
들어가며
transduction또는transductive learning이라는 용어는 한국어로 변역하기 쉽지 않습니다. 상황에 따라 변환, 전환, 전이, 전도 등 다양하게 번역이 가능하고 다양한 연구 분야에서 이 용어를 각자의 의미로 사용하고 있기 때문입니다. 머신러닝 분야에서도 번역 시 위의 여러가지 단어들이 혼재되거나 원문 그대로 ‘transduction’이라고 사용하는 경우가 많은 상황입니다.- 본 포스트에서는 통일성을 주고 용어에 대한 혼선이나 오해를 방지하기 위해 대부분의 경우는 부득이하게 원문 그대로인 ‘transduction’, ‘transductive learning’이라는 표현을 사용했습니다. 단, 괄호 안에 한국어 번역 표현을 일부 병기한 곳들이 있는데 이런 곳에서는 ‘변환’이라는 용어로 번역했습니다. 교육학에서는 ‘전환적 학습’이라는 용어를 ‘transformative learning’의 번역으로 사용하고 있고 ‘전이 학습’이라는 용어는 일반적으로 ‘transfer learning’의 번역으로, ‘전도’는 보통 ‘conduction’의 번역으로 사용되므로 이들을 제외하면 ‘변환’이라는 용어가 남습니다. 또한 ‘transducer’는 한국말 음차 표현인 ‘트랜스듀서’가 외래어 그대로 쓰이는 경우도 있고 이 편이 더 의미 전달이 쉬울 듯하여 발음 그대로 적었습니다.
- 본 포스트는 ‘transduction’ 개념에 대한 전반적인 이해를 위해 여러 영문 자료들을 번역해 소개했습니다. 되도록 원문을 변형하지 않는 선에서 작성했습니다.
1. Wikipedia: Transduction (machine learning)
- 논리, 통계적 추론 및 지도학습, ‘transduction’(또는 ‘transductive 추론’)는 관찰된 특정 (학습) 데이터에서 특정 (테스트) 데이터를 추론하는 것입니다. 이와 대조적으로 유도/귀납(induction)는 관찰된 학습 데이터에서 테스트 데이터에 적용할 일반적인 규칙을 추론합니다. 이 차이는 ‘transductive’ 모델의 예측이 그 어떤 귀납적(inductive) 모델에 의해서는 얻어질 수 없는 경우에 가장 흥미롭습니다. 이는 서로 다른 테스트 세트에 대해 일치하지 않는 예측을 생성하는 전도성 추론에 의해 발생하는 것이라는 걸 기억하세요.
- ‘transduction’은 1990년대 Vladimir Vapnik에 의해 소개되었는데, 그의 견해에 따르면 ‘transduction’은 유도/귀납(induction)보다 더 선호할만 합니다. 왜냐하면 귀납(induction)은 구체적인 문제(어떤 새로운 task에 대한 결과 계산)를 해결하기 전에 더 일반적인 문제(함수를 추론하는 것)를 먼저 풀어야 하기 때문입니다.
관심있는 문제를 해결할 때 중간 단계로서 보다 일반적인 문제를 해결하지 마십시오. 더 일반적인 답이 아닌 당신이 정말로 필요로 하는 정답을 얻으려고 노력하십시오.
- 버트 랜드 러셀 (Bertrand Russell)도 비슷한 관찰을 하였습니다.
‘모든 사람은 죽는다’라고 생각하고 연역을 사용할 때보다 우리가 순수하게 귀납적으로 주장하면 더 확실성이 큰 방식으로 ‘소크라테스도 죽는다’라는 결론에 도달할 수 있을 것입니다.
