
SQuAD 2.0 paper review
Abstract
- ‘extractive reading comprehension system’들은 본문 내에서 질문에 대한 정확한 답을 찾아주기도 하지만 제대로 된 답이 본문에 없을 경우에는 부정확한 추측을 리턴하기도 합니다
- 현존하는 reading comprehension 데이터셋들은 주로 ‘answerable(대답 가능한)’ 질문들에 초점을 맞추거나 쉽게 판별이 가능한 가짜 ‘unanswerable(대답 불가능한)’ 질문들을 자동 생성해 왔습니다
- 우리는 이러한 약점을 보강하고자
SQuAD 2.0(Stanford Question Answering Dataset)데이터셋을 공개합니다 SQuAD 2.0은 아래와 같은 특징이 있습니다- 기존 데이터셋(
SQuAD 1.1)에 새로운 5만 개 이상의 unanswerable questions(응답 불가능한 질문)를 병합 - unanswerable question은 온라인의 crowd worker들이 직접 생성(즉, 기계적으로 생성된 것이 아니라 진짜 인간이 생성했으므로 질이 더 높음)
- worker들에 의해 생성된 unanswerable question은 응답 가능한 질문들과 유사하여 기계적으로 판별이 어려움
- 기존 데이터셋(
- 이제 task가 단순히 정답이 가능할 때만 리턴하는 것이 아니라, 주어진 본문에 정답이 없는 경우도 그 여부를 리턴하는 것으로 좀더 어려워지게 되었습니다
SQuAD 1.1에서 F1 86%를 기록했던 신경망 기반의 시스템이SQuAD 2.0데이터셋에서는 F1 66%를 기록했습니다
1. Introduction
- ‘Machine reading comprehension(기계 독해)’는 이하의 다양한 데이터셋 공개에 힘입어
자연언어 이해(natural language understanding) 분야에서 핵심적인 task 중 하나가 되어 왔습니다
- Hermann et al., 2015
- Hewlett et al., 2016
- Rajpurkar et al., 2016
- Nguyen et al., 2016
- Trischler et al., 2017
- Joshi et al., 2017
- 또 반대로 이러한 데이터셋은 이하의 다양한 모델 발전에서 영향을 받아 왔습니다
- Seo et al., 2016
- Hu et al., 2017
- Wang et al., 2017
- Clark and Gard-ner, 2017
- Huang et al., 2018
- 특히 최근에는
SQuAD 1.1데이터셋을 이용해 인간의 정확도 수준을 상회하는 기계독해 시스템들이 만들어지기도 하였습니다 - 그럼에도 불구하고 이러한 시스템들은
진짜(true)언어 이해에서 아직도 상당 수준 떨어져 있다고 할 수 있습니다. 시스템들은SQuAD데이터셋에서 잘 작동한다는 것이 확인되었으나 문장 분리에서 안정성(robustness)을 보이지는 못했기 때문입니다. - 이러한 이유 중 하나는
SQuAD는 정확한 답이 주어진 context 내에 존재할 것이라고 가정하였기 때문입니다. 그러므로 모델은 정답이 정말 본문에 존재하는지 여부를 따지기보다는 가장 답에 근접해보이는 구절(span)을 찾는 데 집중하게 됩니다 - 본 연구에서 저자들은 기존의 응답 가능한(answerable) 질문들에 53,775개의 응답 불가능한(unanswerable) 질문들을 병합한 새로운
SQuAD 2.0데이터셋을 공개했습니다- 응답 불가능한 질문들은 응답 가능 질문들과 동일한 본문(paragraphs)에서 제작됨
- 질문 제작에는 온라인의 다수 crowd worker들을 사용하였음
- 현존 최고 수준의 모델을
