
참고자료
- 원 논문 (Skill Rating for Generative Models)
- GAN
들어가기 전에 GAN에 대해서
- GAN
- 생성 모델 : 생성 모델은 기존의 x를 나타내는 probability distribution을 생성하여 판별 모델을 속이는
- 판별 모델 : 판별 모델은 real vs fake를 구별하는 것이 목표
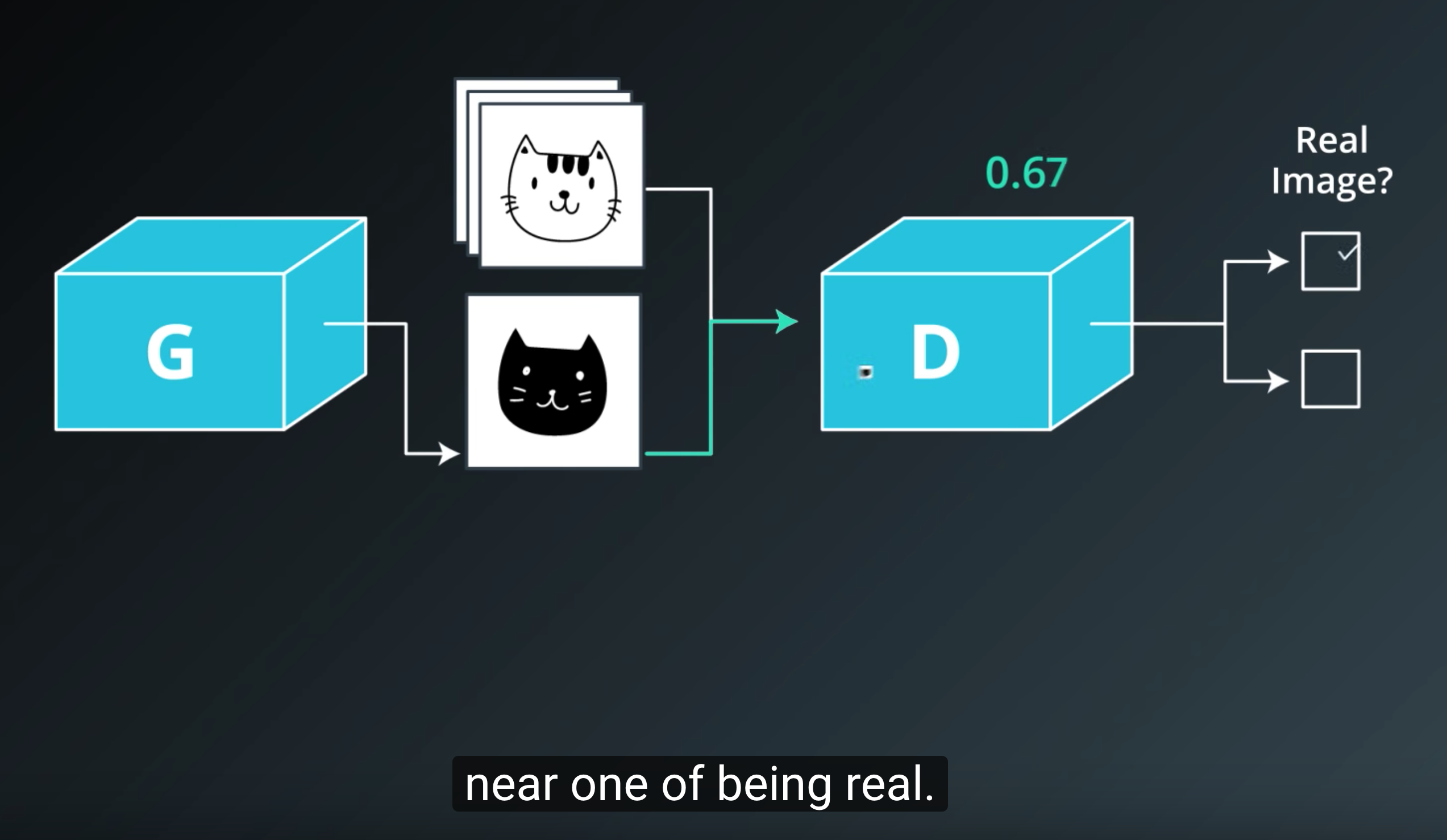

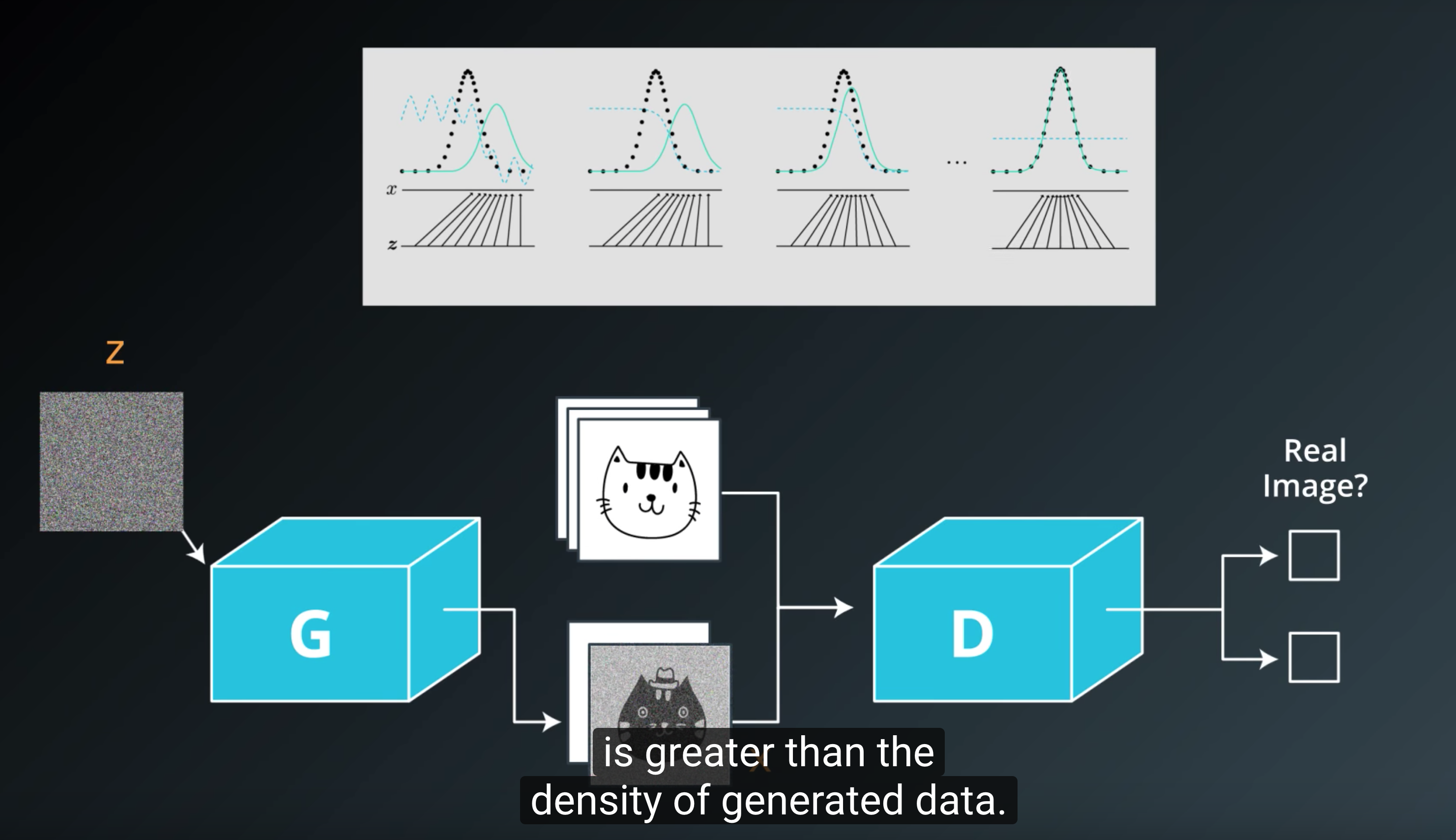

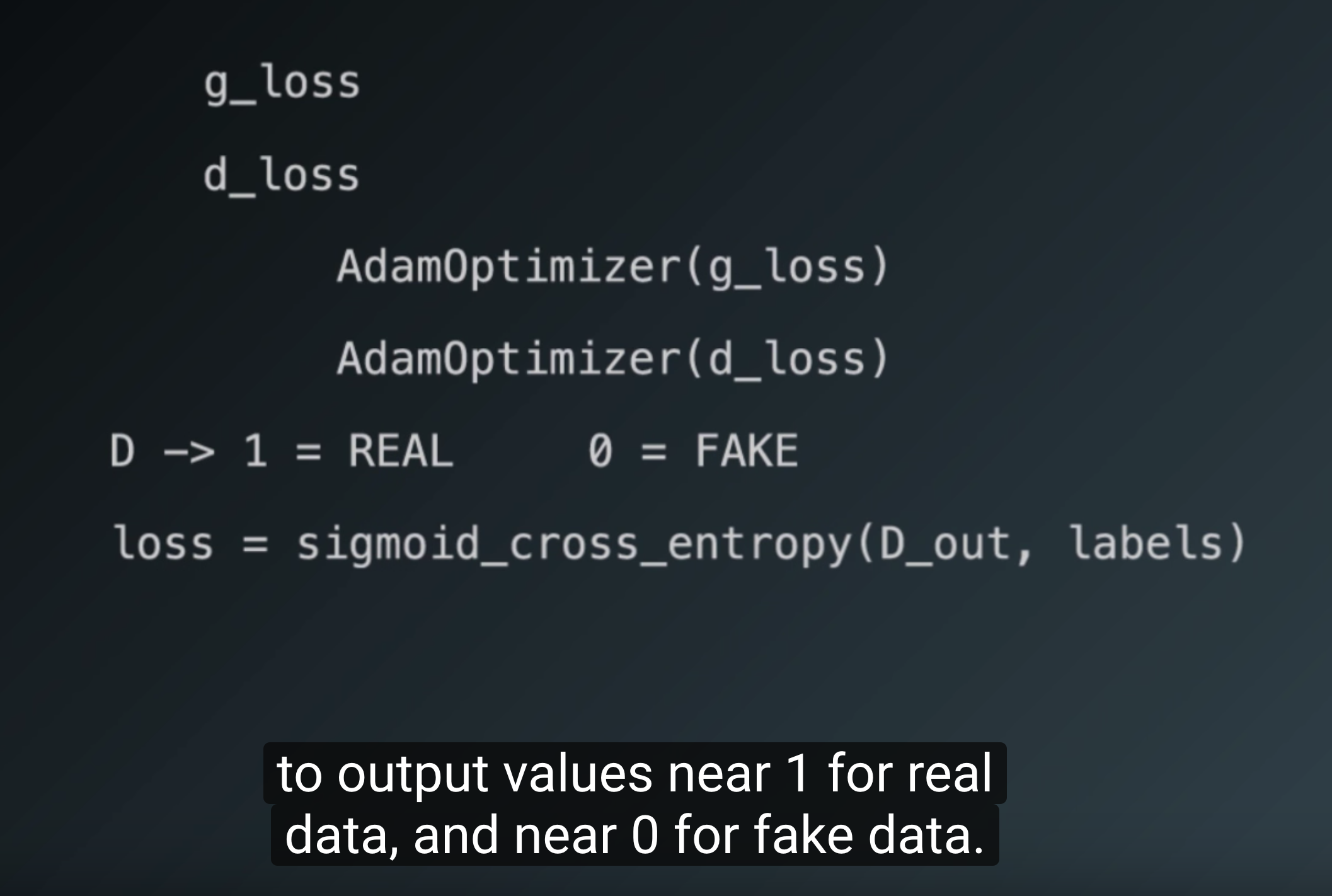
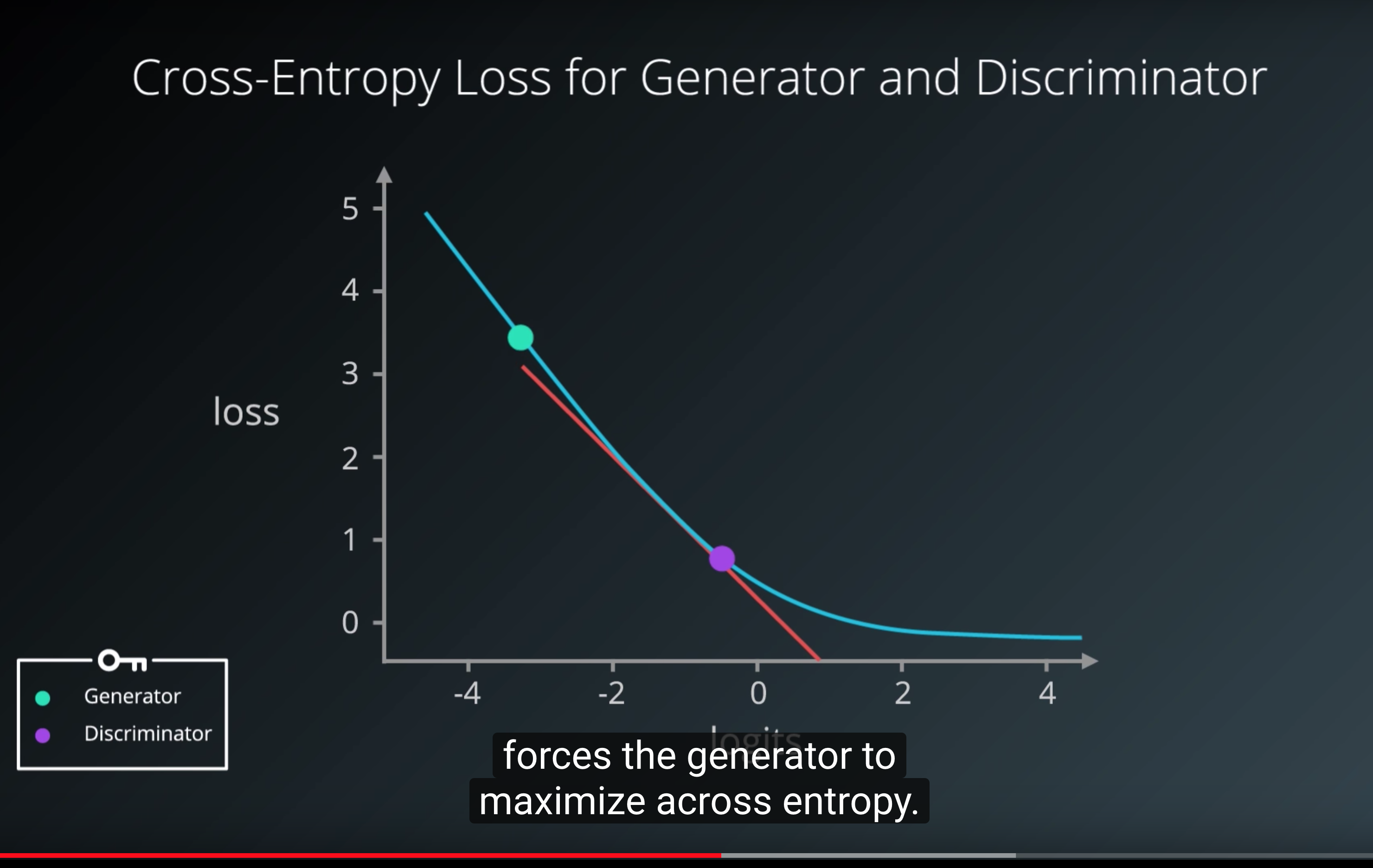
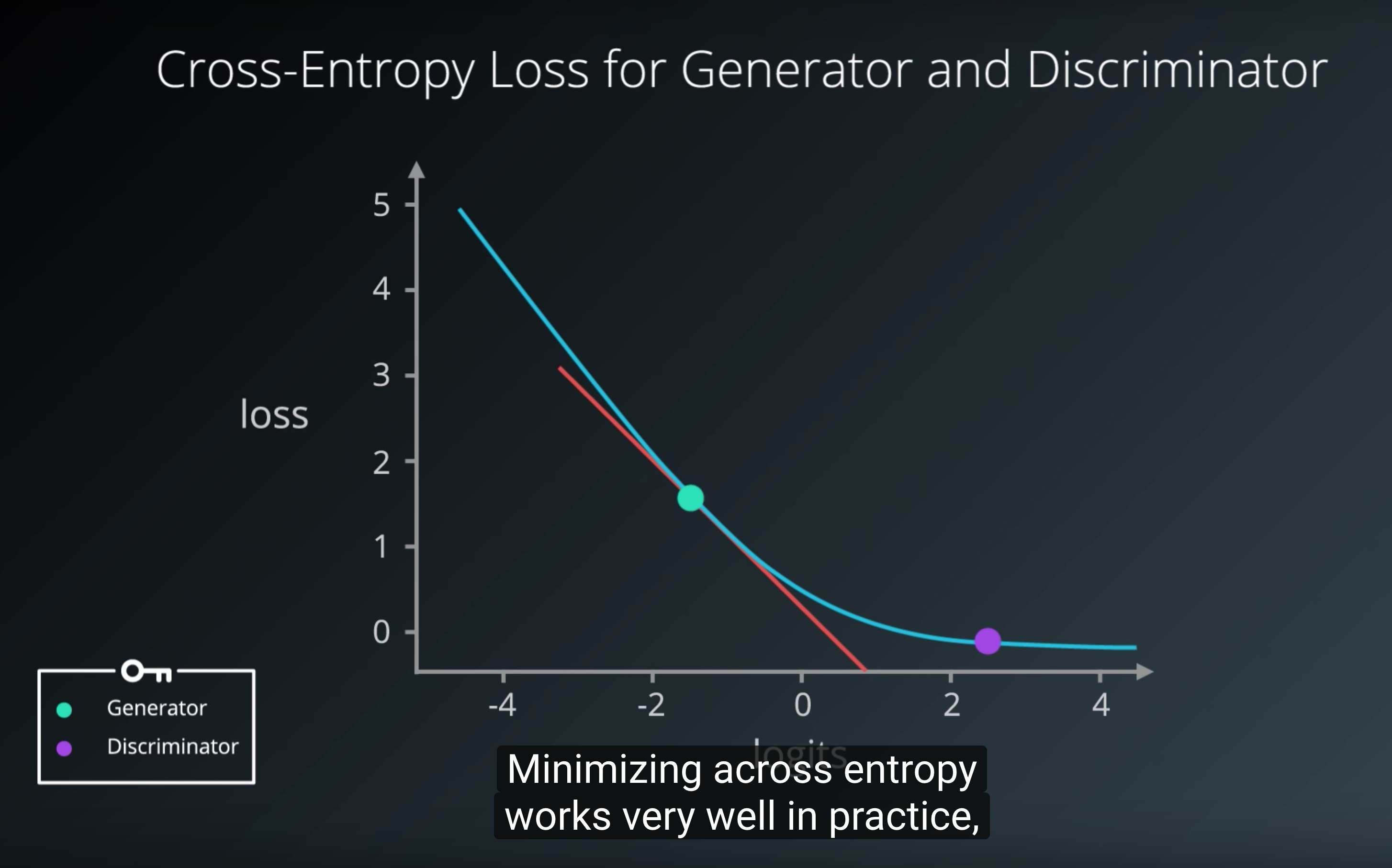
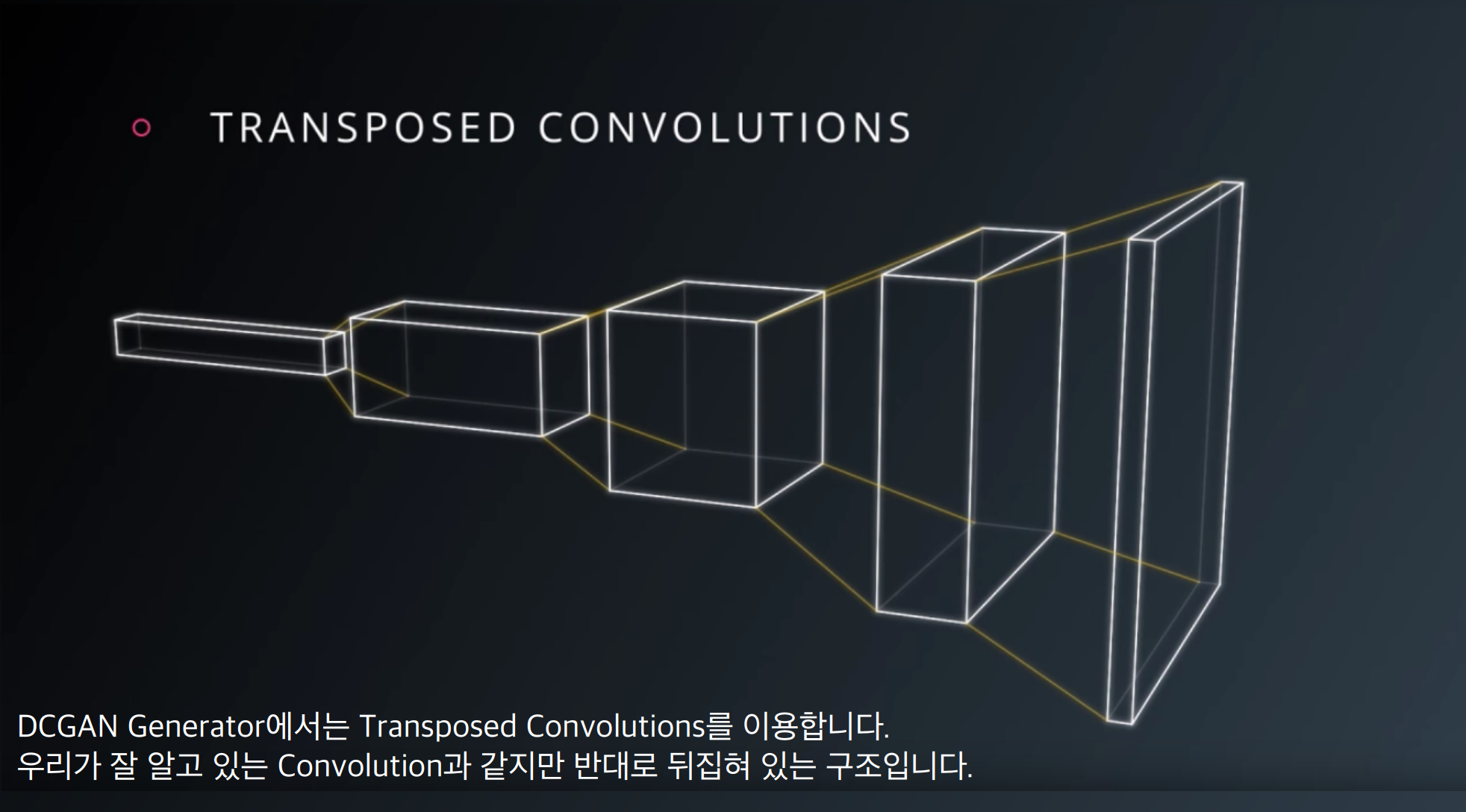
- Generator 아웃풋에는 tanh, Discriminator 아웃풋에는 sigmoid를 쓴다, Discriminator loss를 계산할 때는 sigmoid를 통과하기 전인 logits을 씀
- GAN 문제는 minimax problem
- G∗ = minG maxD V(G,D) vs G∗ = maxD minG V(G,D)
- 실제 학습을 할 때는 G와 D에 대한 update를 번갈아가며 해주기 때문에 Neural network의 입장에서는 minimax 와 maximin problem이 구별이 되지 않음
-
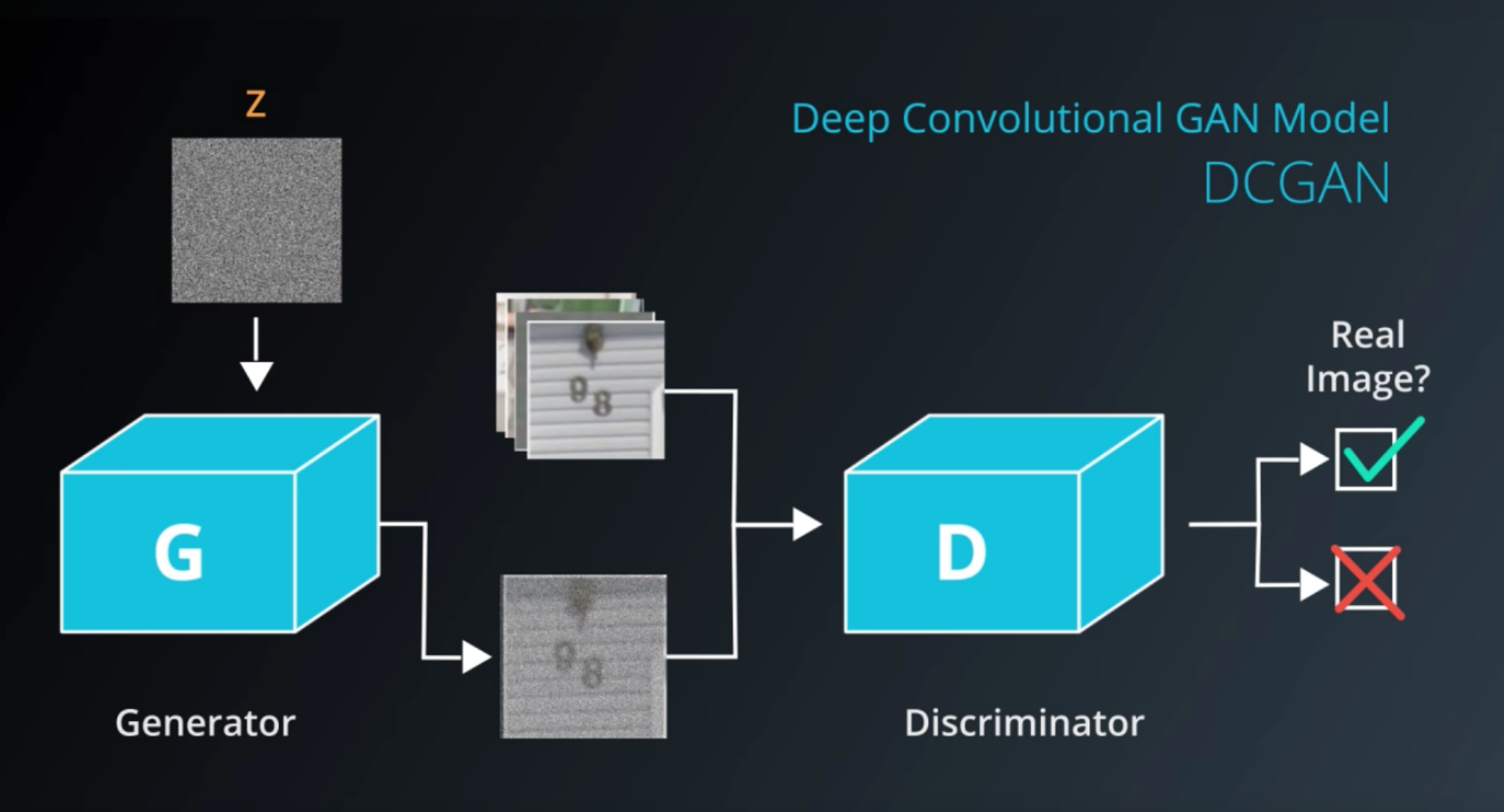
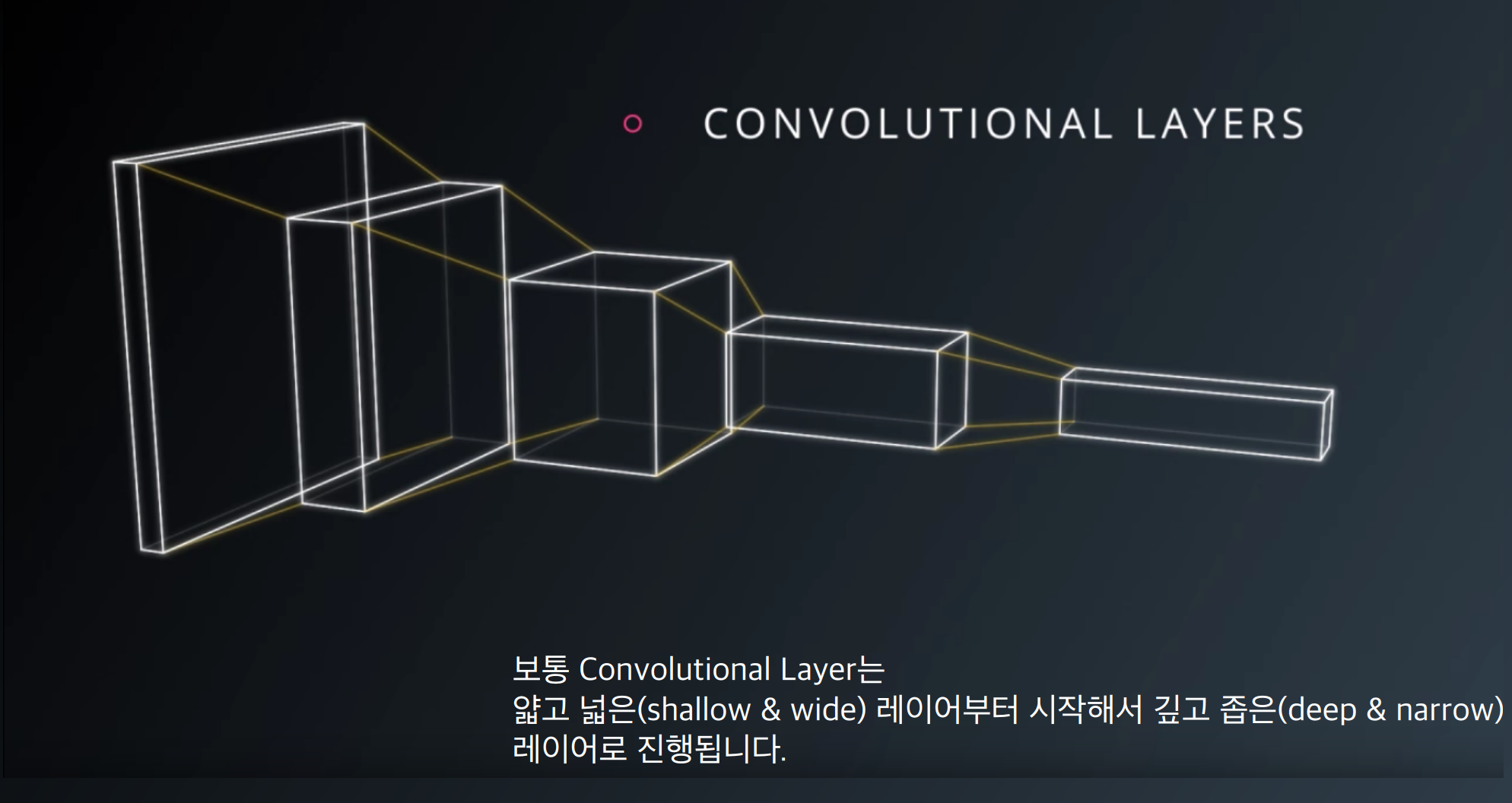
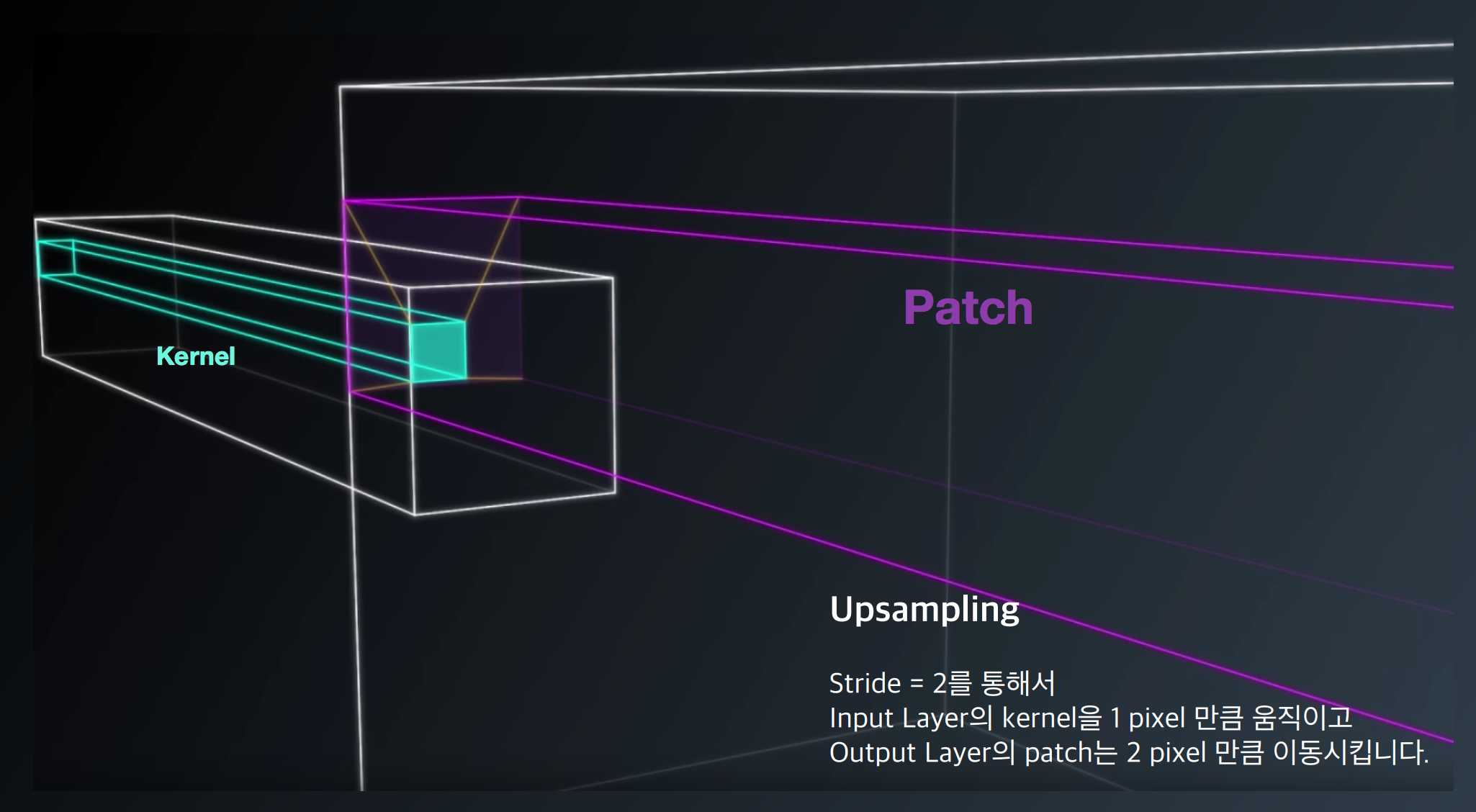
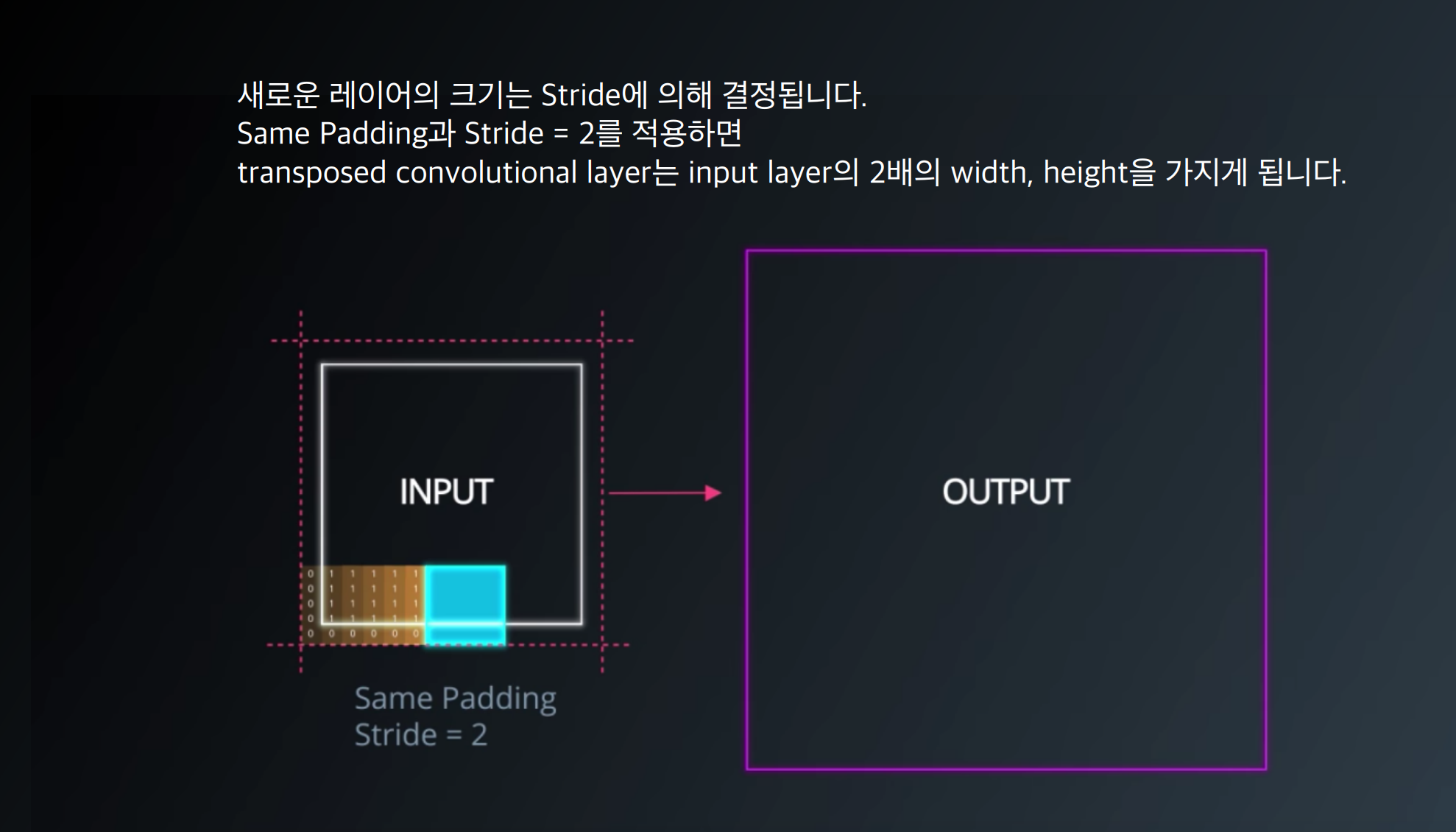
DCGAN
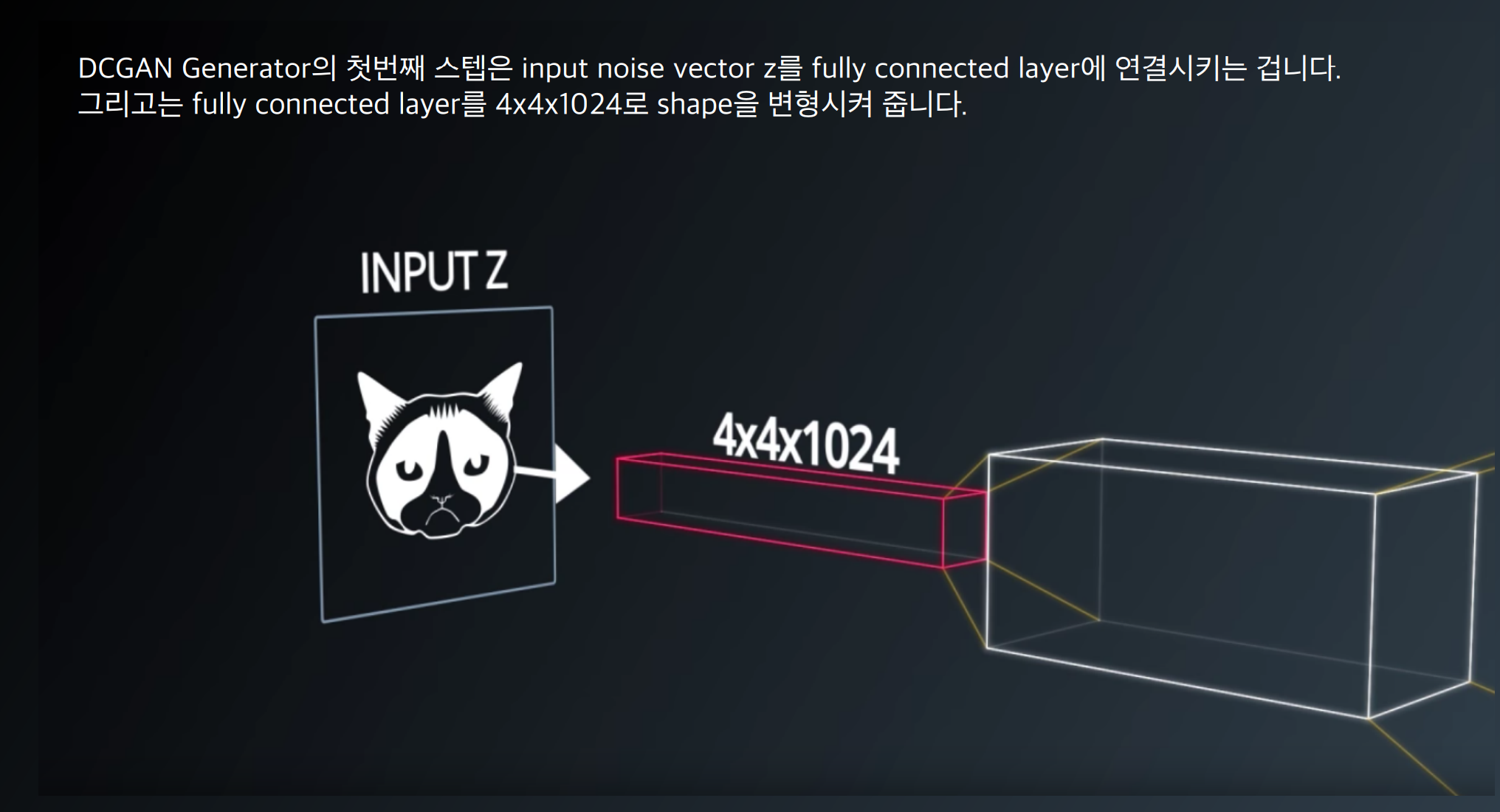
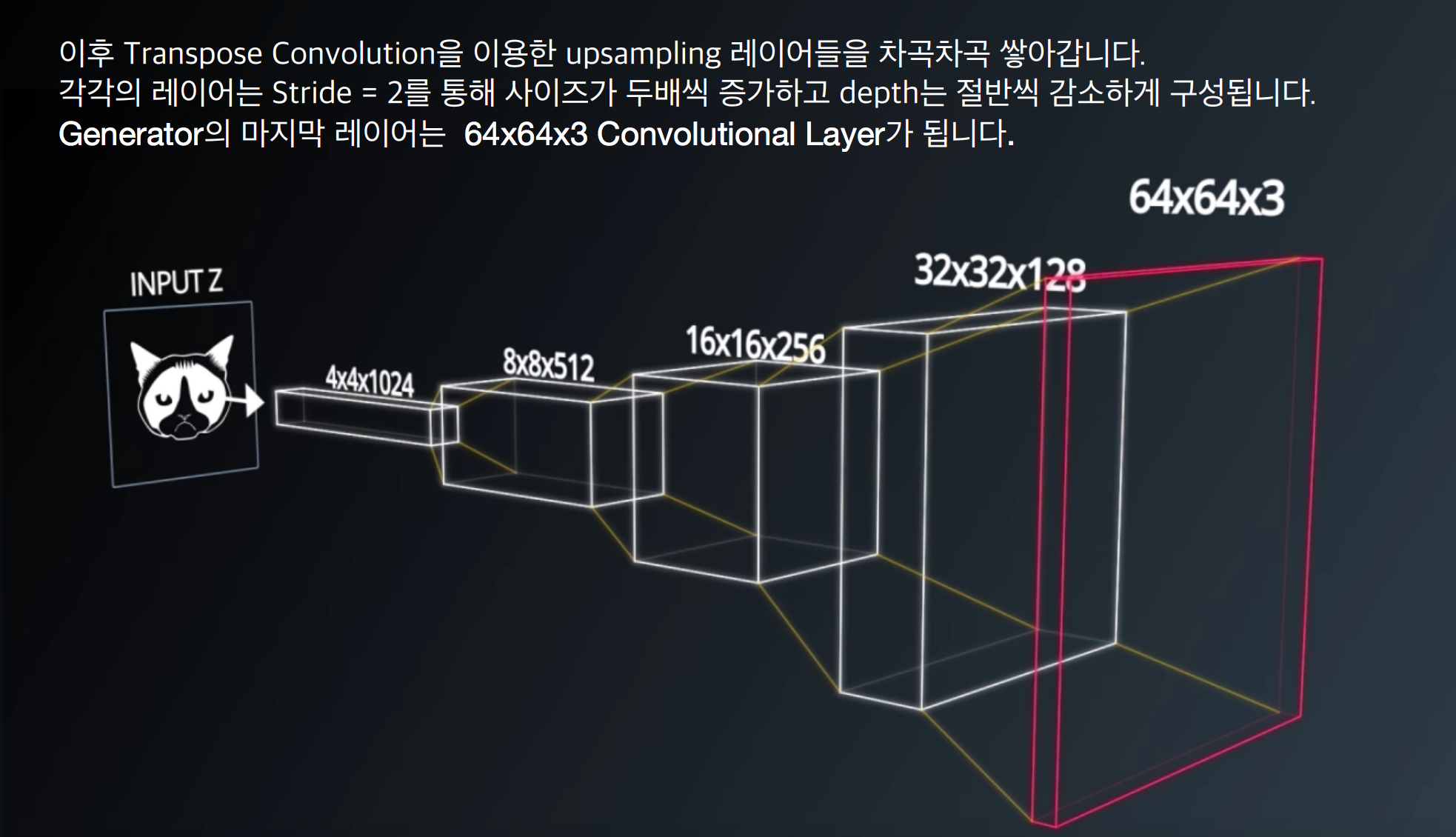
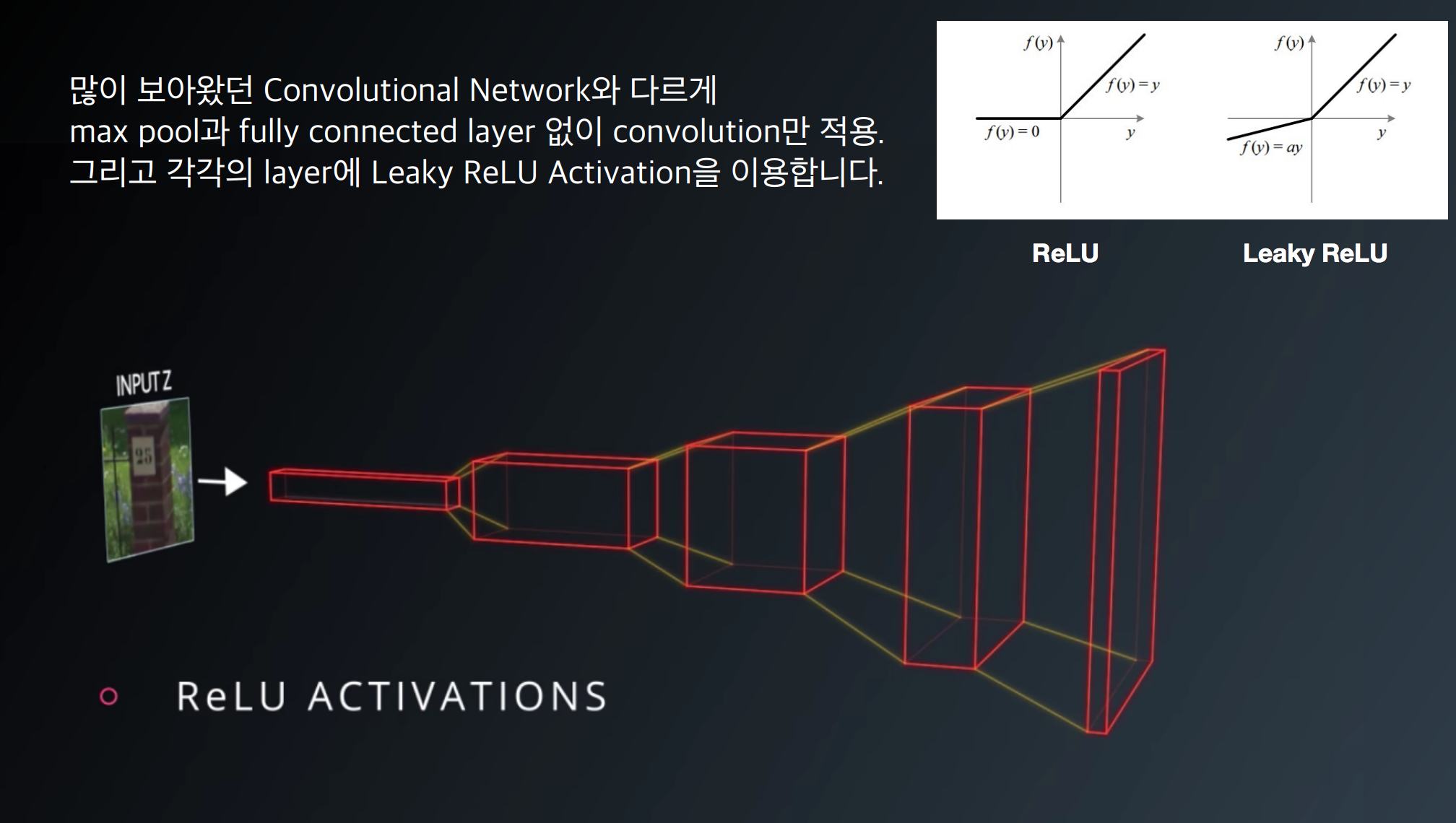
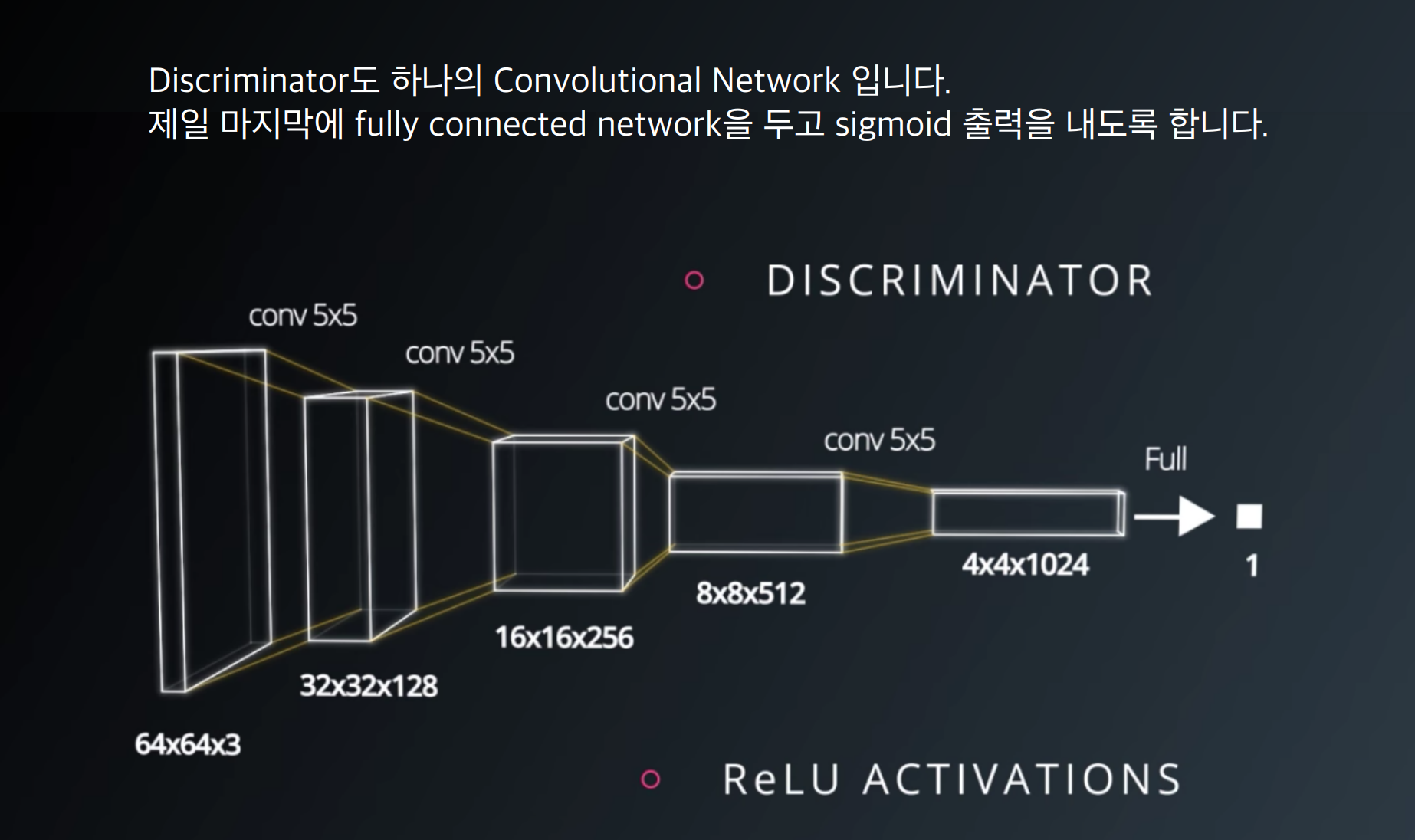
- SVHN
- Street View House Numbers, SVHN 데이터는 구글이 구글 지도를 만드는 과정에서 촬영한 영상에서 집들의 번호판을 찍어 놓은 32x32 크기의 RGB 데이터 (번호판 숫자 데이터)