(Russell 1912, Chap VII)
- 귀납적이지 않은 학습의 예는 입력 값이 두 그룹으로 클러스터링 되는 이진 분류의 경우입니다. 대량의 테스트 데이터셋은 클러스터를 찾는 데 도움이 될 수 있으므로 분류 레이블에 대한 유용한 정보를 제공하는 데도 도움이 됩니다. 학습 데이터(training cases)에만 근거하여 함수를 유도하는 모델에서는 이와 동일한 예측값을 얻을 수 없습니다. 이는 Vapnik의 생각과는 상당히 다르기 때문에, 일부 사람들은 이러한 형태를 밀접하게 관련된 준지도(semi-supervised) 학습의 예라고 부를 것입니다. 이 범주의 알고리즘의 예는 Transductive Support Vector Machine (TSVM)입니다.
- ‘transduction’으로 이어지는 세 번째 가능한 동기(motivation)는 근사(approximate)에 대한 필요성에 의해 발생합니다. 정확한 추론이 계산적으로 불가능하다면(prohibitive), 어떤 이는 적어도 근사치(approximation)가 테스트셋에 적합하다는 것을 확인하려고 시도할 수 있습니다. 이 경우, 테스트셋은 준지도 학습에서는 허용되지 않는 임의의 분포(학습 데이터의 분포와 반드시 관련있는 것은 아닌)에서 왔을 수 있습니다. 이 범주에 속하는 알고리즘의 예는 Bayesian Committee Machine(BCM)입니다.
Example problem
-
다음 예제 문제는 귀납법(induction)과 비교하여 transduction의 고유한 차이점 중 일부를 보여줍니다.

- 만약 어떠한 점(point)의 모음이 주어졌고, 일부 점에는 A, B, C같은 레이블(label)이 지정되어 있지만 대부분의 점은 레이블이 없는 상태입니다(위 그림에서 ‘?’로 표시된 지점들). 목표는 레이블이 지정되지 않은 모든 점에 대해 적절한 레이블을 예측하는 것입니다.
- 이 문제를 해결하기 위한 귀납적인 접근법은 레이블이 지정된 점들을 사용하여 지도 학습 알고리즘을 학습한 다음, 레이블이 없는 모든 점에 대한 레이블을 예측하도록 하는 것입니다. 그러나 이 문제에서 지도학습 알고리즘은 예측 모델을 구축하기 위한 기초로 오직 5개의 레이블 된 점밖에 가지지 못합니다. 이 데이터의 전체 구조를 파악하는 모델을 구축하는 데는 확실히 어려움을 겪을 것입니다. 예를 들어, 최근접 이웃(nearest-neighbor) 알고리즘이 사용되는 경우, 한가운데 근처에 있는 점은 “B”라는 레이블이 붙은 점과 동일한 클러스터에 속한다는 것이 분명하지만 “A”또는 “C”로 분류됩니다.
- transduction은 레이블 지정 작업을 수행하는 동안 레이블이 지정된 점뿐만 아니라 모든 점을 고려할 수 있다는 이점이 있습니다. 이 경우, transductive 알고리즘은 자연스럽게 속하는 클러스터에 따라 라벨이 지정되지 않은 점을 레이블링합니다. 따라서 한 가운데에 있는 점은 해당 클러스터에 매우 가깝게 뭉쳐 있기 때문에 “B”라고 표시 될 가능성이 큽니다.
- transduction의 장점은, 라벨이 없는 점에서 발견되는 자연적인 중단(natural breaks)을 사용하기 때문에 라벨이 지정된 점이 적을수록 더 나은 예측을 할 수 있다는 것입니다. transduction의 한 가지 단점은 예측 모델을 구축하지 않는다는 것입니다. 이전에 알려지지 않은 점이 집합에 추가되면 라벨을 예측하기 위해 모든 점에 대해 전체 transduction 알고리즘을 반복해야 합니다. 데이터가 스트림을 통해 점진적으로 증가할 경우 계산 비용이 많이 들 수 있습니다. 또한, 이것은 이전 점의 일부 예측이 변경 될 수 있습니다 (적용 상황에 따라 더 좋거나 나쁠 수 있음). 반면에 지도학습 알고리즘은 계산 비용이 거의 들지 않고 즉시 새로운 점에 라벨을 붙일 수 있습니다.