SQuAD 2.0을 이용해 학습시킨 결과, 인간의 정확도가 F1 89.5%인 반면 시스템은 이에 한참 못 미치는 F1 66.3%를 기록했습니다. 동일한 모델을SQuAD 1.1에서 학습시키고 테스트한 결과 인간 수준보다 단 5.4%밖에 차이나지 않는 85.8%의 F1을 기록했습니다 - 저자들은 진짜 인간이 제작한 자신들의 응답 불가능 질문들이 distant supervision(Clark and Gardner, 2017) 또는 rule-based 기법으로(Jia and Liang, 2017) 자동 생성된 응답 불가능 질문들보다 더 어렵다는 것을 증명하였습니다
- 저자들은
SQuAD 2.0데이터셋을 대중에 공개하고 리더보드에서 실시간으로 순위가 매겨질 수 있도록 하였습니다
2. Desiderata 1
- 저자들은 새로운 데이터셋 제작 프로젝트에 있어 일반적인 ‘대용량(large size)’, ‘다양성(diversity)’ 또는 ‘적은 노이즈(low noise)’ 외에도
응답 불가능 질문(unanswerable question)에 대해 아래 두 가지 요구사항(desiderata)를 정의하였습니다
- 연관성(Relevance): 응답 불가능 질문들은 주어진 본문과 주제적으로 연관성이 있어야 함. 그렇지 않으면 단순한 휴리스틱으로도 응답 가능/불가능 여부를 판별할 수 있게 됨
- 그럴듯한 정답의 존재(Existence of plausible answers): 본문 내에 응답 불가능 질문이 요구하는 정답과 타입이 일치하는 그럴듯한 정답 구절이 포함되어 있어야 함. 예를 들어 ‘1992년에 설립된 회사는 무어인가?(What company was founded in 1992?)’라는 질문이 있을 경우 본문 내에 어떠한 회사명이 존재해야 함. 그렇지 않으면 타입 매칭(type-matching) 휴리스틱이 응답/가능 불가능 여부를 판별할 수 있기 때문
- 아래는 응답 불가능한 질문들의 예시

3. Existing datasets
- 저자들은 이러한 조건(criteria)들을 염두에 두면서 현존하는 다른 기계독해 데이터셋을 조사했습니다. 응답 불가능한 질문과 짝을 이루는 본문을 지칭하기 위해 ‘negative example’이라는 용어가 사용되었습니다
3.1 Extractive datasets
- 추출식 기계독해(extractive reading comprehension) 데이터셋들에서는 주어진 본문 내에서 시스템이 정답을 추출해 냅니다
- Zero-shot Relation Extraction dataset (Levy et al., 2017)
- TriviaQA (Joshi et al., 2017)
- 또다른 distance supervision approach
- 각 질문에 대한 context 본문을 웹이나 위키피디아에서 검색해 사용하였는데, 이렇게 수집된 본문 중 일부는 정답이 포함되어 있지 않아 negative example이 됨. 하지만 이것들은(negative example) 최종 데이터셋에는 포함되지 않았음
- negative examples for SQuAD (Clark and Gardner, 2017)
- 기존에 있던 질의를 TF-IDF 오버랩 기반으로 동일한 문서(article)의 다른 단락에 매핑
- 일반적으로 distant supervision은 검색된 context에서 그럴듯한 대답의 존재를 보장하지 않으며 오히려 주어진 context에 정답의 의역이 포함될 수 있으므로 잡음을 추가할 수도 있습니다. 또한 클라크와 가드너(2017)에서처럼 가능한 작은 맥락에서 검색할 때 검색된 단락은 종종 질문과 관련이 없으므로 이러한 부정적인 예를 쉽게 식별할 수 있습니다.