ABSTRACT
- human players 간의 게임 경쟁 평가 모델(trueskill, Gilcko2)의 통찰력을 사용하여 생성 모델을 evaluate 하는 새로운 방법을 모색
- 생성 모델과 판별 모델 간의 토너먼트가 생성 모델을 평가하는 효과적인 방법을 제공한다는 것을 실험적으로 보여줌
- 토너먼트 결과를 요약하는 두 가지 방법, 즉 토너먼트 승률과 skill rating을 소개
- 평가는 훈련 과정에서 학습 할 때 단일 모델의 진행 상황을 모니터링하고 완전하게 훈련된 두 가지 모델의 기능을 비교하는 것을 포함하여 다양한 상황에서 유용
- 과거 및 미래의 버전을 상대로 한 단일 모델로 구성된 토너먼트가 유용한 훈련 진행 방법을 제시한다는 것을 보여줌
- 다양한 시드 모델, 하이퍼 매개 변수 및 아키텍처를 사용하는 여러 개의 개별 모델을 포함하는 토너먼트는 서로 다르게 훈련 된 GAN 간의 유용한 상대 비교를 제공
- 토너먼트 기반 평가 방법은 개념적으로 생성 모델 평가에 대한 이전의 수많은 방법 (사람 평가,거리 기반)과 구별되며 보완적인 장점과 단점이 있음
1. INTRODUCTION
- 생성 모델의 평가는 어려운 작업. 토너먼트에서 경쟁하는 적대적 과정을 통해 생성 모델을 평가하는 새로운 프레임워크를 제안
- 체스나 테니스와 같은 게임에서 Elo 또는 Glicko2 와 같은 skill rating 시스템은 여러 플레이어의 승리와 패배 기록을 관찰하고 관찰되지 않은 스킬 변수의 가치를 추론하여 플레이어를 평가
- GAN(Generative adversarial Network)에 의해 사용되는 2인용 구별된 게임의 멀티 플레이어 토너먼트(예, 리그전)를 구성함으로써 생성모델 평가를 잠재적인 스킬 레이팅 평가 문제로 재구성
- 토너먼트에 참여하는 생성 모델의 (latent) skill rating을 계산
- 토너먼트의 각 플레이어는 실제 데이터와 가짜 데이터를 구별하는 판별 모델이 fake 데이터를 real로 받아들이려고 시도하는 생성 모델 중 하나
- 토너먼트 평가 프레임워크는 주로 GAN을 염두에 두고 설계되었지만 GAN과 비슷한 역할을 수행 할 수있는 모든 모델의 기술을 평가할 수 있음 (예, explicit density model 와 같은 모델)
