
INTRO
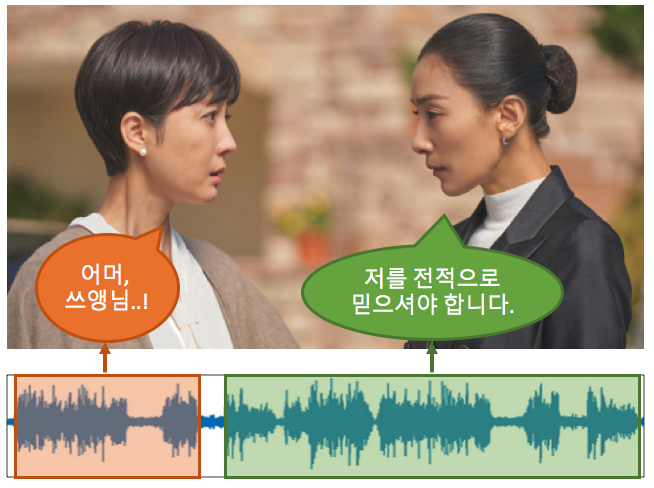
- 여러분이 드라마를 보고 있다고 가정해봅시다. 드라마 속의 등장인물이 대화를 나누고 있고, 이 소리를 들으며 우리는 너무나 당연하게도 누가 어떤 말을 했는지 알 수 있습니다. 스피커에서 흘러나오는 목소리를 통해서, 혹은 드라마에서 보여지는 등장인물의 영상과 목소리를 매칭하는 과정을 통해서 말이죠. 우리가 인지하지도 못할 정도로 너무나 당연스럽게 하는 이 과정을 컴퓨터는 어떻게 할 수 있을까요? 컴퓨터가 이를 어떻게 처리할 수 있게 할까에 대한 접근이 바로 오늘 다룰 Speaker Diarization의 핵심 과제입니다.
- 이름도 생소한 Speaker Diarization(이하 SD)은 컴퓨터가 이러한 과정을 하는 것을 의미합니다. 쉽게 말하면 음성 혹은 비디오 파일에서 “who spoke when?”에 대한 해답을 찾는 문제입니다. 이번 포스트에서는
라는 2012년 공개된 논문을 통해 SD가 무엇인지 간단하게 살펴보고, 이를 위해 어떤 알고리즘이 필요할지 고전적인 접근방법 위주로 알아보도록 하겠습니다.
초기 역사
- 초기 SD에서 연구되던 주요 도메인 분야로 전화 대화, 방송 뉴스, 회의 녹음 이렇게 세가지를 꼽을 수 있습니다. 1990년대 후반과 2000년대 초반에는 전화 대화 도메인과 방송 뉴스 도메인이 연구의 주된 관심사 였고, 전세계에 송출되는 모든 TV와 라디오 프로그램의 자동 주석(annotation)을 목표로 하게 됩니다. (여기에서 주석에는 자동 전사(transcription)와 메타 데이터 레이블링이 포함됩니다. ) 이후 2002년 부터 회의 도메인에 대한 연구로 유럽 연합(EU)의 Multimodal Meeting Manager (M4) 프로젝트, 스위스의 Interactive Multimodal Information Management (IM2) 프로젝트 등의 프로젝트 등이 진행되며 회의 도메인에서의 SD가 주목을 받기 시작합니다. 이러한 프로젝트들은 회의 내용을 자동으로 추출하고 회의 참가자가 정보를 이용 할 수 있게하거나 아카이빙 목적으로 human-to-human 커뮤니케이션(특히 원거리에서의 접근)을 향상시키는 멀티 모달 기술의 연구 및 개발을 다루었습니다.
지금까지 SD가 어떻게 이루어졌는지 알아봤는데요. 이번엔 어떻게 SD가 진행이 되는지 알아보도록 하겠습니다.