Transduction algorithms
- transduction 알고리즘은 크게 두 가지 범주로 나눌 수 있습니다. 라벨이 지정되지 않은 점에 이산(discrete) 레이블을 할당하려는 것들과 레이블이 지정되지 않은 점에 대한 연속적(continuous) 레이블을 회귀하려는 것들입니다. 이산 레이블을 예측하려는 알고리즘은 클러스터링 알고리즘에 부분적인 지도학습을 추가하여 파생되기도 합니다. 이들은 두 가지 범주로 더 세분화 될 수 있는데, 이는 분할(partitioning)에 의한 군집화 알고리즘과 응집(agglomerating)에 의한 군집화입니다. 연속 레이블을 예측하려는 알고리즘은 매니폴드 학습 알고리즘에 부분적인 지도학습을 추가하여 파생됩니다.
Partitioning Transduction
- ‘Partitioning Transduction’은 하향식(top-down) transduction으로 생각할 수 있습니다. 이는 파티션 기반 클러스터링의 준 지도학습법 확장입니다. 일반적으로 다음과 같이 수행됩니다.
모든 점의 집합을 하나의 큰 파티션으로 간주함 while 어떤 파티션 P가 레이블이 충돌하는 두 개의 포인트를 가짐: 파티션 P를 더 작은 파티션으로 분할 for 각 파티션 P: 동일한 레이블을 P의 모든 포인트에 할당 - 물론 다양한 합리적인 파티셔닝 기법들이 이 알고리즘과 함께 사용될 수 있습니다. Max flow min cut 파티셔닝 방식은 이러한 경우에 매우 인기있는 기법입니다.
Agglomerative transduction
- ‘Agglomerative transduction’은 상향식(bottom-up) transduction으로 생각할 수 있습니다. 이는 응집 클러스터링의 준 지도학습법 확장입니다. 일반적으로 다음과 같이 수행됩니다.
모든 점들 사이의 pair-wise 거리 D를 계산 D를 오름차순으로 정렬 각 포인트들을 크기가 1인 클러스터로 간주 for 각 포인트 쌍 {a, b} in D: if (a가 레이블이 지정되지 않음) or (b가 레이블이 지정되지 않음) or (a와 b가 동일한 레이블을 가짐): a와 b를 포함하는 두 클러스터를 병합 병합된 클러스터의 모든 점에 동일한 레이블을 할당
Manifold transduction
- 매니폴드 학습 기반의 transduction은 여전히 매우 신생의 연구 분야입니다. (자료가 거의 없다는 뜻. 위키 페이지의 설명은 여기서 끝납니다)
2. Gentle Introduction to Transduction in Machine Learning
- 원문: Gentle Introduction to Transduction in Machine Learning(2017-09)
- transduction 또는 transductive learning은 응용 기계 학습에서 볼 수 있는 용어입니다. 이 용어는 자연언어 처리 영역의 문제 등 시퀀스 예측 문제에 대한 RNN의 일부 응용 사례와 함께 사용되고 있습니다. 이 포스트를 통해 기계학습에서의 transduction이 무엇인지 알 수 있게 될 것입니다.
- 이 글을 읽은 후, 당신은 알게 될 것입니다.
- 일반적으로 그리고 일부 특정 연구 분야에서의 transduction의 정의
- 기계 학습에서 transductive learning이란 무엇인가?
- 시퀀스 예측 문제에 대해 이야기할 때 transduction이 의미하는 바는 무엇인가?
Overview
이 튜토리얼은 4 부분으로 나뉩니다.
- transduction이란 무엇인가?
- transductive learning
- 언어학에서의 transduction
- 시퀀스 예측에서의 transduction
transduction이란 무엇인가?
우선 몇 가지 기본적인 사전 정의부터 시작해 봅시다. transduce란 무언가를 다른 형태로 변환하는 것을 의미합니다.