- 토너먼트 승률 : each generator’s average rate of successfully fooling the set of discriminators in the tournament
- Skill rating : 스킬레이팅 시스템이 토너먼트 결과에 적용되어 each generator 에 대한 Skill rating 값을 산출
- 토너먼트 결과가 생성 모델을 평가하는 효과적인 방법을 제공한다는 것을 실험적으로 나타냄
- 토너먼트가 훈련된 것 이외의 생성 모델의 값들이 판별 모델에 대한 액세스 없이도 훈련에 대한 유용한 측정을 제공한다는 것
- 둘째, 서로 다른 seed, 하이퍼 파러미터 및 아키텍처를 가진 다양한 GAN 모델 간의 스냅샷 데이터를 가지고 토너먼트에서 유용한 비교를 제공
2. Context and Related Work
- 생성 모델을 개선하기 위한 연구 노력은 생성 모델에 대한 정확한 평가가 필요한 상황
- 그러나 생성 모델에서 원하는 것을 정량적으로 지정하는 것은 개념적으로 매우 어렵고 많은 평가 메트릭의 값을 계산하는 것이 어려움
- 토너먼트 기반 메트릭은 계산적으로 다루기 쉽고 기존의 평가 방법과 개념적으로 구별 되며 이전 방법들에 비해서 보완적인 장점과 단점을 제공
- 생성 모델의 공통된 척도는 모델이 테스트 데이터 포인트 x를 할당한 log-likelihood 을 보고 샘플을 사용하여 우도를 추정하는 것
- GAN에서는 likelihood 함수를 근사하지 않고 샘플을 뽑아내는 함수를 학습했기 때문에 가장 보편적인 대안은 표본 품질에 대한 개념을 평가하는 것
- 1) 사람에 의한 평가
- 평가를 재현하기 어렵고 사람마다 다름 (다른 평가자가 다른 판단을 내리기 때문에 재현할 수 없는 결과를 산출 할 수 있음)
- 많은 기계 터크(Mechanical Turk) 사람들을 속여 동일한 샘플을 보냈음에도 불구하고 GAN 샘플을 탐지할 수 있는 능력이 거의 완벽함을 발견
- 또한, crowdworkers의 다른 하위 집단은 작업 구조와 지불 및 요청자의 커뮤니티 평판에 따라 다른 작업을 받아들일 수 있는 문제
- 사람이 평가하게 되면 mode collapse (폭넓게 생성하지 못하는) 문제가 발생할 수 있음, 뽑아낸 이미지는 완벽할 수 있지만 이미지의 다양성이 부족해질 수 있음