주요 접근 방법
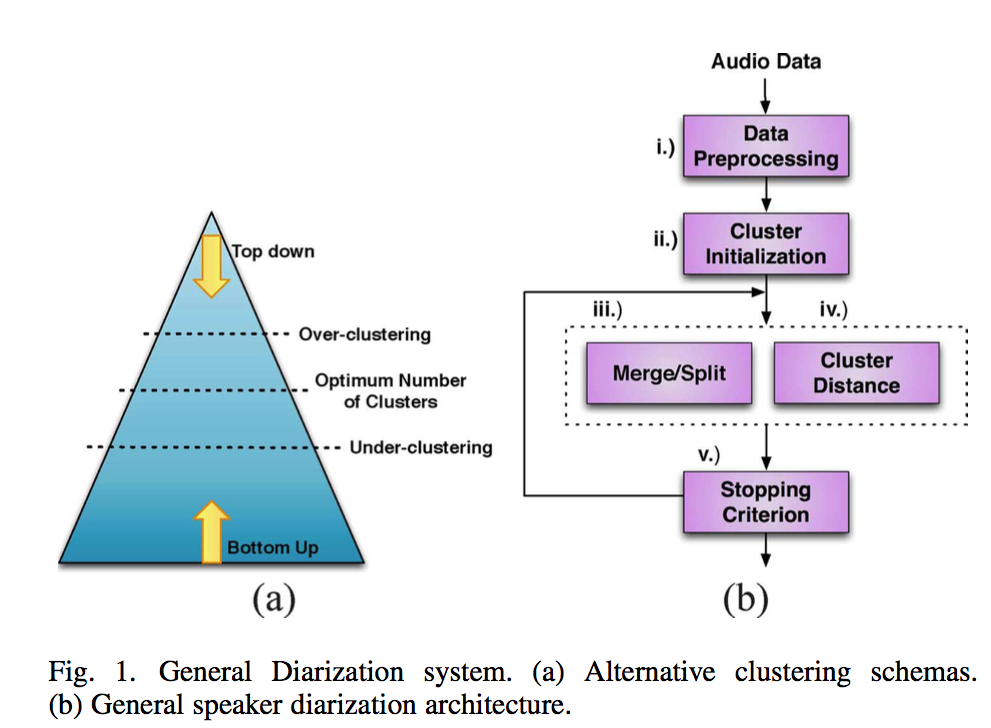
- SD을 위해 주로 사용되는 방식으로 위 그림에서 보는 것 처럼 Top-Down 방식과 Bottom-UP 방식이 있습니다. (이번 포스트에서는 이 두가지에 대해서만 다루도록 하겠습니다. ) Top-Down 방식은 매우 적은 수의 클러스터 (대개 하나)로 초기화되는 반면 Bottom-UP 방식은 많은 클러스터 (예상되는 스피커보다 많은 클러스터)로 초기화됩니다. 두 방식 모두 반복적인 연산을 통해 최적의 클러스터 갯수로 수렴하는 것을 목표로 합니다. 클러스터의 최종 갯수가 최적보다 많으면 Under-clustering이라고 하고, 더 적으면 Over-clustering이라고 합니다. 두 방식 모두 일반적으로 각 state가 화자에 해당하는 가우스 혼합 모델 (GMM)인 히든 마르코프 모델(HMM)을 기반으로 합니다. 여기에서 state 간 전이(transition)는 화자 전환(Speaker turn)에 해당하게 됩니다.
- 각각의 접근 방식에 대해서 더 자세히 알아보도록 하겠습니다.
- Bottom-Up Approach :
- SD를 위해 가장 많이 사용되는 알고리즘이고, AHC(Agglomerative hierarchical clustering)으로 부르기도 합니다. 이 접근 방식은 클러스터 수를 연속적으로 병합하며 줄여나가서 각 화자에 대응하는 하나의 클러스터 혹은 모델이 남을 때까지 학습하는 것을 목표로 합니다. 다양한 초기화가 연구되었고, 일부는 k-means 클러스터링을 연구했지만, 많은 시스템에서는 균일 한 초기화를 사용합니다. 여기서 오디오 스트림은 여러 개의 동일한 길이의 세그먼트로 잘게 나뉩니다. 그리고 나뉘어진 세그먼트는 반복적으로 밀접하게 매치되는 클러스터를 선택하기 때문에 반복 할 때 마다 클러스터 수를 줄이게 됩니다. 클러스터는 일반적으로 GMM으로 모델링되며, 두 개의 클러스터가 병합이 될 때에는 두 개의 개별 클러스터에 할당된 데이터에서 하나의 새로운 GMM을 학습합니다. 프레임을 각 클러스터에 대해 재할당하는 것은 일반적으로 각 클러스터가 병합된 후에 수행합니다. 전체 프로세스는 정지 기준(stopping criterion)이 될 때까지 반복되는데, 이 때 감지된 화자에 대해 하나의 클러스터만 남아있어야 합니다. 정지 기준은 BIC(Bayesian Information Criterion), KL(Kullback-Leibler) 기반 메트릭, GLR (Generalized Likelihood Ratio) 등을 통한 쓰레스홀드 접근을 통해 구할 수 있습니다.