- NewsQA (Trischler et al., 2017)
- 데이터 수집 과정에서 crowdworker들이 기사 원문이 아닌 요약만 이용하여 질문을 작성하기 때문에 대답할 수없는 질문이 발생할 수는 있음
- 하지만 질문들 가운데 오직 9.5%만이 응답 불가능이므로 이 전략을 확장하기는 어려움
- 이 9.5% 중에서도 일부는 ‘응답 불가능’으로 잘못 표기된 것이었고 다른 일부는 범위 바깥(out-of-scope)으로 판정
- Jia and Liang (2017)은 SQuAD 질문을 약간 수정하여 규칙 기반의 응답 불가능 질문을 생성하는 방법을 제안합니다
- 개체(entity)와 숫자들을 유사한 단어로 대체하고 명사와 형용사를 WordNet의 반의어로 대체하는 단순한 방식
- 저자들은 이렇게 생성된 질문들을 규칙기반(RULEBASED) 질문이라고 지칭
3.2 Answer sentence selection datasets
- 정답 문장 선택 데이터셋(answer sentence selection)은 시스템이 질문에 답하는 문장을 그렇지 않은 문장보다 높게 순위를 매길 수 있는지 여부를 테스트합니다
- Wang et al. (2007): TREC 8-13 QA tracks의 질문들을 이용하여 QASent 데이터셋을 생성
- Yih et al. (2013): 어휘 기준선(lexical baselines)이 이러한 데이터셋에서 상당히 경쟁력이 있다는 것을 보임
- WikiQA (Yang et al., 2015): Bing 쿼리 로그상의 질의와 위키피디아의 문장들을 짝지어 묶습니다. TFIDF example과 마찬가지로 이 문장에는 진짜같은 응답 또는 질문과의 높은 의미적 연관성이 보장되지 않습니다. 또한 이 데이터셋은 양적으로도 제한적이었습니다. (3,047 질문, 1,473 답변).
3.3 Multiple choice dataset