- 평가를 재현하기 어렵고 사람마다 다름 (다른 평가자가 다른 판단을 내리기 때문에 재현할 수 없는 결과를 산출 할 수 있음)
- 2) Inception Score는 다양한 종류의 인식 가능한 클래스를 생성하는 모델 기능을 평가하지만 생성된 샘플의 다른 모든 측면은 무시됨
- Inception Score은 구글의 인셉션 이미지 분류 모델에 생성된 데이터를 넣고 나오는 값을 가지고 판단
- 유사 형태는 end-to-end 시스템에서 생성 모델을 구성 요소로 사용하고 시스템 전체의 성능을 평가하는 것
- semi-supervised 분류기들을 훈련시키기 위해 GAN 샘플들을 사용하고, 분류 태스크의 정확도를 메트릭으로서 사용
- 3) 실제 데이터와 생성된 데이터 간의 통계 차이(거리 기반)를 측정하는 방법을 기반
- Frhechet Inception Distance (FID). moment matching methods은 어떤 통계를 수집할 것인가 중요, 통계들 사이에 거리를 측정하는 방법을 지정
- FID는 두 정규 분포의 차이를 측정한 것, 작은 값이 좋고 Inception Score의 단점을 극복하기 위해서 사용하게 되었음
- FID는 Inception-v3 네트워크의 마지막 계층 특징의 평균 및 공분산을 사용하고 공분산에 의해 정의된 가우스 분포 간의 프레쉐 거리를 측정
- moment matching methods에 대한 주요 단점은 마지막 계층을 사용하기 때문에 순간 선택에 의존한다는 것
- Inception는 이미지 임베딩을 통해서 좋은 방법을 제공하지만 큰 라벨 데이터 세트 및 수년간의 집중적인 연구로부터 이익을 얻지 못한 다른 유형의 데이터에 대해 유사한 기능 공간(임베딩)을 사용할 수 있을지는 명확하지 않음
- Frhechet Inception Distance (FID). moment matching methods은 어떤 통계를 수집할 것인가 중요, 통계들 사이에 거리를 측정하는 방법을 지정
- 1) 사람에 의한 평가
- 토너먼트 평가 방식은 가짜 게임을 제작하고 탐지하는 잠재력을 측정하는 원리에 기초하여 Skill rating을 도입
- Elo와 TrueSkill과 같은 시스템은 게임 플레이 시스템(OpenAI)의 평가에는 기존에 적용되었지만 생성 모델에서는 첫 번째 응용 프로그램임
- 토너먼트 평가 방식의 장단점
- 장점
- 밀도 함수를 제공하지 않는 분류 모델에 대해 계산적으로 다루기 쉽고 정의되기 때문에 우도를 보완할 수 있음
