
참고자료
- Visualizing Data using t-SNE
- 원 논문 : Visualizing Data using t-SNE
- 오늘 리뷰할 논문은 Visualizing Data using t-SNE 입니다.
- 고차원 데이터의 시각화에 사용되는 t-Stochastic Neighbor Embedding기법에 대한 설명자료 (Slideshare)
- 손실 압축과 매니폴드 학습
- t-SNE ratsgo’s blog
- Data Visualization and t-SNE
- Analysis of Commute Time Embedding Based on Spectral Graph
- PR-103: Visualizing Data using t-SNE
ABSTRACT
- 데이터 포인트에 2 차원 또는 3 차원 맵을 제공함으로써 고차원 데이터를 시각화하는 “t-SNE”라는 새로운 기술을 제시
- Stochastic Neighbor Embedding (Hinton and Roweis, 2002)의 변형이며, 훨씬 더 나은 시각화를 생산하고 있음
- t-SNE는 여러 가지 규모에서 구조를 나타내는 단일 지도를 만드는 기존 기술보다 낫다
- 특히 여러 관점에서 본 다수 클래스의 개체 이미지와 같이 여러가지이지만 관련성이 낮은 여러 차원의 다양체(Manifold)에 있는 고차원 데이터에 중요
- 매우 큰 데이터 세트의 구조를 시각화하기 위해 t-SNE가 인접 그래프에서 random walks 방법을 사용하여 데이터의 암시적인 구조가 데이터의 하위 집합이 표시되는 방식에 영향을 미치도록 함
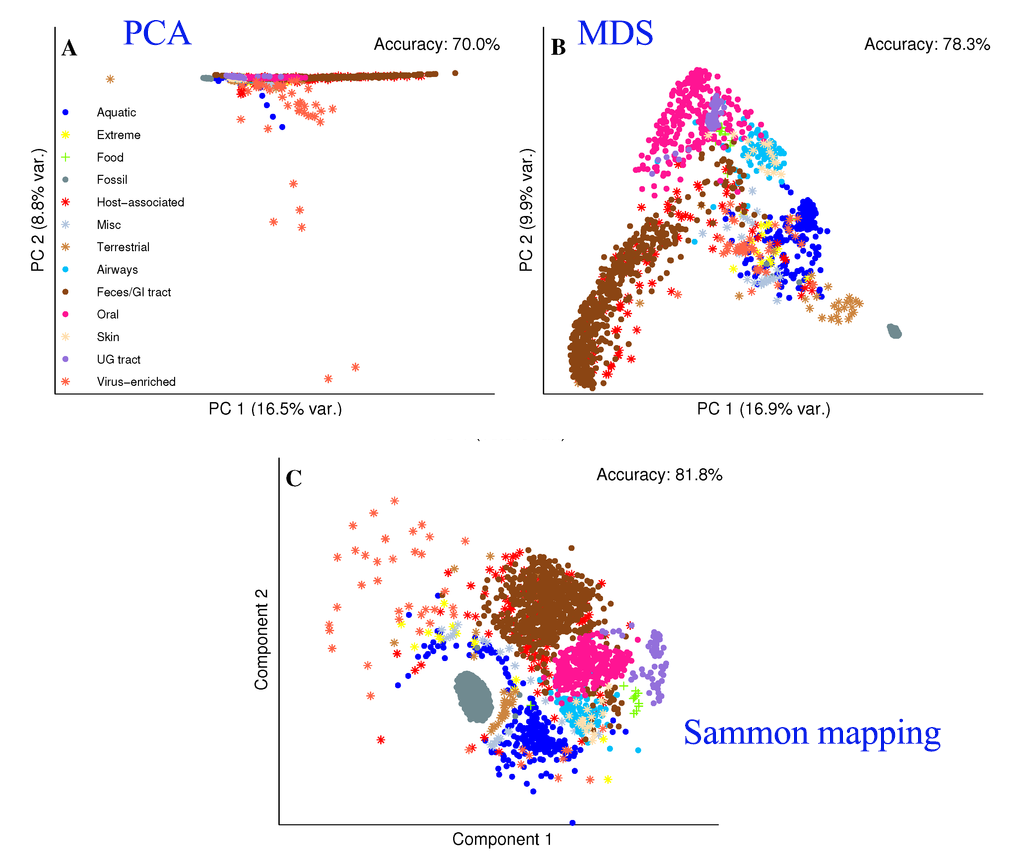
- 다양한 데이터 세트에서 t-SNE의 성능을 보여주고 Sammon Mapping, Isomap 및 Locally Linear Embedding을 비롯한 다양한 비모수 비주얼라이제이션 기법과 비교
- 거의 모든 데이터 세트에 적용 가능, 키워드 : 시각화, 차원 축소, 매니폴드 학습, 임베딩 알고리즘, 다차원 스케일링
1. INTRODUCTION
- 고차원 데이터의 시각화는 많은 다른 영역에서 중요한 문제이며 광범위하게 변화하는 차원의 데이터를 다룸
- 예를 들어, 유방암과 관련이 있는 세포핵은 약 30 개의 변수 (Street et al., 1993)에 의해 기술되는 반면, 이미지를 나타내는데 사용된 픽셀강도 벡터 또는 문서를 표현하는 데 사용되는 단어 카운트 벡터는 일반적으로 수천 개의 차수
- 지난 수십 년 동안 Oliveira와 Levkowitz(2003)가 검토한 많은 고차원 데이터의 시각화를 위한 다양한 기법이 제안되었음
- 중요한 기술은 Chernoff Face (Chernoff, 1973), 픽셀 기반 기법 (Keim, 2000) 및 그래프의 정점으로 데이터의 크기를 나타내는 기술 (Battista 등, 1994)과 같은 그래픽 디스플레이 포함

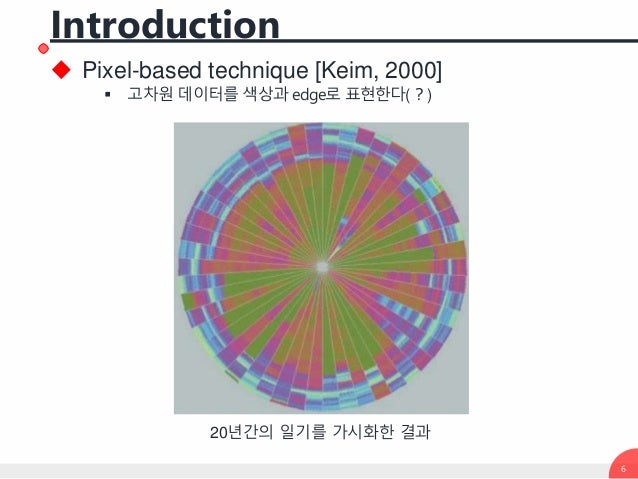
- 기술 대부분은 단순히 두 개 이상의 데이터 차원을 표시하는 도구를 제공하고 데이터의 해석은 사람의 관찰자에게 맡김
- 수 천개의 고차원 데이터 포인트를 포함하고 있는 실제 데이터 세트에 이 기술의 적용 가능성을 심각하게 제한
- 위에서 논의한 시각화 기법과 달리, 차원축소 방법은 고차원 데이터 세트 X = {x1, x2, …, xn}을 2 차원 또는 3 차원 데이터 Y = {y1, y2, …, yn}을 표시 할 수 있음
- 저차원 데이터 표현 Y를 지도로, 개별 데이터 포인트의 저차원 표현 yi를 맵 포인트라고 부름
-
차원 축소의 목표는 저차원 지도에서 가능한 고차원 데이터의 중요한 구조를 최대한 보존하는 것
- 주성분 분석(PCA) 및 다차원 스케일링(MDS)은 서로 다른 데이터 포인트의 저차원 표현으로 멀리 떨어뜨리는 데 초점을 맞춘 선형 기술
- 저차원, 비선형 매니폴드 위에 또는 근처에 있는 고차원 데이터의 경우 매우 비슷한 데이터 포인트의 저차원 표현을 서로 가깝게 유지하는 것이 더 중요함
-
일반적으로 선형 매핑에서는 불가능. 데이터의 지역 구조를 보존하는 것을 목표로 하는 많은 수의 비선형 차원 감소 기술이 제안되었.