- MCTest(Richardson et al., 2013) 또는 RACE (Lai et al., 2017) 같은 일부 데이터셋에서만 “정답 없음” 옵션을 가지는 복수정답 질문을 포함하고 있었습니다
- 실제로는 복수정답 옵션은 사용할 수 없는 경우가 많으므로 이러한 데이터 세트는 사용자 대면 시스템(user-facing system)을 학습하는 데 적합하지 않습니다
- 복수정답 질문은 추출식(extractive) 질문과는 상당히 다른 경향이 있으며, 빈칸 채우기, 해석 및 요약에 중점을 둡니다
4. SQuAD 2.0
- 이하에서는 앞서 ‘2. Desiderata’에서 정의한 두 가지 조건(relevance and plausible answer)을 충족하는 본 논문 저자들의
SQuAD 2.0데이터셋에 대한 설명을 다룹니다
4.1 Dataset creation
- 응답 불가능 질문을 생성하기 위해 저자들은 Daemo crowdsourcing platform (Gaikwad et al., 2015)에서 crowdworker를 고용했습니다
- 데이터 생성에는
SQuAD 1.1의 모든 본문이 사용되었습니다 - 본문의 각 문단마다 작업자들은 주어진 문단 단독으로는 대답할 수 없는 응답 불가능 질문들을 최대 5개까지 생성하도록 지시받았습니다. 이 과정에서 본문 내의 개체를 질문에 사용하고, 그럴듯한 진짜 질문이 존재하는지 여부를 확인하게 했습니다
- 생성을 돕기 위해 작업자들에게는 기존
SQuAD 1.1의 응답 가능 질문들이 참고로 제시되었습니다. 이를 통해 작업자들은 응답 불가능 질문을 더욱 진짜처럼 만들어낼 수 있었습니다 - 한 본문에서 25개 이하의 질문을 작성한 작업자의 질문들은 삭제되었습니다(필터링)
- task를 제대로 이해 못했을 가능성을 방지
- 제작 과정에서의 작업자 기준의 참고 사항은 아래와 같습니다
- 작업자들은 한 본문에서 7분씩 작업을 수행
- 작업자들은 시간 당 $10.05 의 보수를 받음
-