- 데이터를 다시 포맷해도 점수를 조정할 필요가 없기 때문에 다양한 입력 또는 출력 형식 (이미지 픽셀의 연속 표시와 이산 표시 등)을 사용하는 모델을 비교할 수 있음
- 접근법은 인간 평가보다 재현 가능하며 샘플 다양성과 같은 단일 속성을 측정하기 위한 임시 방편보다 데이터의 더 많은 측면을 포착
- 모멘트 매칭 접근법보다 더 적합합니다. 실험자가 고정된 피쳐 세트를 지정하지 않아도 되기 때문, 토너먼트의 플레이어는 유용한 모든 기능을 배울 수 있음
- 단점
- 접근 방식에 대한 단점은 생성모델 능력의 절대 스코어가 아닌 상대적 스코어를 제공한다는 것
- 많은 모델 유형의 토너먼트가 다른 메트릭보다 소프트웨어 복잡성이 더 크다는 것, 점수를 재현하려면 토너먼트에 사용된 모델의 인구를 재현해야 한다는 것
- 장점
- GAN 판별 모델이 훈련된 것 이외의 생성 모델 샘플을 성공적으로 판단할 수 있다는 증거를 제시
- 실제로 효과가 있다는 경험적 주장, 시기와 이유를 이론적으로 설명하지는 않음
3. Methods
3.1 Tournament win rate
- 토너먼트는 generators G set / discriminators D set는 하나의 generator와 하나의 discriminator 사이에 일대일(1vs1) 매치 시리즈로 구성되어 있음
- 먼저 두 세트의 곱 집합(데카르트)의 모든 쌍이 경기에 참여하는 라운드 로빈 토너먼트(일명 리그전) 방식을 가지고 설명
- (G1, D1) (G2, D1) (G3, D1), …
- 판별 모델 D와 생성 모델 G의 일치 결과를 결정하기 위해
- 판별 모델 D는 생성 모델 G의 샘플 하나의 batch 샘플과 실제 데이터 하나의 batch 샘플의 두 배치를 판단
- discriminator에 의해 정확하게 판단되지 않은 모든 샘플 x는 생성 모델의 승리로 계산되며 승률을 계산하는 데 사용됨
- e.g. D(x) ≥ 0.5 for the generated data or D(x) ≤ 0.5 for the real data
- 판별 모델이 생성 모델에서 생성한 값을 real(실제 값)로 판별하는 경우가 승리
- G에 대한 0.5의 승률은 G에 대한 D의 성능이 random chance (반반)보다 낫지 않다는 것을 의미함
-