- Sammon Mapping (Sammon, 1969)
- Sammon 매핑은 입력 패턴의 구조를 보존하면서 차원을 축소하는 포인트 매핑(point mapping) 기법
- 입력과 출력 패턴들의 거리 차이에 의해 발생된 에러 값이 초기 사용자가 설정한 에러 수렴 값보다 작을 때까지 반복연산 수행
- Sammon 매핑은 매핑되는 공간(2-3차원)의 초기 값을 작은 랜덤 값으로 설정하기 때문에 항상 출력 결과가 다르게 나타나는 특징
- 하지만 입력 패턴들간의 거리 정보가 보존되기 때문에 매핑된 차원에서 유클리디언 거리(Euclidean distance)를 계산하면 패턴들간의 상관관계를 분석할 수 있음
- CCA (Demartines and Herault, 1997)
- 두 변수 집단의 연관성(association)을 각 변수집단에 속한 변수들의 선형결합(linear combination)의 상관계수를 이용하여 설명
- 변수집단의 선형결합(U, V)의 상관 계수를 구하고, 상관계수를 최대화 하게 되는 정준 계수를 찾는 방법 (제2 정준계수는 제1 정준계수와 상관이 없도록 함)
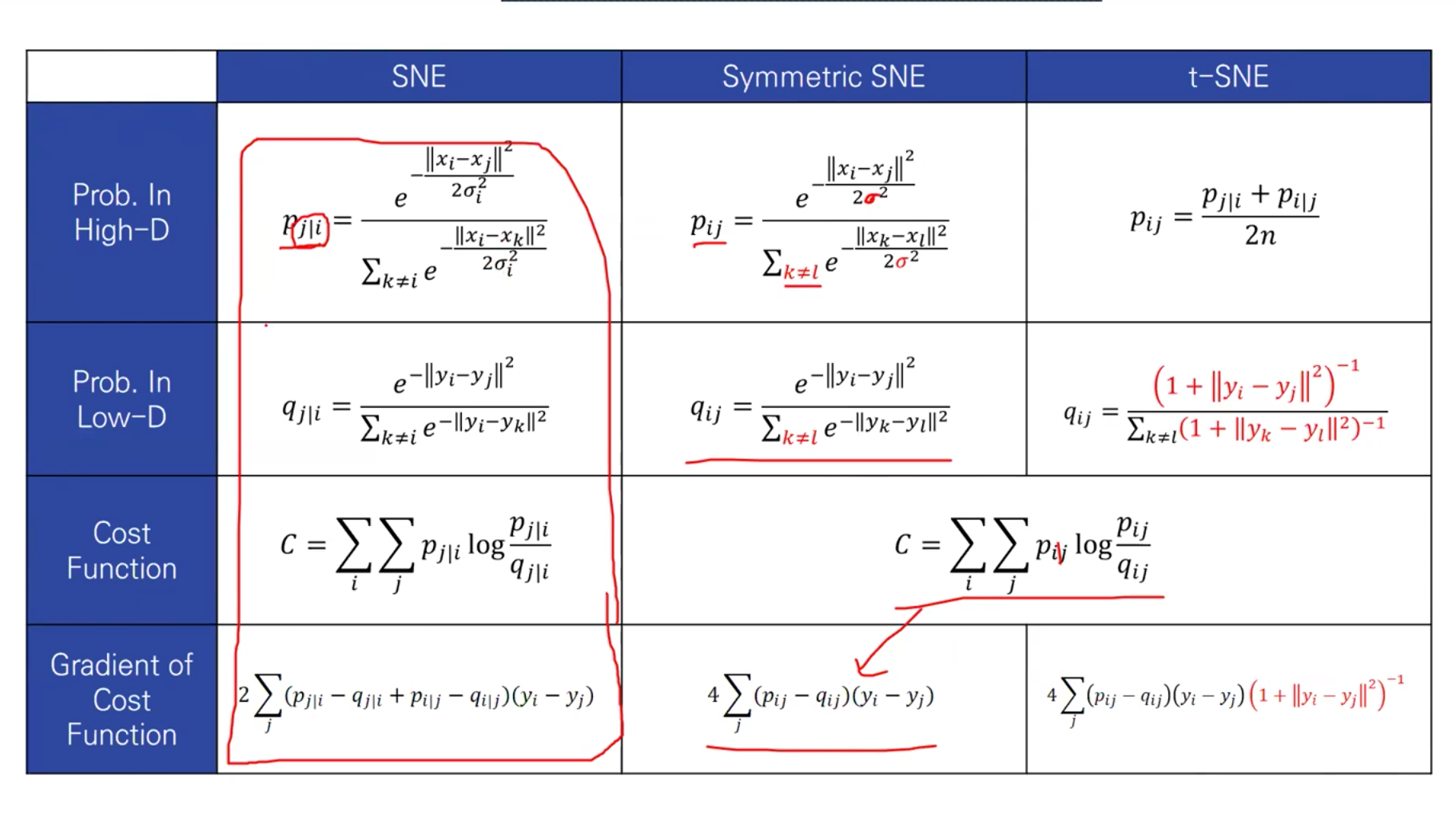
- Stochastic Neighbor Embedding (SNE, Hinton and Roweis , 2002)
- t-SNE의 앞선 방법, 고차원의 원공간에 존재하는 데이터 x의 이웃 간의 거리를 최대한 보존하는 저차원의 y를 학습하는 방법론
- 거리 정보를 확률적으로 나타내어 Kullback-Leibler divergence를 비용 함수로 최소화 하면서 학습 진행
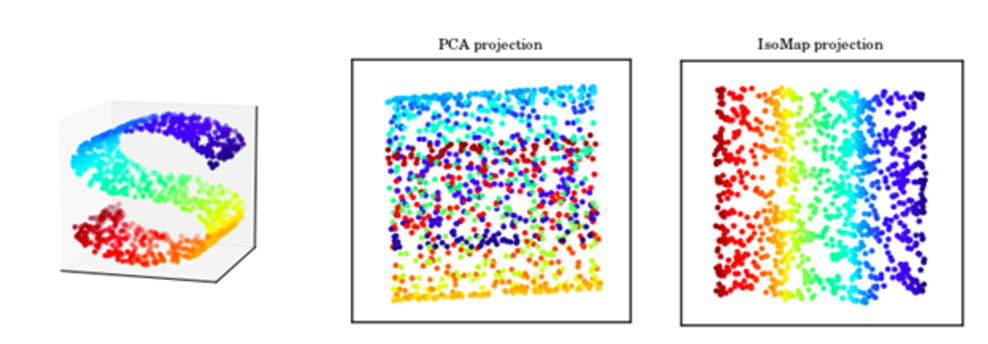
- Isomap (Tenenbaum et al., 2000)
- 고차원 데이터들 사이의 거리가 주어지면, 거리들의 분포를 보전하면서 2,3차원 등의 저차원 공간에 투영시킨 좌표들의 집합을 구하는 방법 중 하나
- 고차원 공간(예를 들어 얼굴)의 각 점을 이웃에 있는 모든 점(매우 닮은 얼굴)에 연결
- 각 점마다 가장 가까이에 있는 점과의 거리, 즉 가장 짧은 거리를 모든 점에 대해 계산하고 최단 거리들을 가장 잘 근사시키는 축소된 좌표축들을 찾음
- Maximum Variance Unfolding (MVU; Weinberger et al., 2004)
- PCA의 비선형 알고리즘, 고차원 입력 벡터와 일부 저차원 유클리드 벡터 공간으로의 매핑
- 입력은 k개의 가장 가까운 입력 벡터 이웃으로 연결되고 그래프는 semidefinite 프로그래밍으로 전개
- semidefinite 프로그래밍은 출력 벡터를 직접 학습하는 대신 가장 가까운 이웃 거리를 유지하면서 인접 그래프에서 연결되지 않은 두 입력 사이의 쌍 거리를 최대화하는 제품 행렬을 찾는 것을 목표로 함
- Locally Linear Embedding (LLE; Roweis and Saul, 2000)
- 모든 공간에서 k개의 이웃을 찾고, 이웃 점들간의 구조의 x와 w(weights)의 선형 결합 Reconstruct
- locality 만을 유지하며 임베딩 공간을 학습하는 것이 목표, 이웃 정보가 잘 보존되어 있다면 글로벌 구조도 잘 보전되었다고 가
- Laplacian Eigenmaps (Belkin and Niyogi, 2002)
- 주어진 데이터를 각 노드로 하는 그래프를 구성하고 각 노드를 유클리드 공간으로 임베딩하는 스펙트럴 그래프 방식을 채택
- 그래프 라플라시안 행렬(노드의 연결점(edge)에 degree를 합한 매트릭스)에서 구한 고유치(eigenvalue)와 고유벡터(eigenvector)를 이용하여 그래프의 구조적인 특성을 분석
- 데이터를 클러스터링하는 기능은 우수하지만 각 점 간의 거리에 대한 정의가 명확하지 않아 임베딩 방식으로는 널리 활용되고 있지 않음
- Sammon Mapping (Sammon, 1969)


- 기술의 강력한 성능에도 불구하고 실제의 고차원 데이터를 시각화하는 데는 종종 성공적이지 못함
- 특히, 대부분의 기술은 단일 맵에서 데이터의 로컬 및 글로벌 구조를 모두 유지하기 어려움
- 고차원 데이터 집합을 쌍으로 된 유사성의 행렬로 변환하는 방법에 대해 설명하고 결과로 나오는 유사성 데이터를 시각화하기 위해 “t-SNE”라는 새로운 기술을 소개
- t-SNE는 고차원 데이터의 많은 국부적인 구조를 매우 잘 포착 할 수 있을 뿐만 아니라 몇 가지 규모의 클러스터 존재와 같은 글로벌 구조를 나타냄
- t-SNE의 성능을 다양한 도메인의 5 개 데이터 세트에 대해 위에서 언급 한 7 가지 차원 축소 기술과 비교하여 설명
- 논문 개요
- 2 절에서는 t-SNE의 기초가 되는 Hinton and Roweis (2002)가 제시한 SNE의 개요를 설명
- 3 장에서 SNE와 두 가지 중요한 차이가 있는 t-SNE를 제시
- 4 장에서 실험 설정과 실험 결과를 설명
- 5 장에서는 10,000 개가 넘는 데이터 포인트를 포함하는 실제 데이터 세트를 시각화하기 위해 t-SNE을 수정하는 방법을 보여줌
- 실험의 결과는 6 장에서 더 자세히 논의됨
- 결론과 향후 연구를 위한 제안은 7 장에서 제시
매니폴드는 고차원 공간에 내재한 저차원 공간,
매니폴드(manifold)란, 두 점 사이의 거리 혹은 유사도가 근거리에서는 유클리디안(Euclidean metric, 직선 거리)을 따르지만 원거리에서는 그렇지 않은 공간을 말합니다.
조그만 유클리디안 공간 조각들(육면체 하나를 근거리에서 정의된 유클리디안 공간이라고 생각하시면 됩니다)이 다닥다닥 붙어 이루어져서
전체적으로 보면 비유클리디안(non-Euclidean)이 되는 공간을 뜻합니다.