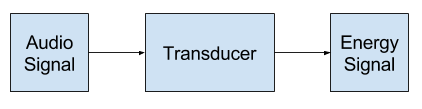
변환 : (에너지 또는 메시지와 같은) 다른 형태로 전환하는 것은 본질적으로 감각 기관으로 물리적 에너지를 신경 신호로 변환합니다.
“트랜스듀서(변환기)”는 소리를 에너지 또는 그 반대로 변환하는 구성 요소 또는 모듈의 일반적인 이름인 전자 및 신호 처리 분야에서 널리 사용되는 용어입니다.
모든 신호 처리는 입력 변환기로 시작합니다. 입력 변환기는 입력 신호를 가져 와서 전기 신호로 변환합니다. 신호 처리 응용 프로그램에서 변환기는 여러 가지 형태를 취할 수 있습니다. 입력 변환기의 일반적인 예는 마이크입니다.
생물학, 특히 유전학에서 transduction은 유전 물질을 한 미생물에서 다른 미생물로 옮기는 프로세스를 의미합니다.
변환 : 변환의 작용 또는 과정; 특히 : 바이러스 성 물질 (예 : 박테리오파지)에 의해한 미생물에서 다른 미생물로 유전 물질을 전달하는 것
그래서 일반적으로 우리는 ‘transduction’이 신호를 다른 형태로 변환하는 것에 관련되어 있다는 걸 알 수 있습니다. 신호 처리 설명은 음파가 시스템 내에서 일부 용도로 전기 에너지로 전환되는 가장 두드러진 부분입니다. 각 사운드는 일부 선택된 샘플링 수준에서 전자적 특성으로 표시됩니다.
transductive learning
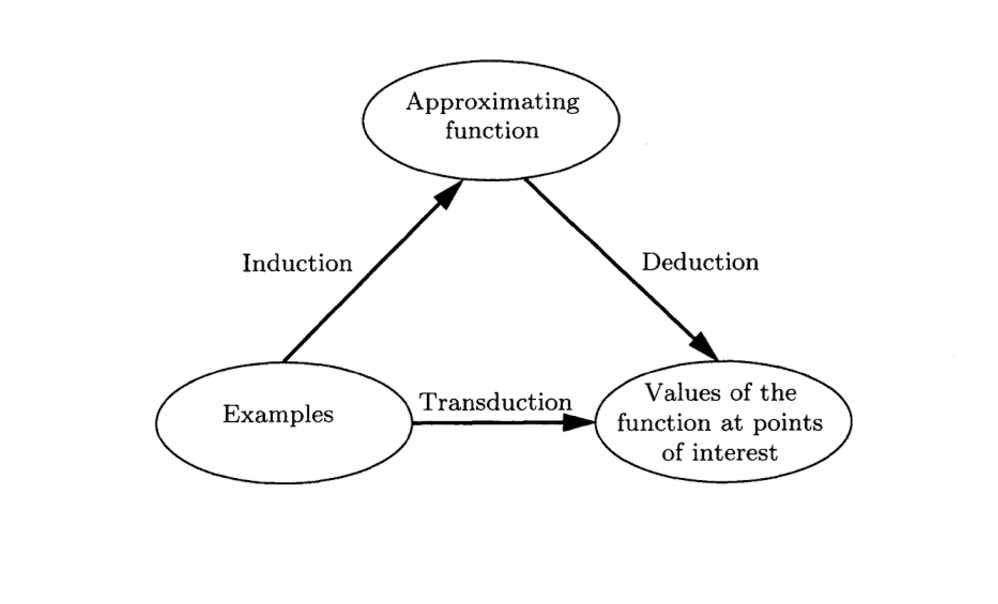
transduction 또는 transductive learning은 통계 학습 이론 분야에서 도메인 내의 주어진 특정 예제(example)를 이용해 다른 특정 예제를 예측하는 것을 설명하기 위해 사용됩니다. 이는 귀납적 학습 및 연역적 학습과 등의 다른 유형의 학습과 대조됩니다.