생성 모델 G의 토너먼트 승률은 D의 모든 discriminators에 대한 평균 승률로 계산됨. Tournament 승률은 그들이 제작한 토너먼트 상황에서만 해석 할 수 있고 다른 토너먼트와 비교할 수 없음
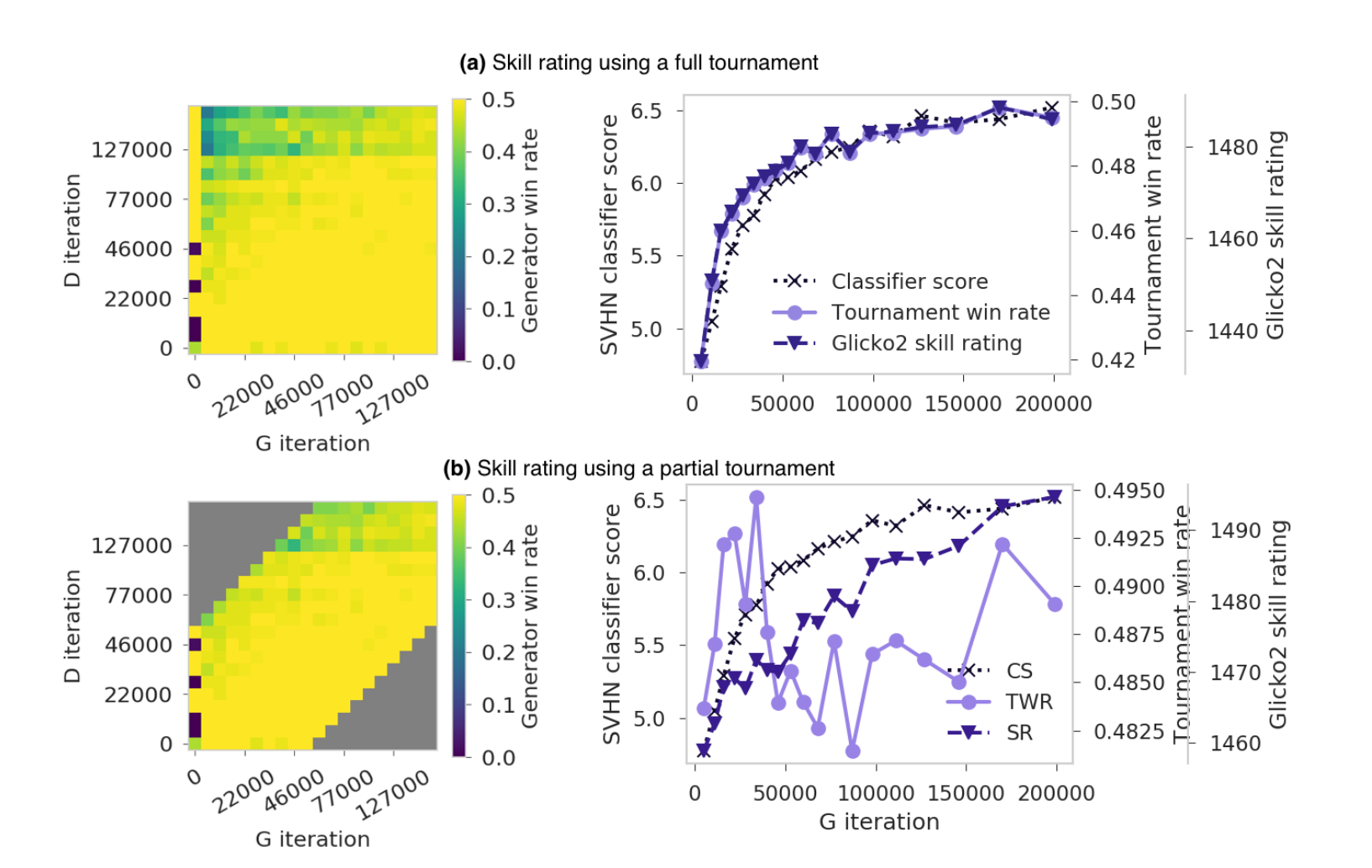
- 그림 1 : Within-trajectory tournament outcomes for experiment
- 그림의 위쪽 절반 : 그림 1a는 raw 토너먼트 결과를 보여줍니다.
- 각 픽셀은 실험 1의 다른 반복에서 하나의 생성 모델과 하나의 판별 모델 사이의 평균 승률을 나타냅니다. 밝은 픽셀 값은 생성 모델 성능을 강화
- 그림 1a-right는 토너먼트 요약 측정과 SVHN 분류 기준 점수를 비교합니다. 토너먼트 승률은 히트맵의 픽셀 값의 열 단위 평균
- 그림의 아래쪽 절반 : 그림 1b는 동일한 데이터를 보여 주지만 그림 1b의 왼쪽에 회색 픽셀로 표시된 멀리 떨어져 있는 반복에서의 matchup을 사용합니다.
- 그림 1b - 오른쪽은 skill 평가가 모델의 개선을 추적하고 있음을 보여줍니다. 초기 생성 모델과 나중에 판별 모델 사이, 왼쪽 상단의 경우, 토너먼트 승률은 유의미하지 않음
- 그림의 위쪽 절반 : 그림 1a는 raw 토너먼트 결과를 보여줍니다.
3.2 Skill rating
- 토너먼트 승률은 계산하기 쉽고 여러 목적에 적합 할 수 있음. 그러나, 승률의 1 차적인 결점은 각 매치가 동등한 가중치의 문제가 있음
- 일부 매치 항목에 중복 정보가 포함되어 있거나 약한 버전의 생성 모델 버전 vs 강력한 판별 모델 버전이 만나는 균형 잡히지 않는 컬렉션일 경우 바람직하지 않을 수 있음
- Skill rating 아이디어를 소개, 스킬 레이팅 시스템은 각 경기가 제공하는 새로운 정보의 양을 고려하여 토너먼트 성과를 요약합니다.
- 스킬 레이팅 시스템은 게임 대결 승패 기록이 주어지면 플레이어 vs 플레이어 게임이 끝나면 플레이어에게 skill rating 값을 할당하는 방법. 등급이 높을수록 플레이어 기술이 향상됨
- Skill rating은 일반적으로 대칭형 게임에 적용되지만 비대칭 게임 (generator vs discriminators)에서도 적용 할 수 있음
- 승률과 같은 skill rating 지표는 특정 토너먼트의 맥락에서만 비교할 수 있습니다.