2. Stochastic Neighbor Embedding
- Stochastic Neighbor Embedding, SNE은 데이터 점 사이의 고차원의 유클리드 거리를 유사성으로 나타내는 조건부 확률로 변환하는 것으로 시작
- xj의 xi에 대한 유사도를 나타내는 조건부 확률, \( p(j|i) \)는 xi가 xi를 중심으로 하는 가우시안 분포에서 확률 밀도에 비례하여 이웃들을 선택하면 xi는 이웃으로서 xj를 선택할 것
- 조건부 확률 값이 높으면 데이터 포인트가 가깝다
- 조건부 확률 값이 낮으면 데이터 포인트가 멀다
- Stochastic Neighbor Embedding, SNE은 데이터 포인트 간의 고차원 유클리드 거리를 유사성을 나타내는 조건부 확률로 변환함으로써 시작됨
\[p_{j \vert i} = \frac{exp(- \vert x_i - x_j \vert^2 / 2 \sigma_i^2)}{\sum_{k \neq i} exp(- \vert x_i - x_k \vert^2 / 2 \sigma_i^2)}\]
- 인접 데이터 포인트의 경우 \( p(j|i) \)는 상대적으로 높지만, 넓게 분리된 데이터 포인트의 경우 \( p(j|i) \)는 거의 무한 (Gaussian의 분산 값은 σi).
- xi 에 대한 조건부 분포가 조밀한(dense)한 경우에는 sigma 값이 낮을 것이며 sparse한 경우에는 σ값이 높을 것
- pairwise 유사성 모델링에만 관심이 있기 때문에 \( p(i|i) \)의 값을 0으로 설정
- 고차원 데이터 포인트 xi와 xj의 저차원 상대 yi와 yj에 대해 \( q(j|i) \)로 표시하는 비슷한 조건부 확률을 계산할 수 있음
- 조건부 확률 \( q(j|i) \)의 계산에 사용되는 가우시안의 분산 1/√2로 설정
\[q_{j \vert i} = \frac{exp(- \vert y_i - y_j \vert^2)}{\sum_{k \neq i} exp(- \vert y_i - y_k \vert^2)}\]
- 마찬가지로 pairwise 유사성을 모델링하는 것에만 관심이 있으므로 \( q(j|i) = 0 \)으로 설정
- yi와 yj가 고차원 데이터 점 xi와 xj 사이의 유사성을 정확하게 모델링한다면
- 조건부 확률 \( p(j|i) \)와 \( q(j|i) \)는 근사할 것
- SNE는 \( p(j|i) \) 와 \( q(j|i) = 0 \) 사이의 불일치를 최소화하는 저차원 데이터 표현을 찾는 것을 목표로 함
- SNE의 목적은 p와 q의 분포 차이가 최대한 작게끔 하고자 함. 차원 축소가 제대로 잘 이뤄졌다면 고차원 공간에서 이웃으로 뽑힐 확률과 저차원 공간에서 이웃으로 뽑힐 확률이 비슷할 것
- 두 확률분포가 얼마나 비슷한지 측정하는 지표 척도는 Kullback-Leibler divergence
- KL Divergence는 어떤 확률 분포를 다른 확률 분포로 근사할 때 정확히 얼마나 많은 정보(엔트로피)가 손실되는지를 계산할 수 있음
- 두 확률분포가 완전히 다르면 1, 동일하면 0의 값을 갖음, SNE는 아래 비용함수를 최소화하는 방향으로 학습을 진행하게 됨
- SNE는 그라디언트 디센트 (gradient descent) 방법을 사용하여 모든 데이터 포인트에 걸친 Kullback-Leibler divergence의 합을 최소화
- Kullback-Leibler divergence은 대칭적이지 않으므로 저차원 지도의 쌍방향 거리의 여러 유형의 오차는 똑같은 가중치로 적용되지 않음
- 비대칭적인 의미는 a에서 출발했을 때 b가 도착하는 거리와 b에서 출발했을 때 a가 도착하는 거리가 다름
- 광범위하게 분리된 맵 포인트를 사용하여 가까운 데이터 포인트를 나타내는 데에 많은 비용이 듬
- SNE 비용 함수는 맵에서 데이터의 로컬 구조를 유지하는데 초점을 맞춤
- 선택될 나머지 파라미터는 각각의 고차원 데이터 포인트 xi에 집중되는 가우시안의 분산 σi. σi의 단일 값으로 하는 것은 부적절
- 데이터의 밀도가 다양하기 때문에, 밀도가 높은 영역에서 σi의 값이 작으면 일반적으로 드문드문 지역보다 적절
- σi의 임의의 특정 값은 다른 모든 데이터 포인트에 대해 확률분포 Pi를 유도
- 분포는 πi가 증가함에 따라 증가하는 엔트로피를 갖는다. SNE는 σi의 값에 대해 이진 검색을 수행합니다, 사용자가 지정한 고정된 복잡도를 갖는 Pi를 생성
- Perplexity는 다음과 같이 정의된다. 2^엔트로피, H(Pi)는 비트 단위로 측정 된 Pi의 Shannon 엔트로피
- Perplexity가 높을 수록 분산이 높다고 해석 할 수 있음, 확률 값이 커지니깐 주변 데이터들 중 영향력 있는 갯수 (또는 Perplexity로 local과 global 특성을 맞출 수 있음)
- Perplexity가 작으면 local 특성을 주로 따라감 (너무 작으면 노이즈의 영향을 받을 수 있음)
- Perplexity는 2의 H승(p), i번째 점 주변의 가까운 점의 갯수, 일반적으로 5~50 상수로 정하고 모든 점에 대해서 Perplexity가 일정하게 유지되도록 하는 분산 값을 할당 (binary search)
- 최종적으로 구하고자 하는 미지수는 저차원에 임베딩된 좌표값 yi, SNE는 그래디언트 디센트(gradient descent) 방식으로 yi들을 업데이트.
- 처음에 yi를 랜덤으로 초기화 해놓고 위에서 구한 그래디언트의 반대 방향으로 조금씩 yi들을 갱신해 나가는 것

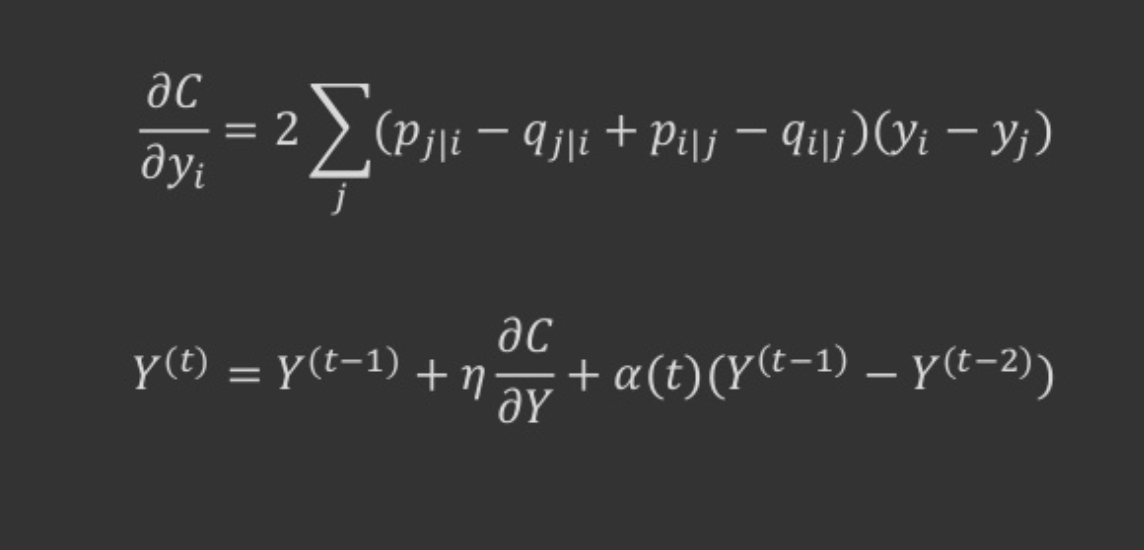
3. t-Distributed Stochastic Neighbor Embedding
- SNE는 합리적인 수준의 시각화를 생성하지만, 최적화 하기 어려운 비용 함수와 “Crowding Problem” 발생
- 문제를 완화하는 것을 목표로 하는 “t-Distributed Stochastic Neighbor Embedding” 또는 “t-SNE”라는 새로운 기술을 제시
- t-SNE에 의해 사용된 비용 함수는 SNE에 의해 사용된 비용 함수와 두 가지 방법이 다름
- 저차원 공간에서 두 점 사이의 유사성을 계산하기 위해 Gaussian보다는 Student-t 분포를 사용
- SNE는 낮은 차원 공간에서 무거운 꼬리 분포를 사용하여 군집 문제와 SNE의 최적화 문제를 완화

3.1 Symmetric SNE
- 앞에서 정의한 거리 함수는 조건부 확률이기 때문에 Symmetric하지 못하므로, 데이터 쌍에 대한 Joint Probability 사용
- Joint Probability, i번째 개체가 주어졌을 때 j번째 개체가 이웃으로 뽑힐 확률 = j번째 개체가 주어졌을 때 i번째 개체가 선택될 확률
- SNE의 대칭 버전의 주된 장점은 더 빠른 형태의 그라디언트입니다.