귀납(induction), 주어진 데이터에서 함수를 유도합니다. 연역(deduction), 관심있는 점에 대해 주어진 함수의 값을 유도합니다. 변환(transduction), 주어진 데이터에서 관심있는 점에 대해 알려지지 않은 함수의 값을 유도합니다.
Page 169, The Nature of Statistical Learning Theory》, 1995
이는 “데이터로부터 매핑 함수를 근사하고 예측을 위해 그것을 사용하는” 고전적인 문제가 필요 이상으로 어려워 보이는 지도 학습(supervised learning)에 반하는 흥미로운 프레임입니다. 대신 특정 예측은 도메인의 실제 샘플에서 직접 수행됩니다. 여기서는 함수 근사(function approximation)가 필요하지 않습니다.
주어진 관심 지점에서 함수의 값을 추정하는 모델은 추론의 새로운 개념을 설명합니다. 즉, 특정 지점에서 특정 지점으로 이동합니다. 우리는 이런 종류의 추론을 전도성 추론(transductive inference)이라고 부릅니다. 제한된 양의 정보에서 가장 좋은 결과를 얻고 싶을 때 이러한 추론 개념이 나타난다는 사실에 주목하세요.
Page 169, The Nature of Statistical Learning Theory》, 1995
transductive 알고리즘의 고전적인 예는 학습 데이터를 모델링하지 않고 예측이 필요할 때마다 이를 직접 사용하는 k-Nearest Neighbors(k-NN) 알고리즘입니다.
transduction은 인스턴스 기반 또는 사례 기반 학습으로 알려진 일련의 알고리즘과 자연스럽게 관련됩니다. 아마도 이 부류에서 가장 잘 알려진 알고리즘은 k-NN 알고리즘일 것입니다.
Learning by Transduction, 1998
언어학에서의 transduction
고전적으로, 언어학 분야와 같이 자연어(natural language)에 대해 이야기 할 때 transduction이 사용되어 왔습니다. 예를 들어 한 언어를 다른 언어로 변환하기 위한 일련의 규칙을 나타내는 “변환 문법(transduction grammar)”이라는 개념이 있습니다.
변환 문법(transduction grammar)은 구조적으로 상관된 언어 쌍을 설명합니다. 이는 단일 문장이 아닌 문장 쌍(pair)을 생성합니다. 1번 언어의 문장은 (의도에 따르면) 2번 언어 문장의 번역입니다.
Page 460, Handbook of Natural Language Processing, 2000.
또한 한 세트의 기호를 다른 기호에 매핑하기 위한 번역 task에 대해 이야기 할 때 언급되곤 하는 계산 이론에서의 “유한 상태 변환기”(FST; Finite State Transducer)라는 개념이 있습니다. 중요한 것은, 각각의 입력이 하나의 출력을 생성한다는 것입니다.
유한 상태 변환기(finite state transducer)는 여러 개의 state로 구성됩니다. 상태 간 전환시 입력 기호가 소비되고 출력 기호가 방출됩니다.
Page 294, Statistical Machine Translation, 2010.
이론과 고전 기계 번역에 대해 이야기할 때의 transduction의 사용은 NLP task에 RNN을 이용하는 오늘날 시퀀스 예측에서의 쓰임과 의미가 많이 달라, 이 용어의 사용에 부정적인 영향을 미칠 수 있습니다.
시퀀스 예측에서의 transduction
Yoav Goldberg는 언어처리를 위한 신경망에 관한 그의 교과서에서 트랜스듀서(변환기)를 NLP task를 위한 특정 네트워크 모델로 정의했습니다. 트랜스듀서는 좁게 정의한다면 제공된 각 input time step에 대한 하나의 time step(output)을 출력하는 모델이라 할 수 있습니다. 이것은 특히 유한 상태 변환기(finite state transducer)와 함께 언어적 사용법까지 연결됩니다.