- 사용하고 있는 스킬레이팅 시스템은 Glicko2 모델
- Glicko 2 모델에 대해서 간단히 요약하면 : 각 플레이어의 스킬 등급은 가우시안 분포로 표현되며, 평균 및 표준 편차는 skill rating에 대한 증거의 현재 상태를 나타냅니다.
- 기계학습 모델에서는 고정된 스냅샷을 사용하기 때문에 Glicko2의 관련성이 없는 Feature을 사용하지 못하게 했음.
- 예) 사용하지 않는 Feature : Glicko2는 한동안 매치에 참가하지 않은 사람의 skill rating에 대한 불확실성을 증가시킴
- 생성 모델과 판별 모델 모두 게임에서는 “선수”이므로 생성 모델의 skill rating만 보고하지만 discriminator에도 전체 계산에 사용되는 skill이 할당
- 즉 “더 강력한” 판별 모델을 얻는 것은 evidence of higher generator skill
- 3.1 절에서 설명한 바와 같이 실제 데이터를 평가에 포함시키면 판별 모델이 “가짜”를 무차별적으로 출력하여 최대한의 skill을 할당할 수 없도록 보장
4. Results
4.1 Within-trajectory tournaments to monitor GAN training
- 평가 방법의 일반적인 사용 사례는 알고리즘이 성공적으로 진행되고 있는지 확인하는 것
- 단일 학습의 trajectory 스냅샷에서 토너먼트 결과를 사용하여 생성 모델을 평가하는데 생성 모델을 다른 실험에서 나온 판별 모델에게 접근하지 않아도 실험 초기에 사용할 수 있음
- SVGN [Netzer et al., 2011]에서 훈련된 DCGAN [Radford et al., 2015]의 동일한 훈련 실행에서 판별 모델와 생성 모델의 20 개의 저장된 체크 포인트 사이에서 토너먼트를 진행
- 평가하는데 일괄 배치 사이즈는 64
- 그림 1 (a)는 토너먼트 승률과 스킬 레이팅을 사용하여 요약된 것과 동일한 토너먼트 결과와 함께 Within-trajectory 토너먼트에서 나온 raw 토너먼트 결과를 보여줍니다
- 승률, skill raintg과,SVHN 분류기 점수, SVHN Fréchet distance
- 대회 승률과 스킬 등급 모두 SVHN 등급 분류 점수와 비슷한 수준의 교육 진행률을 제공합니다.
- 스킬 레이팅에 따라 매치 횟수를 줄일 수 있음. 생성 모델와 판별 모델 사이의 모든 쌍에 대해 매치업을 실행하면 검사수가 커짐에 따라 모델 비용이 엄창나게 비쌈
- 스킬 레이팅 등급은 적은 수의 매치를 허용합니다. 체스의 세계적인 순위는 세계의 모든 체스 플레이어가 서로 경쟁 할 것을 요구하지 않음
- 스킬 레이팅이 전투를 생략하여 효율성을 높일 수 있다는 개념 증명 데모를 제공
- 그림 1 (b)는 멀리 떨어진 반복(생성, 판별 모델 둘중 하나에서 반복수가 매우 큰 경우)에서 체크포인트 사이의 매치 결과를 생략
- 토너먼트 승률은 해당 경기 세트에서 제대로 수행되지 않지만 스킬 등급은 상대방 풀의 불균형에도 불구하고 생성 모델을 평가하는 데 어려움이 없음
- 매칭 누락이 skill rating 정확도를 상쇄하는 방법에 대한 탐구는 미래의 작업에 대한 열린 질문
- 논문에서 이 실험은 skill rating 계산을 위해 20-60 개의 discriminators를 사용하기 때문에 하나의 discriminator를 생략해도 결과에 큰 영향을 미치지 않는 반면 작은 토너먼트에서는 단일 discriminator의 포함 또는 누락이 큰 영향을 미칠 수 있음
- 토너먼트 승률은 해당 경기 세트에서 제대로 수행되지 않지만 스킬 등급은 상대방 풀의 불균형에도 불구하고 생성 모델을 평가하는 데 어려움이 없음
- 토너먼트 기반 평가는 비경쟁 영역에서 성공했음 (standard image embeddings 도메인에서)
- 이전 연구에서는 Inception Score와 Fréchet Inception Distance와 같은 방법이 이미지의 생성 모델 평가에 널리 채택되어 있음
- 주된 단점은 다른 종류의 데이터에서는 쉽게 사용할 수 없는 좋은 feature space에 의존한다는 것
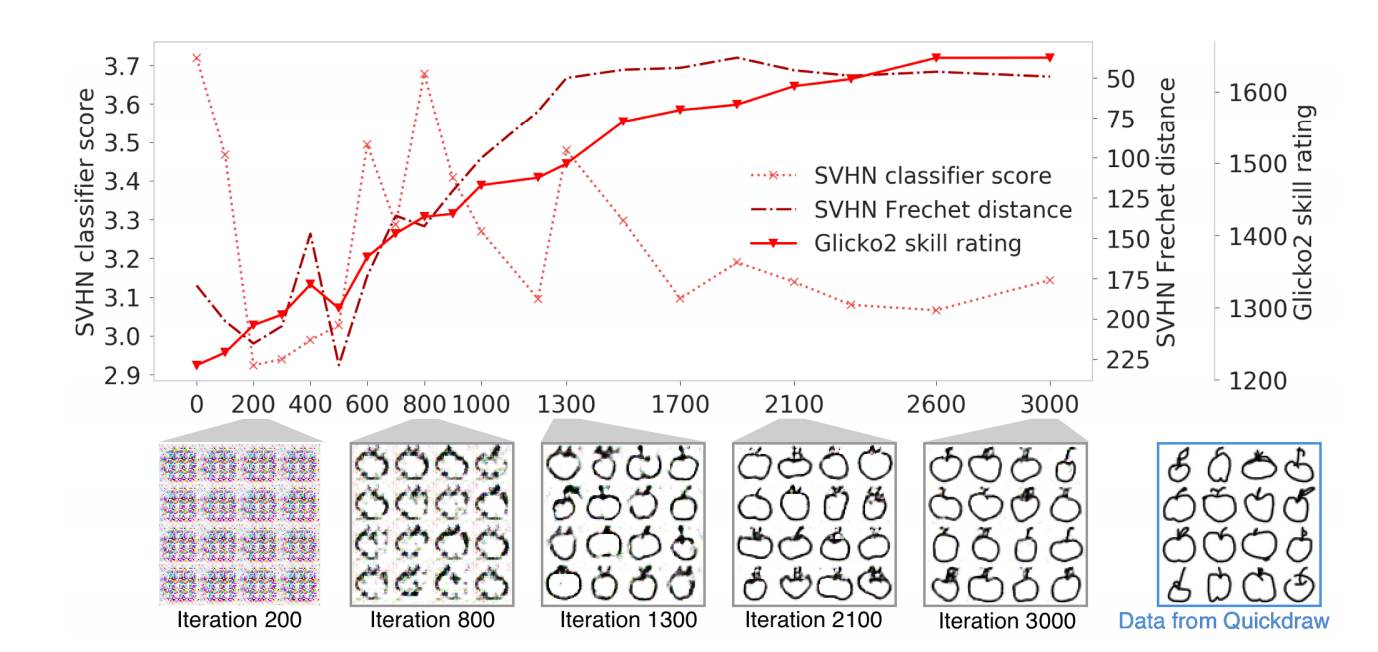
- standard feature space을 사용할 수 없는 비경쟁 영역의 개념 증명으로 Google에서 훈련된 GAN을 평가 ( QuickDraw 데이터 세트에서 70,000 개의 손으로 그린 사과 이미지를 이용 )
- 드로잉은 이미지로 나타내지만 “자연스러운” 이미지 (즉, 실제 세계의 사진)는 아님
- SVHN의 이미지 임베딩 공간을 사용하여 평가하는 방법(분류기 성능)과 within-trajectory 내 skill rating 지표를 비교
- 그림 2는 주관적으로 샘플 품질이 반복적으로 증가함을 보여줌
- SVHN Classifier 점수는 샘플의 품질에 대한 좋지 않은 판단
- Fréchet 거리가 더 적합하지만 샘플 품질이 향상되는 반면 반복 1300에서 포화됨
- 세 가지 방법 중 스킬 레이팅이 가장 적합하므로 스킬 레이팅이 미지의 영역에서 성공할 수 있다는 예비 증거를 제공함
- 그림 2 : 사과의 그림에 적용되는 within-trajectory 내 skill rating으로 DCGAN 모델을 평가
- QuickDraw 데이터 세트의 사과 도면에 대한 훈련을 받음. 왼쪽에서 오른쪽으로, 주관적인 샘플 품질은 더 많은 반복으로 향상
- SVHN Classifier 점수는 반복 횟수 0이 가장 높은 점수를 주기 때문에, 샘플에 대한 품질은 보면 좋지 않음, 이후에는 고르지만 전반적으로 악화되는 등급을 제공
- SVHN Fréchet 거리가 더 적합. 1300 반복 때까지 꾸준히 증가하는 샘플 품질을 평가해보면. 주관적인 샘플 품질이 계속 증가하는 반면,이 시점에서 포화 상태에 놓임
4.2 Tournaments to compare GANs
- 큰 토너먼트를 사용하여 다르게 훈련 된 GAN을 비교 평가하는 결과를 제시
- 환경 설정을 바꿔가면서 실험, 서로 다른 손실 함수 및 아키텍처를 포함하여 서로 약간 다른 6 개의 GAN 모델에서 저장된 스냅샷으로 토너먼트를 구성
- 알고리즘의 세부 사항은 부록 D.1에 제시되어 있음
- 실험 1은 판별 모델에서 batchnorm 대신 pixelnorm을 사용, Gulrajani [2017]의 아키텍처, 손실 함수 및 하이퍼 매개 변수를 사용하는 일반적인 DCGAN, 훈련 시간에 판별 모델의 입력에 노이즈를 추가
- 실험 2는 다른 손실 함수 사용
- 실험 3은 동일한 아키텍처이지만 다른 손실 기능을 사용
- 실험 4-cond 및 5-cond는 클래스 조건부 아키텍처를 사용
- 아키텍처의 판별 모델은 임의의 생성된 샘플에는 사용할 수 없는 보조 정보로 라벨 값을 요구하므로 생성 모델만 토너먼트에서 참가할 수 있음
- 실험 6-auto는 GAN이 아니라 autoregressive model 이며 생성 모델로만 참여했음
- 각 GAN 실험에서 판별 모델 및 생성 모델의 20 개의 저장된 체크 포인트를 사용, 실험 6-auto에서는 단일 스냅샷, 실제 데이터의 배치를 가지고 벤치마크 사용 (생성하는 생성 모델의 플레이어가 포함됨)
- 4-cond, 5-cond 및 6-auto의 discriminators가 토너먼트에 참가할 수 없음
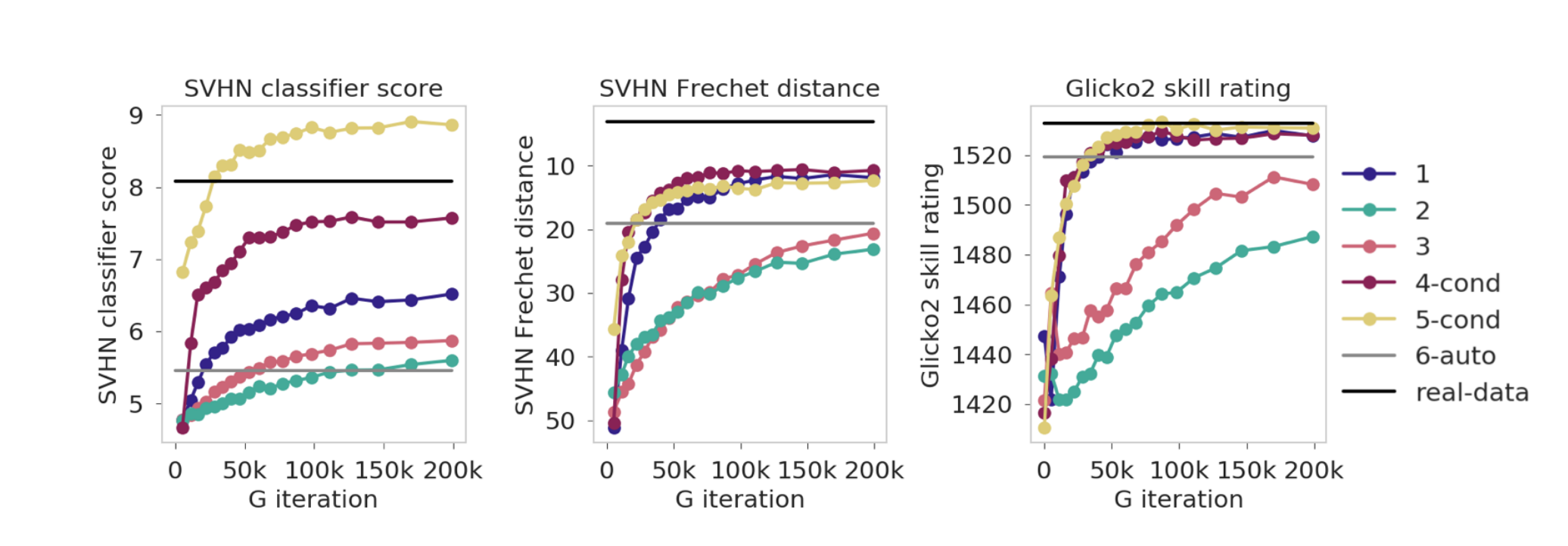
- 모든 플레이어의 토너먼트에서 스킬 레이팅, 분류기 점수 및 Fréchet 거리 궤적을 보여줌. 승률 히트 맵 (그림 1a- 왼쪽과 유사)은 부록 A에 나와 있음
- 스킬 레이팅에서는 5cond를 최고 품질 모델로 평가하지만 실제 데이터만큼 높은 품질은 아닙니다. 분류기 점수는 실제 데이터보다 5-cond가 높습니다.