- Top-Down Approach :
- 이 접근 방식은 처음에는 단일 화자 모델로 전체 오디오 스트림을 모델링 한 후에 전체 화자 수가 계산 될 때까지 새 모델을 연속적으로 추가하는 방식입니다. 하나의 GMM 모델은 사용 가능한 모든 음성 세그먼트들을 통해 학습합니다. (이때의 각 음성 세그먼트들은 모두 레이블 되지 않았습니다. ) 레이블 되지 않은 세그먼트로부터 적절한 학습 데이터를 판별하는 선택 방법을 통해서 새로운 스피커 모델이 하나씩 모델에 반복적으로 추가됩니다. 그때마다 새로운 모델에 속한다고 생각되는 세그먼트들을 레이블합니다. Bottom-Up 방식에서 사용 된 것과 유사한 정지 기준을 사용하거나, 새로운 화자 모델을 학습하기에 더이상 적합한 데이터가 없을때까지 반복하여 프로세스를 종료할 수 있습니다. Top-Down 접근 방식은 Bottom-Up 접근 방식보다 대체적으로 성능은 떨어지고 덜 대중적이지만, 계산 효율은 더 높으며 클러스터 정제(purification)을 통해 성능을 향상 할 수 있습니다.
일반적인 SD 아키텍쳐
- Data Preprocessing : 데이터 전처리. 특정 도메인에 따라 경향성을 갖는데, 회의 도메인의 경우에는 잡음 제거(Wiener filtering 등..), 다채널 음향 빔포밍, 피쳐 추출(MFCC, PLP 등..), 음성 구간 검출 등을 필요로 함.
- Cluster Initialization : 클러스터 초기화를 의미하며, 어떻게 초기화할지는 접근 방법(Top-Down or Bottom-Up)에 따라 다름.
- Merge/Split & Cluster Distances : 클러스터간의 거리 측정 알고리즘을 통해 거리를 측정하고, 접근 방법에 따라 클러스터를 나누거나 분리. 경우에 따라서 데이터 정제(data purification)작업을 거치기도 함.
- Stopping Criterion : 최적의 클러스터 갯수가 되었을때의 정지 기준.
주요 알고리즘
- Acoustic Beamforming
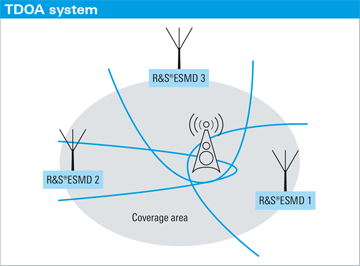
- 회의 도메인에서의 동일한 회의에 참석한 여러 화자의 각각의 위치 파악을 위해서는 여러개의 마이크가 필요했습니다. 마이크는 벽 장착형 마이크, 옷깃 형 마이크, 데스크탑형 마이크, 마이크 어레이 등이 있으며, 이러한 마이크 다수의 조합을 통해 다채널 SD의 접근을 할 수 있게 되었습니다. 화자의 위치 파악을 하는 대표적인 접근은 TDOA(time-delay-of-arrival)로 아래 그림과 같이 음성 소스에서 각 마이크까지 도달하는 시간차는 거리에 비례하므로 이를 통해 위치를 파악하는 방법입니다.