또다른 옵션은 RNN을, 읽어들이는 각 입력(input)에 대한 출력(output)을 생성하는 변환기로써 바라보는 것입니다.
Page 168, Neural Network Methods in Natural Language Processing, 2017.
그는 언어 모델링뿐만 아니라 시퀀스 태깅을 위한 이러한 유형의 모델을 제안하였는데, 또한 인코더-디코더 아키텍처와 같은 조건부 생성(conditioned generation)이 RNN 트랜스듀서의 특별한 케이스로 간주 될 수 있음을 지적합니다. 이 마지막 부분은 인코더-디코더 모델 아키텍처의 디코더가 주어진 입력 시퀀스에 대해 다양한 개수의 출력을 허용하여 기존 정의에서의 “입력 당 하나의 출력”을 깬다는 점에서 놀랍습니다.
보다 일반적으로 transduction은 NLP 시퀀스 예측 작업, 특히 번역에 사용됩니다. 이 정의는 Goldberg와 FST의 엄격한 “입력 당 하나의 출력”보다 더 받아들이기 수월합니다. 예를 들어 Ed Grefenstette, et al.은 transduction을 입력 문자열을 출력 문자열에 매핑하는 것으로 설명합니다.
많은 자연어 처리 (NLP) task는 하나의 문자열을 다른 문자열로 변환하는 것을 배우는 transduction 문제로 볼 수 있습니다. 기계 번역은 transduction의 전형적인 예이며, 최근의 연구 결과들은 Deep RNN이 긴 원본 문자열을 인코딩하여 일관성 있는 번역문을 생성할 수 있음을 보여줍니다.
그들은 이 광범위한 정의를 구체적으로 만드는 데 도움이 되는 특정 NLP task 목록을 제공합니다.
문자열 transduction은 이름 음차 및 철자 수정에서 굴절 형태학 및 기계 번역에 이르기까지 NLP의 많은 응용 분야에서의 핵심입니다.
또한 Alex Graves는 ‘transduction’을 ‘transformation’의 동의어로 사용하며, 이러한 정의를 충족시키는 유용한 예제 NLP task 목록을 제공합니다.
몇 가지 예를 들자면 많은 기계 학습 task들은 다음과 같은 입력 시퀀스로부터 출력 시퀀스로의 transformation - 또는 transduction - 으로 표현 될 수 있습니다: 음성인식, 기계 번역, 단백질 2차 구조 예측 및 TTS 등
요약하면 다음과 같이 transductive 자연어처리 task 목록을 다시 작성할 수 있습니다.
- 음역(transliteration): 소스 형식의 예제에 따라 대상 형식으로 단어를 생성
- 철자 수정(spelling correction): 주어진 잘못된 단어 철자에서 올바른 단어 철자를 생성
- 굴절 형태학(inflectional morphology): 소스 시퀀스와 컨텍스트가 주어진 새로운 시퀀스를 생성
- 기계번역: 소스 언어로된 예제에서 대상 언어로 단어 시퀀스를 생성
- 음성인식: 주어진 오디오 시퀀스로 텍스트 시퀀스 생성
- 단백질 2차 구조 예측: 아미노산의 입력 서열(NLP가 아닌)이 주어진 3D 구조를 예측
- TTS(Test-To-Speech) 또는 음성 합성으로 오디오 주어진 텍스트 시퀀스를 생성
마지막으로, 광범위한 NLP 문제와 RNN 시퀀스 예측 모델을 언급하는 transduction 개념 외에도 일부 새로운 방법론들이 명시적으로 명명되고 있습니다. Navdeep Jaitly, et al.은 기술적으로 sequence-to-sequence 예측을 위한 RNN이 될 “뉴럴 트랜스듀서”로서 새로운 RNN sequence-to-sequence 예측 방법을 언급합니다.