- 스킬 레이팅 방법의 순위가 샘플 품질에 대한 주관적인 시각적 평가와 가장 일치한다고 믿음
- 6-auto의 순위를 고려했을 때 해당 샘플은 GAN에 의해 생성 된 것이 아니며 GAN 샘플과 다른 강점과 약점이 있음
- GAN discriminators가 완전히 다른 발생원에 의해 생성된 표본을 정확하게 평가할 수 있는지 여부에 관심을 가졌음
- 샘플의 순위에서 Fréchet 거리와 일치하는 반면, 분류기 점수는 2와 3 아래에서 순위가 매겨집니다.
- 6-auto 모델이 더 흐린 샘플을 생성하는 경향이 있는 반면 2 와 3은 흔들리기(줏대없는) 쉬운 샘플을 생성 할 가능성이 높음
- 마지막으로 우리의 방법은 실제 데이터를 최상위 모델과 매우 비슷하게 순위를 매겼음
- 우리의 현재의 추측은 여기에 있는 판별 모델이 전체 실험에서 판별한 것보다 전반적으로 덜 분별적이므로 가장 잘 생성된 샘플에 더 속는 것
4.3 Toy problem: evaluating near-perfect generators
- 복잡한 실제 데이터 세트의 경우 생성 모델은 현재 목표한 데이터 분포를 완벽하게 학습하는 데 성공하지 못함
- 그러나 더 간단한 데이터 세트의 경우 생성 모델이 거의 완벽한 성능을 달성 할 수 있음
- 이 경우에는 해당 지점 이후의 판별 모델의 출력은 효과적으로 제약을 받지 않음
- 그러나 더 간단한 데이터 세트의 경우 생성 모델이 거의 완벽한 성능을 달성 할 수 있음
- 이러한 설정에서도 토너먼트 기반 평가가 적용될 수 있는지 확인하기 위해 생성 모델이 쉽게 해결할 수있는 장난감 작업을 실험
- 전체 공분산 행렬로 가우스 분포를 모델링함. 이 경우 생성 모델이 작업을 마스터하면 반복 이후의 판별 모델이 더 이상 유용한 판단을 내리지 못하는 것으로 나타남

- 그림 4 : 완전히 훈련 된 생성 모델의 샘플. 각 훈련된 모델에서 비교를 위한 실제 데이터와 함께 64 샘플을 보여줌
- 각 샘플 세트에서 모델의 Glicko2 스킬 등급 (SR), SVHN 분류기 점수 (CS) 및 SVHN Fréchet 거리 (FD)를 나열
- 기술 등급 시스템은 실험 5-cond를 실제 데이터보다 약간 나쁘고 2 와 4-cond 및 1보다 약간 더 우수하다고 분류하는 반면, 분류기 점수는 실제 데이터보다 5-cond가 우수하고 Fréchet 거리는 5-cond보다 4-cond와 1 둘 다. 우리 시스템의 순위는 다른 모든 경우에서 Fréchet 거리와 일치
- Chekhov GAN [Grnarova et al., 2017]의 discriminator 대신 discriminator가 아닌 생성 모델를 평가함으로써이 문제를 해결했음
- Chekhov GAN은 상대방의 여러 과거 버전에 대해 각 플레이어를 훈련시킴
- 경험적으로 Chekhov GAN 판별 모델은 생성 모델이 거의 완벽한 성능을 달성한 후에도 과거 생성 모델의 표본을 판단할 수있는 능력을 보유하고 있음을 발견했음
- Chekhov GAN discriminator와 일치하는 결과로 얻은 스킬 레이팅 등급은 궤도 내 일치 (그림 5c)의 것보다 생성 모델의 ground truth에 더 적합했음
- 특정 이례적 현상이 관찰되면 문제를 해결하기 위해 고안된 discriminators를 신중하게 선택하여 해결할 수 있음
5. FUTURE WORK
- 게임을 하나의 샘플로 실행하므로 낮은 다양성으로 생성 모델은 고통받음 ( 배치 수준에서 실행되는 게임이 포함 된 토너먼트로 이 문제를 해결할 수 있음 )
- 판별 모델이 생성된 샘플을 D (x) ≥ 0.5로 실제 값으로 평가하는 경우 생성 모델의 “승리”를 세는 이진 임계값을 사용하지만 판별 모델의 출력을 사용하는 다른 방법으로 실험 할 수 있음
- 필연적으로 과거의 데이터가 반드시 “가짜”로 분류 될 수 있는 특별한 제약은 없음.
- 미래의 작업은 “실제 공간에서 실제 데이터와의 거리”를 사용하도록 설정 한 후, 토너먼트 기반 평가를 위해 모멘트 매칭 판별자를 사용하여 조사 할 수 있음
- 평가 시 실제 데이터 분포에 비대칭적으로 권한을 부여하면 판별 모델이 낯선 샘플을 더 효과적으로 거부하는 데 도움이 됨
- 부록 B에서 우리는 왜곡 된 실제 표본에 대한 숙련도의 성능에 대한 탐색적 분석을 보여줍니다. 거리기반 판별 모델이 여기에 사용 된 판별 모델보다 점진적으로 큰 왜곡 수준에 대해 단조롭게 낮은 등급을 부여 할 것으로 예상 할 수 있음
- 토너먼트에서 모든 n 명의 선수를 기술할 수 있지만 아직 생략 할 수 있는 경기(모든 경기를 다할 필요는 없으니깐)를 결정하는 방법을 완전히 조사하지는 않았음
- 마지막으로, 인간의 판사가 discriminators로 플레이 할 자격이 있으며, 스킬 레이팅을 얻기 위해 참가할 수 있음
- 인간의 지각적인 평가가 인간 평가자 사이의 판단의 변이를 고려함으로써 보다 미묘한 방식으로 생성 모델의 평가에 통합 될 수 있게 하는 것
-
GAN 판별 모델이 훈련된 것과 다른 생성 모델의 표본을 성공적으로 판단 할 수 있다는 경험적 증거를 제시하지만 이 행동이 언제 예상 될 수 있는지에 대한 완전한 탐구는 아직 열려 있음
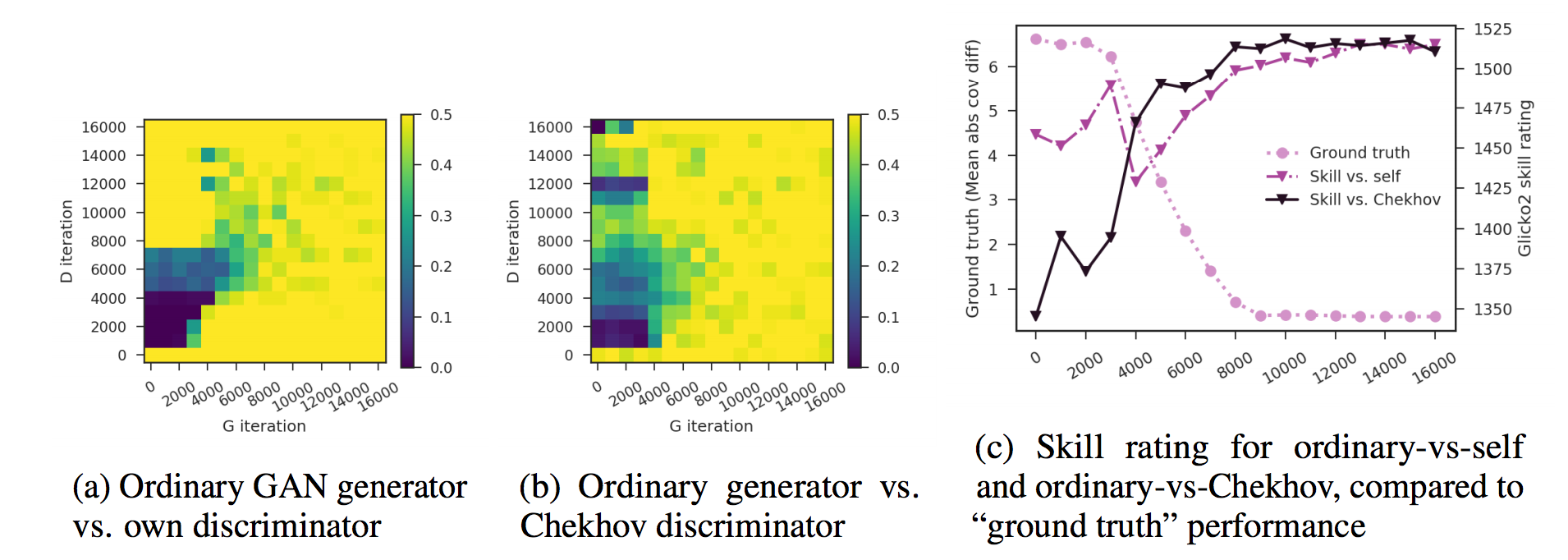
- 그림은 Evaluating a near-perfect generator on a toy problem. 정규 GAN을 훈련시켜 완전한 공분산 행렬로 가우시안 분포를 모델링합니다. 반복 8000 이후의 생성 모델은 이 작업을 마스터. 반복 8000 이후의 discriminators 더 이상 유용한 판단을 생산하지 않음
Chekhov GAN discriminators는 과거 생성자의 샘플을 판단 할 수있는 능력을 유지</span>
- 그림 5c는 판별 모델의 스킬 레이팅과 일반 생성 모델의 Ground Truth 성능을 비교하며, 생성 모델의 추정 공분산 행렬과 데이터의 평균 절대 차이로 측정
- Chekhov discriminator에 대한 스킬 레이팅 평점은 궤적 매치에서 얻은 것보다 Ground Truth에 더 적합




댓글남기기