- 대칭 SNE의 그래디언트는 비대칭 SNE의 그래디언트와 상당히 유사하며 실험에서 대칭 SNE가 비대칭 SNE와 마찬가지로 좋고 경우에 따라 조금 더 나은 맵을 생성하는 것으로 나타났음
- σi는 각 개체마다 데이터 밀도가 달라서 이웃으로 뽑힐 확률이 왜곡되는 현상을 방지하기 위한 값, 반복 실험 결과 p를 계산할 때 쓰는 σi는 고정된 값을 써도 성능에 큰 차이를 보이지 않았다고 하여 σi 계산 생략
- 비대칭 => 대칭 점 간의 유사도를 대칭적으로 만들기 위하여 두 확률 값의 평균으로 두 점간의 유사도를 정의
- 변경된 수식
3.2 The Crowding Problem
- 고차원에서 저차원으로 점을 Projection 하면, 거리가 멀고 가까운 개념이 붕괴되는 경우가 있음
- 예를 들어 3차원에서는 서로 다른 4개의 점이 서로와 같은 거리에 위치하도록 할 수 있는데 2차원에서는 4개의 점이 거리가 달라지게 됨
- 고차원에서 멀리 떨어져 있던 점은 저차원에서 더 멀게, 고차원에서 가까웠던 점은 저차원에서 더 가깝게 만들어줄 인위적인 장치가 필요 (정교하게 바꿈, 가까운 점들끼리 모임)
- “스위스 롤 (Swiss roll)” 데이터 세트와 같은 장난감 예제에 설명되어 있음.

- Low Dimensional Domain에서만 Gaussian 대신에 수정된 형태의 분포를 사용(Student t-Distribution)
- High Dimensional에서는 그대로 가우시안 분포 사용
- 가까운 점의 q값을 실제보다 저평가 => 더 가까워지려고 한다.
- 먼 점의 q 값을 실제보다 고평가 => 굳이 더 가까워지려고 하지 않는다. (더 멀어진다.)
- 이번에는 임베딩 공간에서의 두 점 간의 유사도 \( q(j|i) \) 를 정의
- 두 점 간의 거리(yi-yj)가 작을수록 유사도가 클 수 있도록 임베딩 공간의 거리에 1 을 더한 뒤 역수를 취함. 그리고 모든 점들 간의 합으로 나눠줌으로써 전체의 합이 1 이 되도록 함
- 조건부 확률을 average 해서 사용하게 됨, 모든 데이터의 확률이 1/2n 이상 확보
- Symmetric SNE에서는 Outliers의 경우, distance가 다 커서 확률이 0에 가까워서 학습이 안되었음
3.3 Mismatched Tails can Compensate for Mismatched Dimensionalities
- 멀리 떨어져 있는 점들의 큰 클러스터는 개별 점과 동일한 방식으로 상호 작용하므로 최적화는 가장 미세한 스케일을 제외하고는 동일한 방식으로 작동
- 계산적으로 편리한 속성은 Student t 분포가 Gaussians의 무한한 혼합과 같음에도 불구하고 지수가 포함되지 않기 때문에 Student t 분포 아래의 점의 밀도를 가우시안보다 더 빠르게 평가한다는 것
- 첫째로, t-SNE 그라디언트는 저차원 표현에서 작은 pairwise distance로 모델링 된 다른 datapoints를 강하게 반발
- 둘째, 비록 t-SNE가 작은 pairwise distance에 의해 모델링된 다른 datapoint들 사이에 강력한 반발을 일으키지만, 이러한 반발은 무한대로 가지 않습니다.
- 이 점에서, t-SNE는 UNI-SNE와는 다르다.
- 매우 다른 datapoint 사이의 반발력이 저차원 맵에서 pairwise distance에 비례하기 때문에 서로 다른 datapoint가 각각 너무 멀리 떨어져 움직일 수 있음
- t-SNE는 (1) 큰 pairwise 거리를 사용하여 서로 다른 datapoints를 모델링하고, (2) 작은 pairwise 거리를 사용하여 유사한 datapoints를 모델링하는 데 중점을 둠
- 또한, t-SNE 비용 함수의 최적화는 초기에 분리되는 유사한 점들의 클러스터를 함께 되돌릴 수 있음

- 저차원 데이터 표현에서 점 사이의 쌍방향 거리와 고차원의 두 점 사이의 쌍으로 된 유클리드 거리의 함수로 SNE의 세가지 유형의 기울기
- UNI-SNE는 confusion ratio를 가진 uniform background distribution model의 도입, SNE보다 뛰어난 성능을 보여 주지만, 최적화가 어려운 모델
3.4 Optimization Methods for t-SNE
- t-SNE 비용 함수를 최적화 하기 위한 상대적으로 단순한 그래디언트 디센트를 제시.

- gradient decent를 진행하면 불안정하기 때문에 momentum 으로 paraemter를 업데이트
- 반복 횟수를 줄이기 위해 momentum 항을 사용하며, 모멘텀 항이 작으면 맵 포인트가 적절하게 잘 정리 될 때까지 학습
- 학습은 Jacobs(1988)에 의해 설명된 adaptive learning rate를 사용하여 가속화 할 수 있는데,
- 그라디언트가 안정한 방향으로 점진적으로 학습 속도를 증가시킴
-
알고리즘이 다른 비모수 차원의 축소 기술로 생성된 것보다 훨씬 나은 시각화를 생성하지만, 아래의 2가지 효과적인 방법으로 최적화함 (2가지 중 어떤 걸 써도 됨
- “early compression” 트릭
- 최적화가 시작될 때 맵 포인트 가까이에 두도록 강제하는 것
- 맵 포인트 사이의 거리가 작으면 클러스터가 서로 이동하기 쉽기 때문에 가능한 글로벌 하게 데이터의 공간을 탐색하는 것이 훨씬 쉬움
- 원점으로부터의 맵 포인트의 제곱 거리의 합에 비례하는 비용 함수에 L2 페널티를 추가함으로써. 페널티 기간의 크기와 반복은 수동으로 설정
- 맵상의 점을 밀집하도록 하게 하여, 클러스터가 예쁘게 분리될 수 있도록 함
- “early exaggeration” 트릭
- 클러스터가 global한 구조를 쉽게 찾을 수 있도록 사용하는 트릭
- pij를 4로 곱하여, qij가 상대적으로 작기 때문에 pij에 대응하기 위하여 크게 움직이고 맵 포인트가 넓게 움직이도록 함
- 클러스터가 맵 포인트에서 단단하고 서로 간의 넓게 분리된 클러스터를 형성하는 경향으로 빈 공간이 많이 생길 수 있도록 조정
4. Experiments
- t-SNE를 평가하기 위해, 차원 축소를 위한 7가지 다른 비모수 기술과 비교되는 실험을 제시
- 페이퍼 공간의 제한으로 인해 본 논문에서는 (1) Sammon 매핑, (2) Isomap, (3) LLE 만 t-SNE와 비교,
- 보충 자료에서 t-SNE와 CCA, (5) SNE, (6) MVU 및 (7) Laplacian 고유 맵을 비교합니다.
- 다양한 응용 분야를 대표하는 다섯 가지 데이터 세트에 대한 실험을 수행했
- 페이퍼 공간의 제한으로 인해 본 논문에서 3 가지 데이터 세트로 제한.
- 나머지 두 데이터 세트에 대한 실험 결과는 보충 자료에 제시되어 있습니다.
- 4.1 절에서 실험에 사용 된 데이터 세트가 소개됩니다. 실험 설정은 4.2 절에 제시되어 있음. 4.3 절에서 실험 결과를 제시
4.1 Data Sets
- 실험에 사용 된 5 개의 데이터 세트는 다음과 같음
- MNIST 데이터 세트
- Olivettifaces 데이터 세트
- COIL-20 데이터 세트
- the word-features 데이터 세트
- Netflix 데이터 세트
- 해당 섹션에서는 처음 세 개의 데이터 세트에 대해서만 결과를 제시. 나머지 두 데이터 세트의 결과는 보충 자료에 표시
- MNIST : 60,000 grayscale images of handwritten digits
- 실험을 위해 계산 상의 이유로 6,000 개의 이미지를 임의로 선택
- 이미지는 28 × 28 = 784 픽셀 (즉, 치수)을 갖습니다.
- Olivetti는 : 40명의 개인으로 구성된 얼굴 이미지 (서로 다른 조명조건과 얼굴 표현으로 찍혀있는)
- 데이터 세트는 크기 92 × 112 = 10,304 픽셀의 400 개 이미지 (개인당 10 개)로 구성되며 ID에 따라 라벨이 지정됩니다.
- The Database of Faces at a glance
- COIL-20 데이터 세트는 72 개의 방향(동일한 간격)에서 본 20 개의 서로 다른 물체의 이미지
- 총 1,440 개의 이미지, 32 × 32 = 1,024 픽셀
- Columbia University Image Library
4.2 Experimental Setup
- 모든 실험에서 데이터의 차원을 30으로 줄이기 위해 PCA를 사용
- 데이터 포인트 간의 쌍 거리 계산 속도가 빨라지고 interpoint 거리가 심각하게 왜곡되지 않고 일부 노이즈가 억제
- 차원축소 기술을 사용하여 30 차원 표현을 2 차원 지도로 변환
- 결과 맵을 산점도로 표시
- 모든 데이터 세트에 대해 각 데이터 포인트의 클래스에 대한 정보가 있지만 클래스 정보는 맵 포인트의 색상 및 / 또는 심볼을 선택하는 데만 사용됨
- 클래스 정보는 맵 포인트의 공간 좌표를 결정하는 데 사용되지 않음
- 따라서 채색은 지도가 유사성을 얼마나 잘 유지하는지 평가하는 방법을 제공함
- 표 1에서 Perp는 가우시안 커널에 의해 유도된 조건부 확률 분포의 복잡도를 나타내고 k는 인접 그래프에 사용된 가장 가까운 이웃의 수를 나타냄.
- Isomap과 LLE을 사용한 실험에서, 오직 대응하는 데이터 포인트만 시각화함.