제작 UI는 아래와 같음

-
SQuAD 1.1에서 train, dev, test셋이 나누어진 기준과 동일한 본문들로 세 데이터셋을 나누고 그에 해당하는 질문들을 분할했습니다. 아래는 세 개의 데이터셋이 나누어진 비율입니다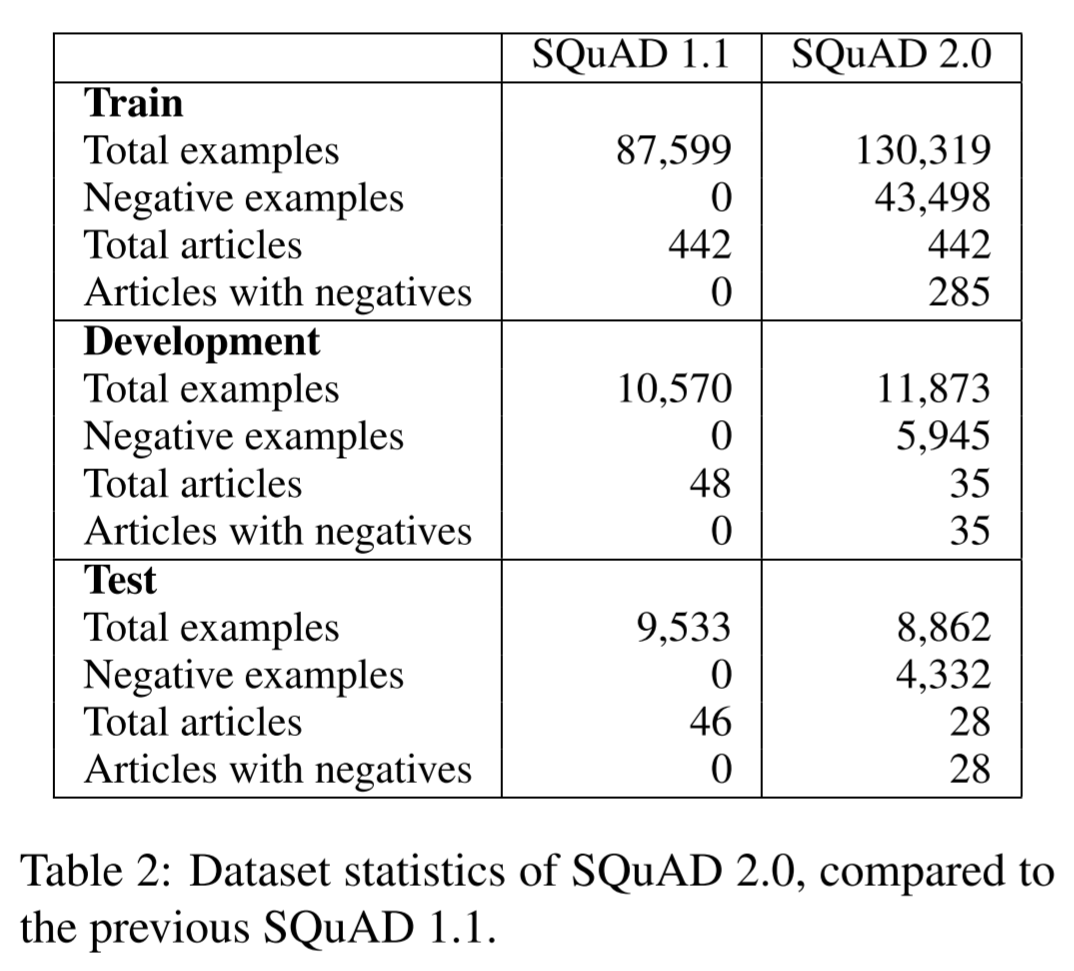
4.2 Human accuracy
- 데이터셋의 질을 확인하기 위해
SQuAD 2.0의 dev, test셋의 모든 질문에 답을 체크하는 또 다른 crowdworker를 고용했습니다 - 각 문단마다 해당하는 응답 가능/불가능 질문들을 무작위로 제시하였고, 작업자들은 응답 가능할 경우 본문에서 정답의 위치를 표시, 불가능할 경우는 ‘응답 불가능’으로 체크하도록 지시받았습니다
- 작업자들은 모든 문단들이 응답 가능 질문과 불가능 질문을 동시에 가지고 있다고 생각하도록 설명 받았습니다
- 작업자들은 각 질문마다 1분의 시간이 주어졌으며 시간 당 $10.50 의 보수를 지급받았습니다
- 작업자들의 노이즈를 줄이기 위해 복수의 작업자를 고용해 동일 질문에 대한 인간 응답을 여러 개 수집했습니다
- 최종 정답에는 많은 사람의 vote를 얻었거나 응답의 길이가 더 짧은 것이 선호됨
- 평균적으로 질문 1개 당 4.8개의 응답이 수집됨
4.3 Analysis
-
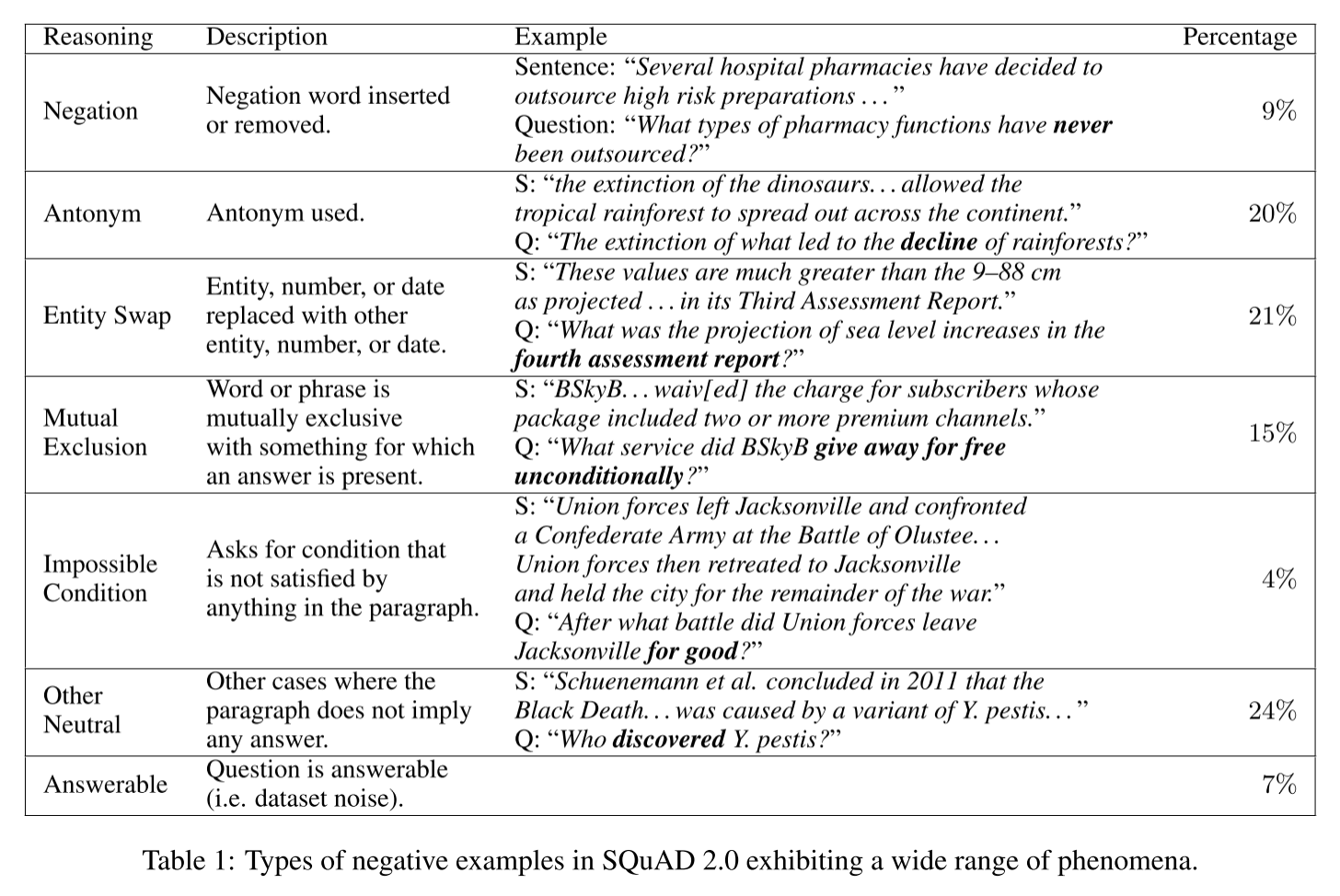
본 데이터셋이 가진 특성을 파악하기 위해 dev set에서 무작위로 100개의 negative example을 골라 수작업을 분석했습니다. negative example의 카테고리를 나누고 그 비중을 아래 표에 수록했습니다
5. Experiments
5.1 Models
- 실험에는 아래 모델들을 사용했습니다. 사용된 모델들은 모두 정답이 무엇인지 확률을 계산함과 동시에 응답을 할 수 없는 확률도 학습합니다
- BiDAF-No-Answer (BNA) (Levy et al., 2017)