- Speech Activity Detection
- SAD(Speech Activity Detection)는 SD뿐 만아니라 거의 모든 음성 처리(음성코딩, 음성향상, 음성인식 등..)의 기초적인 타스크입니다. 말 그대로 오디오 스트림에서 각 구간이 음성(speech) 구간인지 비음성(non-speech) 구간인지 탐지하는 과정입니다. 비음성 구간의 경우에는 silence 뿐만 아니라 책 넘기는 소리, 바람소리, 노크소리 같은 환경 소음(ambient noise), 그리고 숨소리, 기침소리, 하품, 웃음소리 같은 비어휘 소음(non-lexical noise)까지도 포함하기 때문에 다소 복잡한 타스크라고 할 수 있습니다. 이 SAD는 두가지 이유로 SD의 퍼포먼스를 좌우하게 되는데요. 첫번째로, SD의 성능 평가 방식인 DER(diarization error rate)이 SAD의 거짓 경보(false alarm)와 틀린 speaker error rate를 모두 포함하여 계산되기 때문입니다. 그리고 두번째로 비음성 구간이 앞서 살펴봤던 SD의 비지도적인 학습 과정을 방해 할 수 있기 때문입니다. SAD는 단순하게는 신호 대 잡음비(SNR; signal-to-noise ratio)를 고려하여 쓰레스홀드 기반으로 접근하기도 하는데, 마이크와 주변 환경의 특성을 타기 때문에 이보다는 음성/비음성 두개의 클래스로 분류하는 모델 베이스의 접근법이 일반적으로 사용되고 있습니다.
- Segmentation
- speaker segmentation은 SD 과정의 핵심이며, 화자에 대하여 균질(homogeneous)하도록 오디오 스트림을 잘라서 분리하거나 화자의 변화(speaker turn)를 감지하는 과정입니다. 다시 말해서 각 구간은 한명의 화자의 발화만 있도록 하도록 구간을 나눕니다. 세그먼테이션에 대한 고전적 접근 방식은 중첩되고 연속된 두 개의 윈도우를 이용하여 각 세그먼트들에 대해 가설 검증하는 방식으로 진행된다. (H0 : 한명의 발화이기 때문에 단일 모델로 표현 가능하다, H1 : 다른 발화자가 말했기 때문에 단일 모델로 표현 불가능하다.) 실제적으로 모델은 각각의 음성 창에서 추정되며 두 가지 개별 모델 (따라서 두 개의 개별 스피커) 또는 단일 모델 (따라서 동일한 스피커)에 의해 가장 잘 설명되는지 여부를 결정하는 데 사용됩니다 )에 따라 결정된다. 이것은 전체 오디오 스트림에 걸쳐 수행되며 일련의 화자 전환이 추출됩니다. 거리 계산 방법으로 가장 보편적인 접근법은 BIC(Bayesian Information Criterion) 를 이용한 접근 방법이며, 이 뿐만 아니라 KL(Kullback-Leibler) 기반 메트릭, GLR (Generalized Likelihood Ratio)도 사용 하기도 합니다.
- Clustering
- 세그멘테이션 단계는 인접한 창에서 동일한 스피커에 해당하는지 여부를 결정하기 위해 작동하지만 클러스터링은 오디오 스트림의 어느 위치에나 위치 할 수있는 동일한 스피커 세그먼트를 식별하고 그룹화하는 것을 목표로 한다. 이상적으로 각 스피커마다 하나의 클러스터가 있다고 가정한다. 세그먼트 유사성을 측정하는 문제와 동일하게 유지된다.
- 이제까지 Speaker Diarization의 개념과 역사, 주요 알고리즘에 대해 SD에 대한 고전적인 접근 방법에 대해 알아봤습니다. 다음 ‘Speaker Diarization - 2’ 에서는 보다 현대적인 접근 방법에 대해서 알아보도록 하겠습니다.
참고자료
- Anguera, Xavier, et al. “Speaker diarization: A review of recent research.” IEEE Transactions on Audio, Speech, and Language Processing 20.2 (2012): 356-370.
- S. Tranter and D. Reynolds, “An overview of automatic speaker di-arization systems,” IEEE Trans. Audio, Speech, Lang. Process., vol.14, no. 5, pp. 1557–1565, Sep. 2006.
- https://brunch.co.kr/@cataglyphis/27




댓글남기기