- we only visualize datapoints that correspond to vertices in the largest connected component of the neighborhood graph
- Sammon 매핑 최적화의 경우, 우리는 500 번의 반복에 대해 Newton의 방법을 수행

4.3 Results
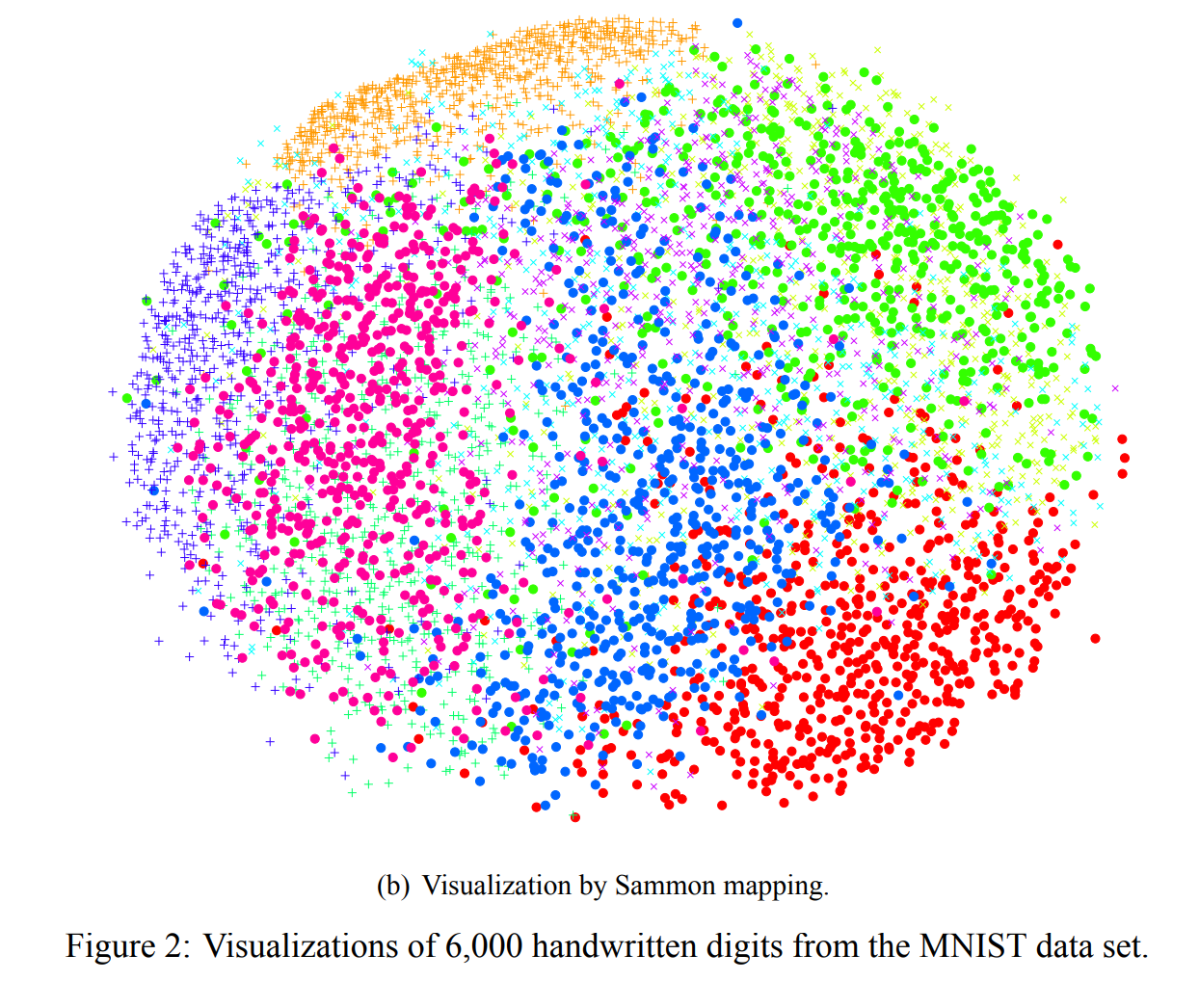
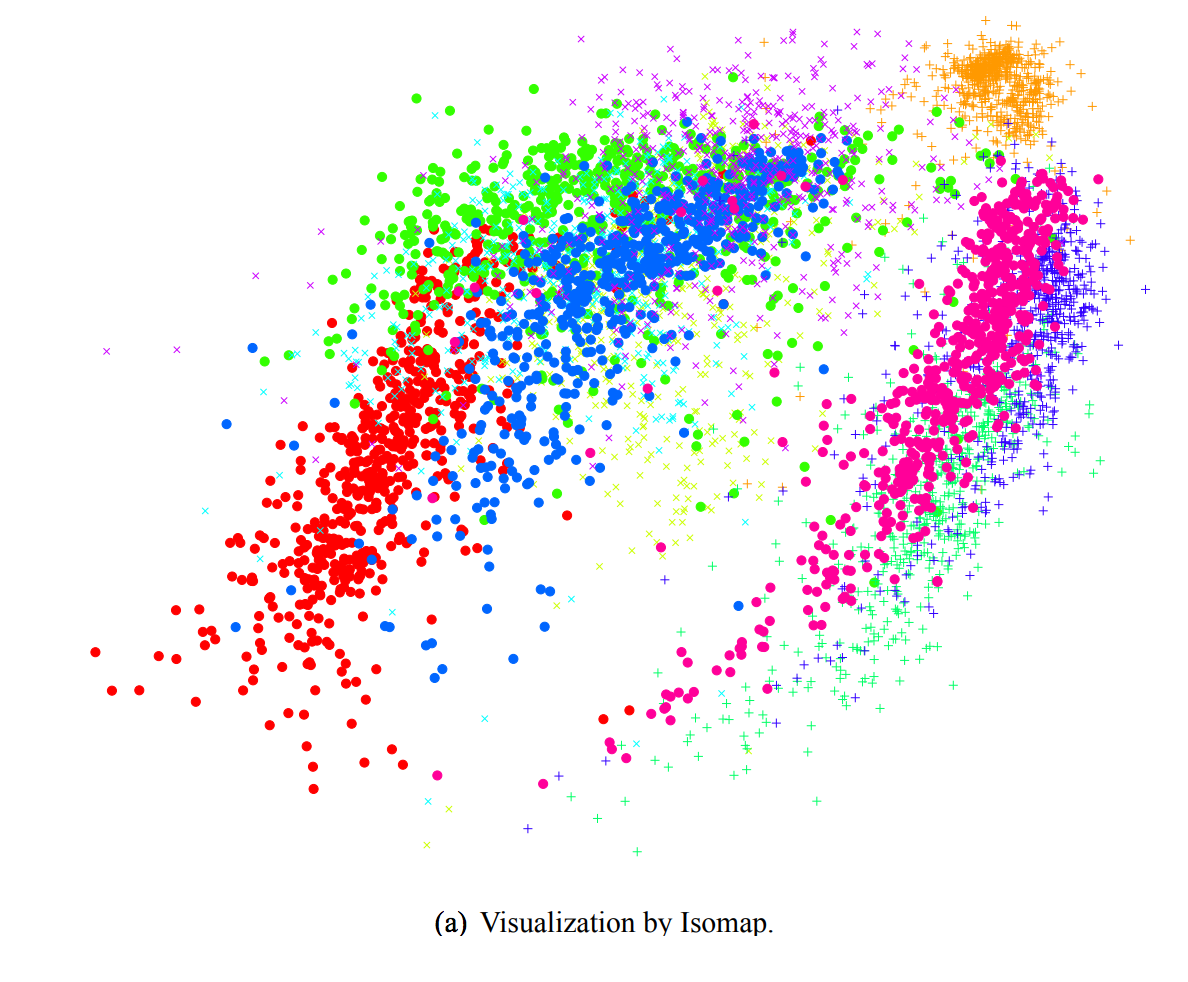
- 그림 2와 3에서 MNIST 데이터 세트에서 t-SNE, Sammon 매핑, Isomap 및 LLE을 사용한 실험 결과를 보여줌.
- 결과는 다른 기술에 비해 t-SNE의 강력한 성능을 보여줍니다. 특히, Sammon 매핑은 3 개의 클래스 (숫자 0, 1 및 7을 나타내는)만 다른 클래스와 약간 분리 된 “ball”을 만듭니다.