- DocumentQA No-Answer (DocQA) (Clark and Gardner, 2017)
- DocQA + ELMo
5.2 Main results
- 아래는 실험의 주요 결과입니다. Table 3은
SQuAD 1.1과SQuAD 2.0에서 각 모델들의 결과를 표로 비교한 것입니다. DocQA+ELMo 모델이 가장 성능이 좋았지만 여전히 인간 수준에는 훨씬 미치지 못하는 수준을 보였습니다 -
Table 4는
SQuAD 2.0에서 사람이 직접 생성해 제작한 negative example들의 수준이 기존의 다른 데이터셋에서 TF-IDF 방식, 규칙기반 방식으로 제작된 것들에 비해 어떤 성능을 보이는지 비교하고자 한 것입니다.SQuAD 1.1에 자동 생성된 응답 불가능 질문들을 병합해 테스트한 결과SQuAD 2.0의 dev셋보다 약 20% 가량 성능이 높아져, 상대적으로SQuAD 2.0의 task가 더 어려운 것임을 확인할 수 있었습니다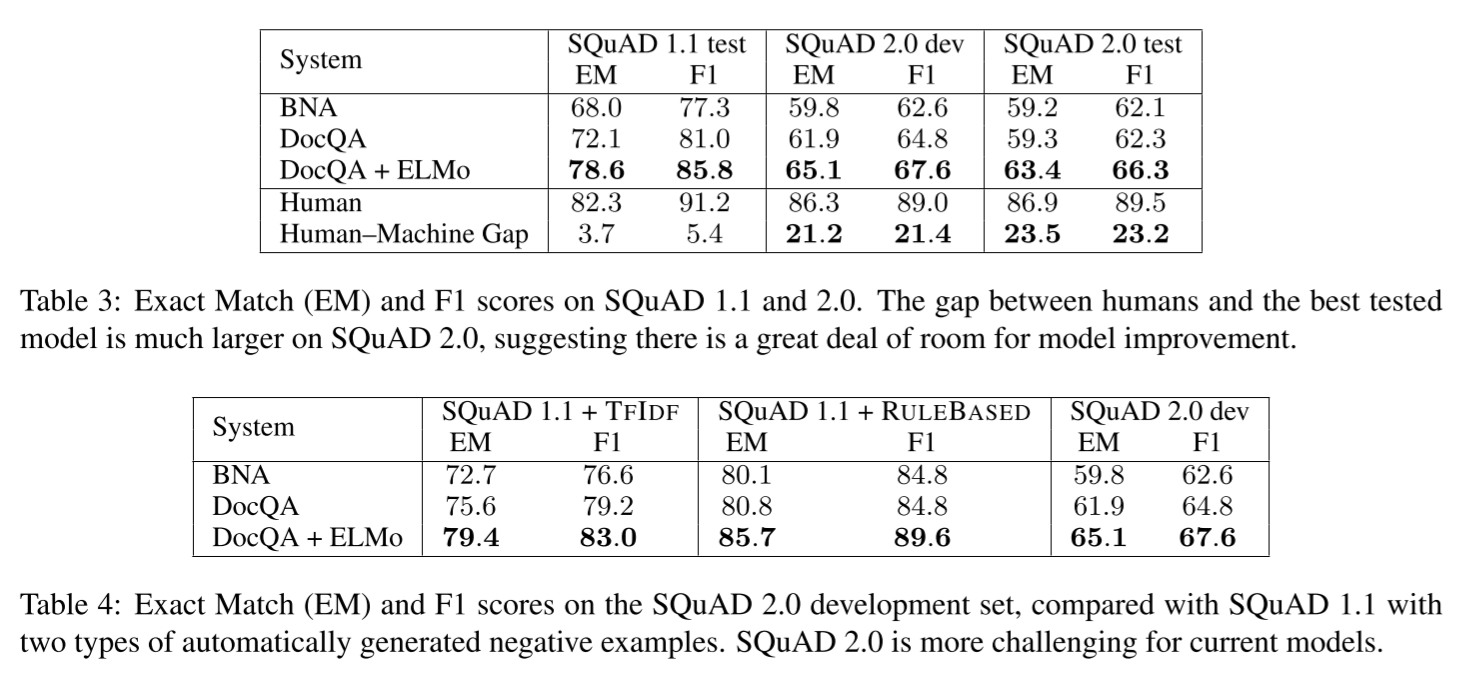
리더보드를 잠식한 BERT
- 이렇게 어려운 task와 데이터셋이 발표되고 몇 달 지나지 않은 2018년 말 현재, SQuAD 리더보드에는 인간 수준에 근접하는 성능을 보이는 모델들이 다수 올라와 있습니다. 그 중 최상위권에서 공통적으로 모이는 모델은 ‘BERT(Bidirectional Encoder Representations from Transformers)’입니다.
- 다음 글에서는 최근 다양한 NLP task에서 SOTA(State of the art) 수준을 기록하고 있는 BERT 모델에 대해 알아봅니다
다음 글 바로가기: SQuAD 2.0과 BERT(2)
-
‘requirements’의 격식있는 표현 ↩
-
