 MLM이 모든 토큰을 예측하는 왼쪽에서 오른쪽 모델에 비해 아주 조금 느리게 수렴한다는 것을 보였음
- 하지만 MLM 모델의 실증적인 성능 향상은 학습 cost의 증가를 능가한다고 할 수 있음
- 토큰이 fine-tuning 단계에서 전혀 나타나지 않기 때문에 pre-training과 fine-tuning 간 부조화 발생
3.3.2 Task #2: Next Sentence Prediction
- 질의응답이나 추론 등 많은 중요한 task들은 언어 모델에서 바로 잡히지 않는, 두 텍스트 sentence의
관계를 이해하는 데 기반을 두고 있습니다 - 문장 관계를 이해하는 모델을 학습하기 위해 저자들은 어떠한 단일 언어 말뭉치에서도 생성할 수 있는 이원화된
next sentence predictiontask를 pre-train 하였습니다 - 특히 문장 와 를 각각 pre-training 샘플로 선정할 때, 의 50%는 실제 의 다음에 오는 문장으로, 50%는 말뭉치 내의 문장들 중 랜덤하게 선정하였습니다.
상세한 예는 아래와 같습니다
-
Input = [CLS] the man went to [MASK] store [SEP] he bought a gallon [MASK] milk [SEP] Label = IsNext -
Input = [CLS] the man went to [MASK] store [SEP] penguin [MASK] are flight ##less birds [SEP] Label = NotNext
-
3.4 Pre-training Procedure
- 사전학습 절차는 기존의 언어 모델 사전학습 연구 논문들을 상당 부분 따랐습니다
- 사전학습 말뭉치(corpus)로 저자들은
BookCorpus(Zhu et al., 2015)(약 800억 단어)와English Wikipedia(약 25억 단어)를 병합한 것을 사용했습니다- 위키피디아에서는 텍스트 본문만 추출했으며 리스트, 표, 헤더 등은 무시
- 긴 연속되는 시퀀스를 뽑아내기 위해,
Billion Word Benchmark(Chelba et al., 2013)처럼 무작위로 섞인 문장 단위 말뭉치가 아니라 문서 단위의 말뭉치를 사용
- 각각의 학습 input 시퀀스를 생성하기 위해 저자들은 말뭉치에서
sentences라고 부르는 두개씩의 텍스트 구간을 샘플링했습니다. 여기서sentence는 실제 대화에서의 단일 문장보다 훨씬 길 수도, 짧을 수도 있습니다. - 첫번째
sentence는 임베딩을 받고 두 번째sentence는 임베딩을 받습니다. ‘다음 문장 예측’ task를 위해 중 50%는 실제로 다음에 연결되는 인접sentence이고 나머지 50%는 랜덤하게 추출됩니다. 이들은 병합된(combined) 길이가 512 토큰을 넘지 않는 길이에서 샘플링됩니다 - LM 마스킹(masking)은 WordPiece 토큰화(tokenization) 다음에 15%의 균일한 마스킹 비율로 수행되었고, 각 work piece들에는 특별히 무언가가 고려되지는 않았습니다
- 저자들은 256 시퀀스(256 시퀀스 * 512 토큰 = 128,000 토큰/배치)에 1,000,000 스텝으로 학습을 했는데
이는 대략 33억 단어의 말뭉치에 대해 40번의 epoch가 돌아가게 됩니다
- Adam 사용(learning rate: , : 0.9, : 0.999, L2 weight decay: 0.01)
- dropout probability: 모든 레이어에서 0.1
- OpenAI GPT와 동일하게
gelu(Hendrycks and Gimpel, 2016) activation 사용 - training loss: (mean masked LM likelihood + 다음 문장 예측 likelihood)
- 학습 환경과 소요된 시간은 아래와 같았습니다
- : Pod 설정된 4대의 Cloud TPU(총 16개의 TPU 칩 사용)에서 4일 소요
- : Pod 설정된 16대의 Cloud TPU(총 64개의 TPU 칩 사용)에서 4일 소요
3.5 Fine-tuning Procedure
- 시퀀스 단위의 분류 task를 위한 BERT의 미세 튜닝은 직관적입니다.