우리는 seq-to-seq 학습 모델보다 일반적인 종류인 ‘뉴럴 트랜스듀서’를 제시합니다. 뉴럴 트랜스듀서는 입력 블록이 도착하면 출력 chunk(길이가 0일 수 있는)를 생성 할 수 있으므로 “온라인”상태를 만족시킵니다. 이 모델은 seq-to-seq 모델을 구현하는 트랜스듀서 RNN을 사용하여 각 블록에 대한 출력을 생성합니다. A Neural Transducer, 2016
추가적인 읽을거리
이 섹션에서는 당신이 더 깊게 들어갈 경우를 위해 본 주제에 대한 더 많은 리소스를 제공합니다.
정의
- Merriam-Webster Dictionary definition of transduce
- Digital Signal Processing Demystified, 1997
- Transduction in Genetics on Wikipedia
학습 이론
- The Nature of Statistical Learning Theory, 1995
- Learning by Transduction, 1998
- Transduction (machine learning) on Wikipedia
언어학
- Handbook of Natural Language Processing, 2000.
- Finite-state transducer on Wikipedia
- Statistical Machine Translation, 2010.
시퀀스 예측
- Neural Network Methods in Natural Language Processing, 2017.
- Learning to Transduce with Unbounded Memory, 2015.
- Sequence Transduction with Recurrent Neural Networks, 2012.
- A Neural Transducer, 2016
3. An Analysis of Graph Cut Size for Transductive Learning
- 원문: An Analysis of Graph Cut Size for Transductive Learning(2010-04)
- 본 자료는 슬라이드 강의안입니다(부분 발췌)
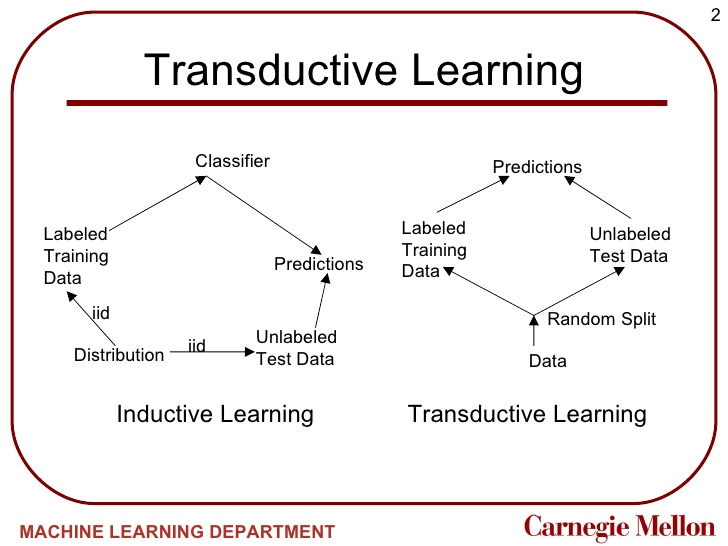
- 만약 관계들로 이루어진 그래프와 일부 노드의 레이블을 가지고 있으면 이를 이용해 나머지 노드로 전파할 수 있음
- 레이블이 지정된 노드를 나머지 그래프에 대한 확률을 흡수하고 계산하도록 함
- ex. 일부 사람들이 스팸 발송자로 태그된 소셜 네트워크
- ex. 일부 영화들이 액션 또는 코미디로 태그된 영화 배우 그래프
- 이는 준 지도(semi-supervised) 학습의 한 형태임
- 레이블이 없는 데이터와 관계성을 사용
- 모델을 생성하지 않기 때문에 transductive learning이라고도 하며, 현재 레이블이 없는 데이터에 즉시 사용할 수 있도록 레이블을 부여함
- 모델을 학습하고 새로운 예제들을 바로 라벨링할 수 있는 귀납적(inductive) 학습과 대조됨
다음 포스트
- 다음으로는 ‘Graves, Alex. “Sequence transduction with recurrent neural networks.” arXiv preprint arXiv:1211.3711 (2012).’ 페이퍼를 리뷰할 예정입니다.




댓글남기기