‘distant supervision’: 대부분의 기계 학습 기술은 일련의 교육 데이터가 필요합니다. 교육 데이터를 수집하는 전통적인 접근법은 인간이 일련의 문서에 레이블을 붙이는 것입니다. 예를 들어, 결혼 관계의 경우, 인간 주석 작성자는 “빌 클린턴”과 “힐러리 클린턴”이라는 쌍을 긍정적인 훈련 예로 표시할 수 있습니다. 이 접근법은 시간과 돈면에서 비용이 많이 들고, 코퍼스가 크면 알고리즘이 작업 할 수있는 충분한 데이터를 산출하지 못합니다. 그리고 인간이 실수를 저지르기 때문에, 그 결과 나오는 훈련 데이터는 노이즈가 많을 것입니다. 교육 데이터를 생성하는 또 다른 방법은 먼 감독(distant supervision)입니다. 먼 곳에서 우리는 프리베이스 또는 도메인 별 데이터베이스와 같은 이미 존재하는 데이터베이스를 사용하여 추출하려는 관계에 대한 예를 수집합니다. 그런 다음 이 예제를 사용하여 자동으로 교육 데이터를 생성합니다. 예를 들어, 프리베이스는 버락 오바마와 미셸 오바마가 결혼했다는 사실을 담고 있는데, 우리는 이 사실을 받아 들인 다음 결혼 관계에 대한 긍정적인 예와 같은 문장에 나타나는 “Barack Obama”와 “Michelle Obama”의 각 쌍에 레이블을 붙입니다. 이렇게 하면 많은 양의 (그리고 아마도 노이즈가 많은) 교육 데이터를 쉽게 생성할 수 있습니다. 특정 관계에 대한 긍정적인 예를 얻기 위해 먼 감독을 적용하는 것은 쉽지만 부정적인 예를 만드는 것은 과학보다 예술에 더 가깝습니다. 출처 ↩
-
‘negative example’: 공통 관계 추출 응용 프로그램에서 좋은 시스템을 훈련시키기 위해 부정적인 예를 생성해야하는 경우가 많습니다. 부정적인 예가 없으면 시스템은 모든 변수를 긍정으로 분류하는 경향이 있습니다. 그러나 관계 추출의 경우 충분한 골든 스탠다드 negative example(ground truth)를 쉽게 찾을 수 없습니다. 이 경우, 우리는 종종 부정적인 예를 생성하기 위해 distant supervision을 사용해야 합니다. 출처 ↩




댓글남기기