- Isomap과 LLE는 숫자 클래스 사이에 큰 중복이 있는 솔루션을 생성
- 대조적으로, tSNE는 숫자 클래스들 사이의 분리가 거의 완벽한 맵을 구성
- t-SNE 맵의 상세한 검사는 데이터의 국부적인 구조 (예를 들어, 방향)가 캡쳐됨
- t-SNE에 의해 생성된 맵에는 잘못된 클래스로 클러스터 된 일부 점이 포함되어 있지만 대부분의 점은 구별하기 어려운 많은 왜곡된 숫자에 해당함


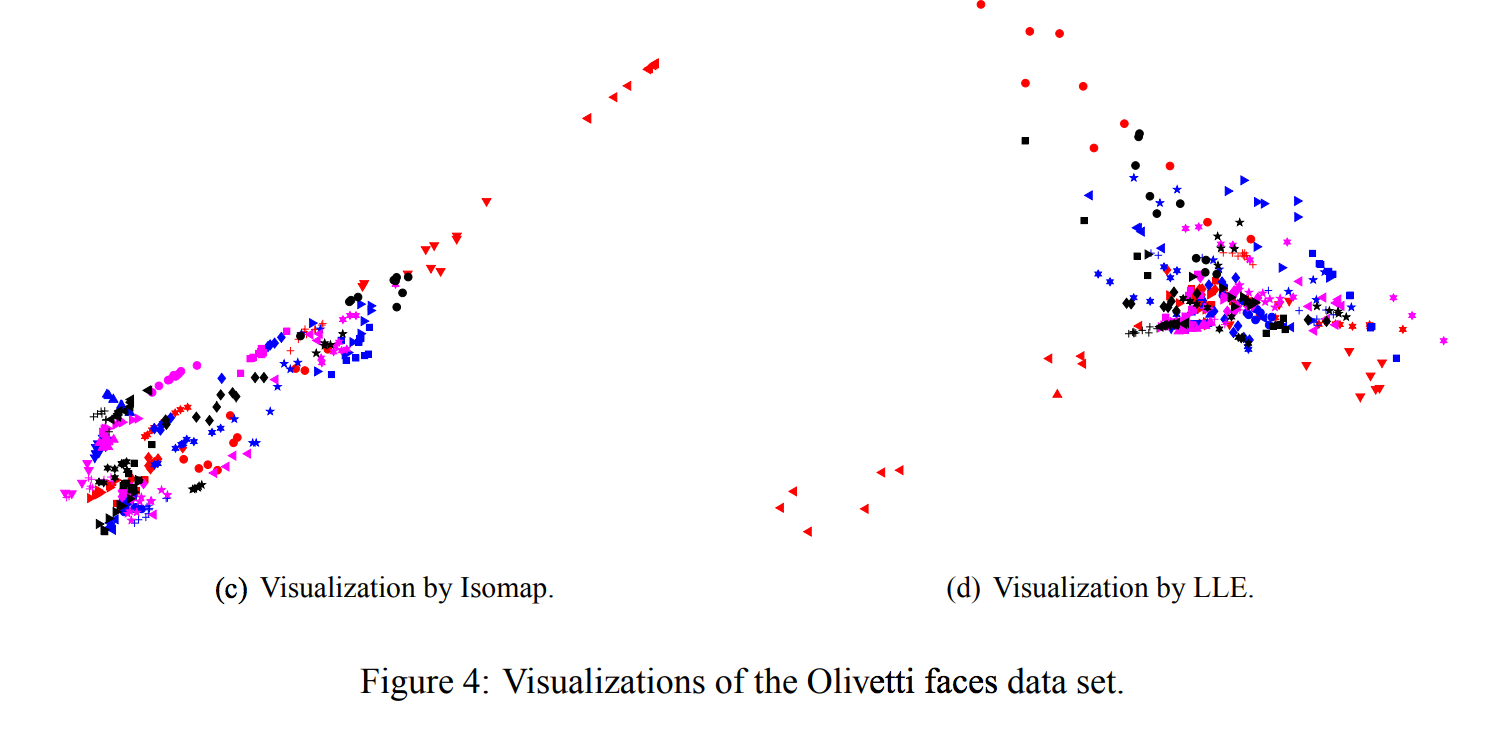
- 그림 4는 t-SNE, Sammon 매핑, Isomap 및 LLE를 Olivetti 얼굴 데이터 세트에 적용한 결과
- Isomap과 LLE는 데이터의 클래스 구조에 대해 거의 통찰력을 제공하지 못하는 솔루션을 생성
- Sammon 맵핑에 의해 생성된 맵은 각 클래스의 멤버 중 상당수를 서로 가깝게 모델링했기 때문에 훨씬 좋았지만, 어떤 클래스도 Sammon 맵에서 명확히 분리되어 있지 않음
- 대조적으로, t-SNE는 데이터의 자연스러운 클래스를 드러내는 훨씬 더 나은 작업을 함
- 어떤 사람들은 10 개의 이미지가 두 개의 클러스터로 나뉨
- 보통 이미지의 하위 집합이 머리가 크게 다른 방향을 향하고 있기 때문에, 또는 매우 다른 표현이나 안경을 가지고 있기 때문
- Olivetti 얼굴 이미지에서 픽셀 공간에서 유클리드 거리를 사용할 때 10 개의 이미지(1명 당)가 자연스러운 클래스를 형성한다는 것이 명확하지 않음

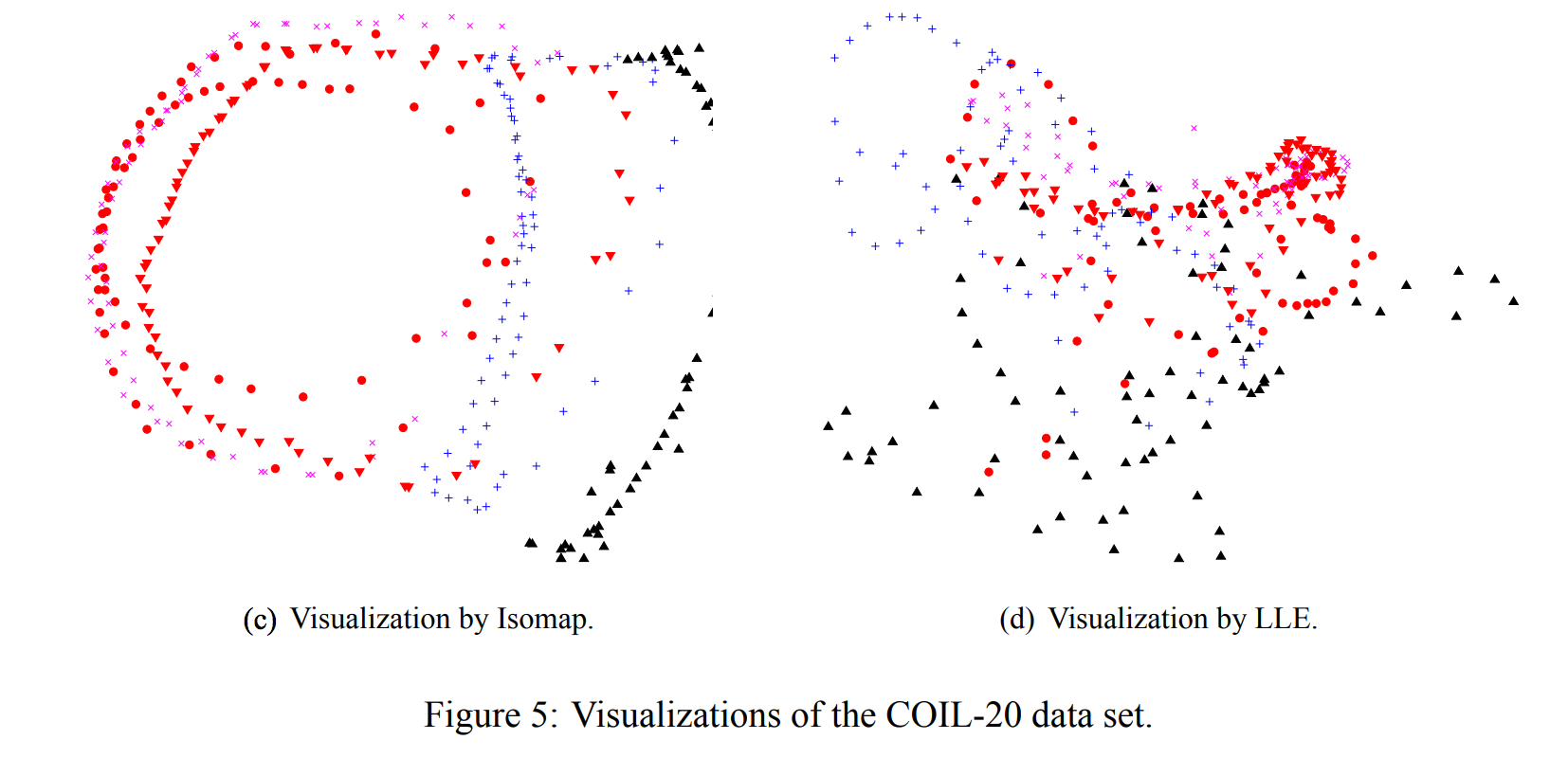
- 그림 5는 t-SNE, Sammon 매핑, Isomap 및 LLE을 COIL20 데이터 세트에 적용한 결과
- 20 개의 객체 중 많은 부분에서 t-SNE은 닫힌 루프와 같이 1 차원 관점의 다양성을 정확하게 나타냄
- 앞면과 뒷면에서 비슷하게 보이는 물체의 경우, t-SNE가 루프를 왜곡하여 앞면과 뒷면의 이미지가 가까운 지점에 매핑됨
- COIL-20 데이터 세트에 있는 4 가지 유형 - 장난감 자동차의 경우 4 개의 회전 매니 폴드가 차의 방향에 따라 정렬되어 높은 유사성을 포착
- 동일한 방향으로 다른 자동차. 이렇게 하면 t-SNE가 네 가지 매니 폴드를 명확하게 분리하지 못하게 함
- 그림 5는 또한 다른 세 가지 기술이 매우 다른 대상에 해당하는 매니 폴드를 깨끗하게 분리하는 것과 거의 비슷하지 않음을 보여줌
- 또한 Isomap과 LLE는 COIL-20 데이터 세트에서 소수의 클래스만 시각화함
- 데이터 세트는 인접 그래프에서 작은 연결 구성 요소를 발생시키는 광범위하게 분리 된 하위 매니폴드를 많이 포함하기 때문

5. Applying t-SNE to Large Data Sets
- 다른 많은 시각화 기술과 마찬가지로 t-SNE는 quadratic in the number of datapoints를 계산하는데는 메모리 복잡성이 있음
- t-SNE의 표준 버전을 10,000 포인트 이상을 포함하는 데이터 세트에 적용하는 것은 실행 불가능함
- 분명히 데이터 포인트의 무작위 부분 집합을 선택하여 t-SNE를 사용하여 표시 할 수는 있지만 접근 방법은 실패
- 표시되지 않은 데이터 포인트가 기본 매니폴드에 대해 제공하는 정보를 사용
- 예를 들어, A, B, C가 모두 고차원 공간에서 등거리에 있다고 가정합니다.