SQuAD task에 적용
- input 질의와 단락을 하나의 packed sequence로 표현합니다(A: question embedding, B: paragraph embedding). fine-tuning 과정에서 학습되는 것은 시작 벡터인 와 끝 벡터인 뿐입니다
- input 토큰에 대한 BERT의 최종 hidden 벡터는 로 나타냅니다
- 단어 i가 정답 범위의 시작 지점일 확률은 와 사이의 내적으로 계산되고 단락의 모든 단어에 대해 softmax가 계산됩니다
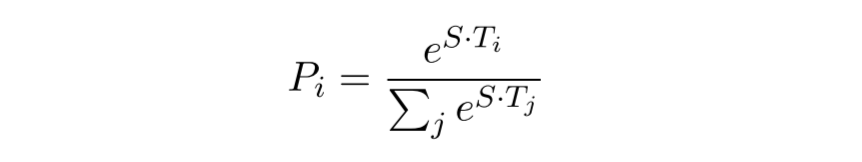
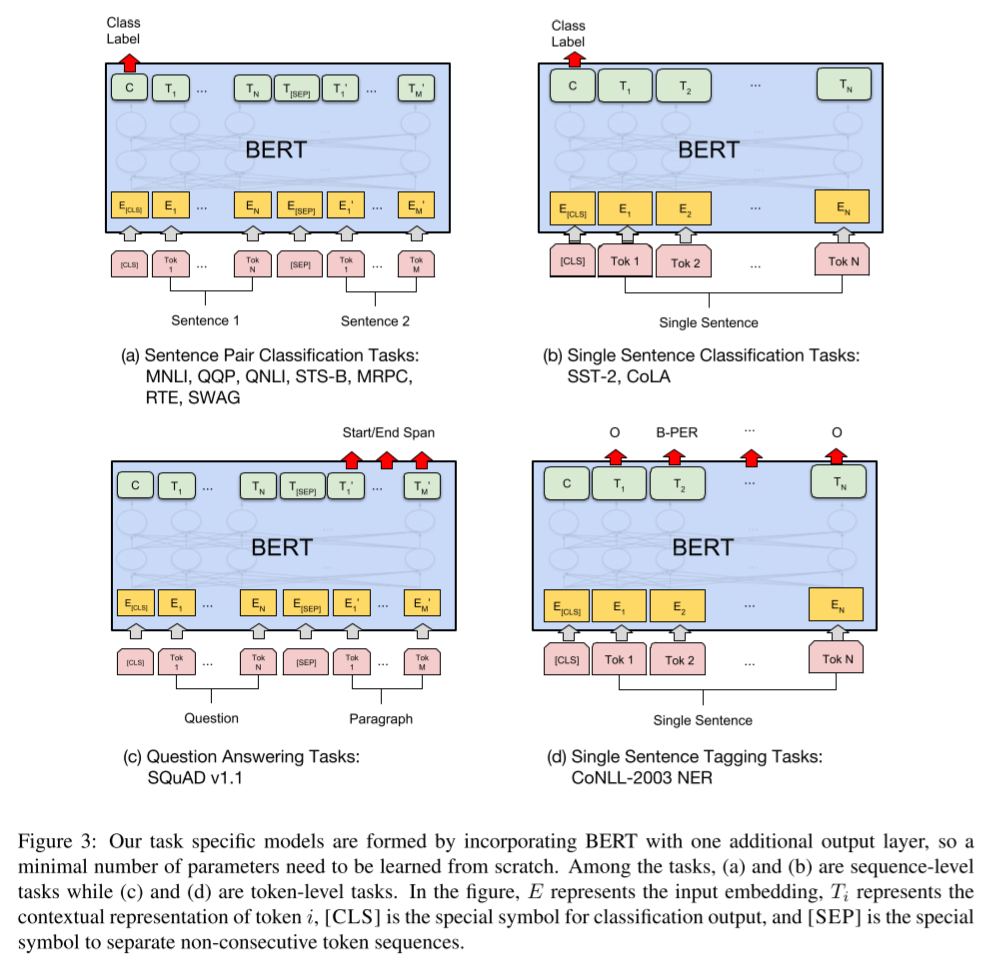
- 특정 task에 적용된 BERT 모델 형태 비교는 아래와 같습니다. 그림(c)를 참고하면 됩니다.
- 응답 범위의 끝 부분에도 동일한 수식이 사용되며 가장 결과값이 큰 위치가 예측으로 사용됩니다. 훈련 목표는 올바른 시작 및 끝 위치의 log-likelyhood입니다.
- epoch 3, learning rate 5e-5, batch size 32로 학습
- 아래는
SQuAD 1.1task에 대한 성능을 비교한 것입니다





댓글남기기