- A와 B 사이에 많은 표시되지 않은 데이터 포인트가 있고 A와 C 사이에 없는 데이터 포인트가 많으면
- A와 B가 A와 C와 동일한 클러스터의 일부가 될 확률이 더 높습니다.
- 매우 큰 데이터 세트의 정보를 사용하는 방식으로 데이터 포인트의 랜덤 서브 세트를 표시하도록 t-SNE를 수정하는 방법
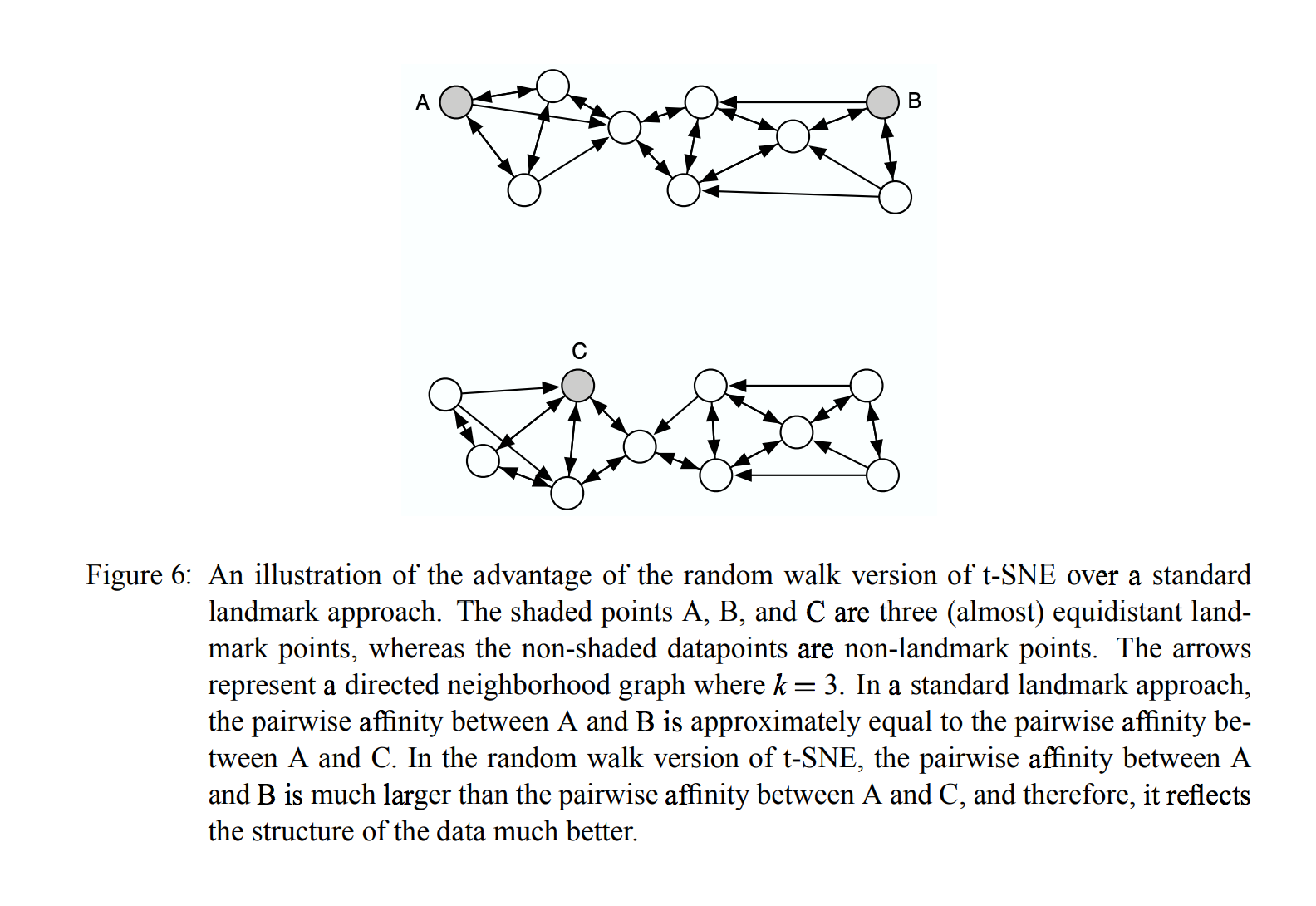
- 원하는 이웃 수를 선택하고 모든 데이터 포인트에 대해 인접 그래프를 만드는 것으로 시작합니다, 계산 집약적이지만 한 번만 수행
- 각 랜드마크 포인트에 대해, 랜드마크 포인트에서 시작하여 다른 랜드마크 포인트에 도착하자마자 랜덤 워크 정의
- 무작위 걸음 (random walk) 동안, 노드 xi에서 노드 xj로 발산하는 에지를 선택할 확률은 e(x1-xj)에 비례
- \( p(j|i) \)를 랜드마크 포인트 xi에서 시작하여 랜드마크 포인트 xj에서 끝나는 무작위 도보의 비율로 정의
- Isomap이 점 사이의 쌍 방향 거리를 측정하는 방식과 닮았음
- 그러나, diffusion map (Lafon and Lee, 2006; Nadler et al., 2006)에서와 같이 가장 짧은 인접 그래프를 통해 무작위 워크 기반의 측정치가 인접 그래프를 통해 모든 경로에 통합
- 결과적으로 무작위 워크 기반 측정은 short-circuit (Lee and Verleysen, 2005)에 훨씬 덜 민감
- 단 하나의 잡음이 많은 데이터 포인트는 두 개의 데이터 공간 영역을 멀리 떨어져 있어야 함
- 랜덤 워크 (random walk)를 사용하는 유사한 접근법은 예를 들어 준감독 학습 (Szummer and Jaakkola, 2001; Zhu et al., 2003)과 이미지 분할 (Grady, 2006)에도 성공적으로 적용됨
- 랜덤 워크 기반 유사도 \( p(j|i) \)를 계산하는 가장 확실한 방법은
- 인접 그래프에서 무작위 걸음을 명시적으로 수행하는 것
- 또는 Grady (2006)는 스파스 선형 시스템을 해결하는 쌍 방향 유사도 \( p(ji) \)를 계산하는 분석 솔루션을 제시 (부록 참고)
- 예비 실험에서 무작위 걸음 걸이를 명시적으로 수행하는 것과 분석적 솔루션 사이에 큰 차이점을 발견하지 못했음
- 아래에 제시된 실험에서 우리는 계산적으로 덜 비싸기 때문에 랜덤워크를 명시적으로 수행했음
- 그러나 랜드 마크 포인트가 매우 드문 매우 큰 데이터 세트의 경우 분석 솔루션이 더 적합 할 수 있음
- 그림 7은 랜덤 워크 버전을 적용한 실험 결과
- t-SNE를 MNIST 데이터 세트로부터 무작위로 선택된 6,000 자릿수로,
- 모든 60,000 숫자를 사용하여 쌍의 유사성 \( p(j|i) \) 실험에서 k = 20 가까운 이웃들의 값을 사용하여 구성된 이웃 그래프를 사용했음
- 삽입 그림은 색상이 자릿수의 레이블을 나타내는 산점도와 동일한 시각화를 나타냄
- t-SNE 맵에서는 모든 클래스가 명확하게 구분됨. 또한, t-SNE는 1, 4, 7, 9의 방향이나 2의 “고리 모양”과 같은 각 클래스 내의 변형의 주 크기를 나타냄
- t-SNE의 강한 성능은 또한 저차원 표현에 대해 훈련된 가장 가까운 이웃 분류 자의 일반화 오차에 반영
- 원래의 784 차원 데이터 점에 대해 훈련된 최근접 이웃 분류기의 일반화 오차 (10 배 교차 검증을 사용하여 측정)가 5.75 % 인 반면에,
- 2 차원에 훈련 된 최근접 이웃 분류기의 일반화 오차 t-SNE에 의해 생성된 데이터 표현은 단지 5.13 %
- 무작위 걸음 t-SNE의 계산 요구 사항은 합리적. 그림 7에서 지도를 작성하는 데 1 시간의 CPU 시간 소요

6. Discussion
- 앞의 두 섹션 (및 보충 자료의 결과)은 다양한 데이터 세트에서 t-SNE의 성능을 보여줌
- 이 섹션에서는 t-SNE와 다른 비모수 기법 (6.1 절)의 차이점에 대해 논의하고, 약점 및 가능한 개선점을 논의
6.1 Comparison with Related Techniques
- PCA 와 밀접한 관계가 있는 고전적 스케일링 (Torgerson, 1952)은 고차원적 쌍 거리와 그것들 사이의 제곱 오차의 합을 최소화하는 데이터의 선형 변환을 발견
- 전통적인 스케일링과 같은 선형 방법은 곡선 매니 폴드를 모델링하는데 좋지 않으며 근처의 데이터 점 사이의 거리를 유지하는 것이 아니라 널리 분리 된 데이터 점 사이의 거리를 유지하는 데 초점을 맞춤
- 고전적 스케일링의 문제를 해결하기위한 중요한 접근 방법은 Sammon 매핑 (Sammon, 1969)
- 이 방법은 각의 페어와 유클리드 거리의 표현에서 제곱 오류를 높은 유클리드 거리로 나누어 고전적인 스케일링의 비용 함수를 변경
- 차원 공간. 결과 비용 함수는 그레디언트의 유도를 단순화하기 위해 합계 외부의 상수가 추가되는 위치에 의해 제공
- Sammon 비용 함수의 가장 큰 약점은 지도에서 쌍거리를 유지하는 중요성이 쌍거리의 작은 차이에 크게 의존한다는 것
- 특히, 매우 근접한 2 개의 고차원 점 모델의 작은 오차는 비용 함수에 큰 기여를 함
- 작은 pairwise 거리가 데이터의 로컬 구조를 고려할 때 작은 쌍 거리에 거의 동일한 중요성을 부여하는 것이 더 적합
- Sammon 매핑과는 달리, t-SNE에 의한 고차원 공간에서 사용된 가우시안 커널은
- 데이터의 로컬 및 글로벌 구조와 가우스의 표준 편차에 비례하여 서로 가까운 데이터 점 쌍에 대한 소프트 경계를 정의
- 분리를 모델링하는 것의 중요성은 분리의 크기와 거의 무관
- t-SNE는 데이터의 로컬 밀도에 기초하여 각 데이터 포인트에 대한 로컬 인접 크기를 개별적으로 결정
- Isomap에 비해 t-SNE의 강력한 성능은 Isomap의 “short-circuiting”에 대한 취약성에 의해 부분적으로 설명
- 또한 Isomap은 주로 작은 측지 거리보다는 큰 측지선 거리를 모델링하는 데 중점을 둠
- LLE에 비해 t-SNE의 강력한 성능은 LLE의 기본적인 약점 때문입니다.
- 모든 데이터 포인트가 단일 지점으로 접히는 것을 방지하는 유일한 방법은 저 차원 표현의 공분산에 대한 제약 사항
- 실제로 이 제약 조건은 대다수의 맵 포인트를 맵의 중앙에 배치하고 몇 개의 널리 분산 된 포인트를 사용하여 큰 공분산을 만듦
- 또한 Isomap 및 LLE와 같은 인접 그래프 기반 기술은 두 개 이상의 널리 분리 된 하위 매니 폴드로 구성된 데이터를 시각화 할 수 없음
- 이러한 데이터는 연결된 인접 그래프를 발생시키지 않기 때문. 연결된 각 구성 요소에 대해 별도의 지도를 생성 할 수도 있지만 이 방법은 분 된 지도의 상대적 유사성에 대한 정보를 잃어버림
- 구성 요소. Isomap과 LLE와 마찬가지로, t-SNE의 무작위 걸음 버전은 인접 그래프를 사용하지만,
- 고차원 데이터 포인트 간의 쌍 방향 유사성은 인접 그래프를 통한 모든 경로에 대한 통합으로 계산되므로 단락 문제가 발생하지 않음
- t-SNE의 무작위 걸음 버전의 기본 조건부 확률에 대한 확산 기반 해석 때문에 t-SNE를 확산 맵과 비교하는 것이 유용
- 확산 맵은 고차원 데이터 포인트에서 “확산 거리”를 정의. 여기서 p (t) i j는 가우스 방출 확률이있는 데이터의 그래프를 통해 타임 스텝에서 xi에서 xj까지 이동하는 확률을 나타냄
- 용어 ψ (xk) (0)은 점들의 국소 밀도에 대한 척도이고, SNE에서 사용되는 고정 된 Perplexity Gaussian 커널과 유사한 목적을 수행
- 확산 맵은 길이 t의 랜덤 보행의 마르코프 행렬의 중요하지 않은 고유 벡터에 의해 형성
- 모든 (n-1) 개의 중요하지 않은 고유 벡터가 사용될 때,
- 확산 맵의 유 클리 디안 거리는 고차원 데이터 표현의 확산 거리와 동일하다는 것을 알 수 있음 (Lafon and Lee, 2006)
- 최소화. 결과적으로 확산 맵은 고전적인 스케일링과 동일한 문제에 취약함. 작은 쌍의 확산 거리보다 큰 쌍의 확산 거리를 모델링하는 데 훨씬 더 중요성을 부여
- 결과적으로 데이터의 로컬 구조를 유지하는 것이 바람직하지 않음
- 또한, t-SNE의 무작위 걸음 버전과는 달리, 확산 맵은 랜덤 워크의 길이 t를 자연스럽게 선택하는 방법 밖에 없음
6.2 Weaknesses
- tSNE는 데이터 시각화를 위한 다른 기술과 비교하여 유리하지만, tSNE는 세 가지 잠재적인 약점
- t-SNE이 일반적인 차원 축소 작업에서 분명하지 않음
- t-SNE는 상대적으로 지역적인 성질으로 차원의 저주에 민감
- t-SNE의 비용 함수가 전역 최적값으로 수렴된다는 보장이 없음
- 1번 약점 : 다른 목적을 위한 차원 축소에는 tSNE가 적합하지 않음
- 즉, 데이터의 차원이 3 차원 초과로 축소되는 경우에서 t-SNE이 어떻게 수행되는지는 분명하지 않음
- 평가 문제를 단순화하기 위해 데이터 시각화를 위해 t-SNE의 사용을 고려
- 데이터를 2 차원 또는 3 차원으로 축소 할 때 t-SNE의 알고리즘은 두꺼운 꼬리 때문에 d > 3 차원으로 쉽게 Projection 시키는 건 좋지 않음
- Student-t 분포의 고차원 공간에서 무거운 꼬리는 확률 질량의 상대적으로 큰 부분을 차지
- 데이터의 차원이 3보다 큰 차원으로 축소되어야 하는 작업의 경우, 1 이상의 자유도를 갖는 Student-t 분포가 더 적합 할 수 있음
- 2번 약점 : 차원의 저주
- t-SNE는 데이터의 로컬 속성을 기반으로 데이터의 차원을 줄여주므로 t-SNE는 데이터의 고유한 차원의 저주에 민감
- 높은 고유 차원과 다양성을 갖는 기본 매니폴드가 있는 데이터 세트에서 t-SNE이 암시적으로 (가까운 이웃 사이의 유클리드 거리를 사용하여) 만드는 매니폴드의 로컬 선형성 가정이 위반 될 수 있음
- t-SNE가 매우 높은 고유 차원 (intrinsic dimensionality)을 갖는 데이터 세트에 적용되면 성공하지 못할 수도 있음
- 예를 들어 Meytlis and Sirovich (2007)의 최근 연구에 따르면 얼굴의 이미지 공간은 대략 100 차원
- Isomap 및 LLE와 같은 매니 폴드 학습자는 똑같은 문제를 겪고있음
- 차원의 저주 문제를 (부분적으로) 해결할 수있는 방법은…
- autoencoder과 같이 다양한 비선형 레이어에서 다양한 데이터의 매니폴드를 효율적으로 표현하는 모델에서 얻은 데이터 표현에 대해 t-SNE를 수행하는 것
- 딥레이어 아키텍처는 복잡한 비선형 함수를 훨씬 단순한 방식으로 나타낼 수 있음
- autoencoder가 t-SNE와 같은 로컬 메소드보다 더 잘 변화하는 매니 폴드를 더 잘 식별 할 수 있기 때문
- 예를 들어 autoencoder에 의해 생성 된 데이터 표현에서 t-SNE를 수행하면 시각화의 품질을 향상시킬 수 있습니다.
- 그러나 본질적으로 고차원적인 구조를 완전히 표현하는 것은 정의상 불가능하다는 것을 알아야 함
- 3번 약점 : t-SNE 비용 함수의 비 convexity
- 대부분의 최첨단 차원 축소 기술 (예 : 클래식 스케일링, Isomap, LLE 및 확산 맵)의 좋은 특성은 비용 함수의 볼록성의 특징이 있음
- t-SNE의 주요 단점은 비용 함수가 볼록하지 않다는 것, 결과 여러 최적화 매개 변수를 선택해야 함
- 구성된 솔루션은 최적화 매개 변수의 선택에 따라 달라짐
- t-SNE가 맵 포인트의 초기 무작위 구성에서 실행될 때마다 다를 수 있음
- 다양한 최적화 매개 변수가 다양한 시각화 작업에 사용될 수 있음을 입증했으며 최적의 품질은 실행마다 크게 다르지 않음을 확인했음
- 볼록 최적화 문제를 일으키지만 시각화 측면에서는 우수하기 때문에 t-SNE를 사용 거부하는 데에는 충분하지 않는 이유라고 생각
7. Conclusions
- 해당 논문은 데이터의 로컬 구조를 유지하면서 중요한 글로벌 구조 (클러스터)를 드러 낼 수 있는 유사성 데이터의 시각화를 위한 새로운 기술 제시
- t-SNE의 계산량과 메모리 복잡도는 모두 n2이지만 제한된 계산 요구로 큰 실제 데이터 세트를 성공적으로 시각화 할 수 있는 획기적인 방법 제시
- 다양한 데이터 세트에 대한 우리의 실험은 t-SNE가 성능이 뛰어나다는 것을 보여줌
- 다양한 실제 데이터 세트를 시각화하기위한 기존의 최첨단 기술. t-SNE의 일반 및 랜덤워크 버전의 Matlab 구현은 아래와 같음
- 향후 연구에서는 t-SNE에서 사용되는 Student-t 분포의 자유도의 수를 최적화하는 방법을 연구 할 계획
- 저차원 표현의 차원이 많은 경우 차원 축소에 도움이 될 수 있음
- 고차원 데이터 포인트가 여러 개의 저차원 맵 포인트에 의해 표현된 모델에 t-SNE의 확장을 조사 할 것
- t-SNE 목적 함수를 사용하여 저차원 공간에 대한 명시적인 매핑을 제공하는 다층 신경 네트워크를 학습함으로써
- 테스트 데이터에 일반화 할 수 있는 매개변수 버전의 t-SNE를 개발하는 것이 목표




댓글남기기