
DeepAR: Probabilistic Forecasting with Autoregressive Recurrent Networks - Review (KR)
Abstract ——–
- 과거에 따른 미래의 확률분포를 추정하는것은 비즈니스 프로세스를 최적화하는 핵심 요소
- DeepAR은 많은 수의 RNN모델을 훈련하는 확률적 예측 방법론
1. Introduction
- 오늘날 널리 사용되는 예측 방법은 대부분의 비즈니스에서 운영 프로세스를 자동화하고 최적화하는데 중요한 역할 및 데이터 기반 의사결정 역할을 한다. 예를들어 재고관리 , 스케줄링 , 공급 및 수요 최적화 등등
- 각 시계열에 대한 모델 매개변수는 과거 관측치로부터 독립적으로 추정. 현재 통용되는 모델은 일반적으로 추세, 계절성 및 기타 설명 변수와 같은 요소에 의해 수동으로 선택된다.
- 대부분의 방법들은 ‘Box-Jenkins methodology’ , ‘exponential smoothing techniques(지수평활법)’ 또는 ‘state space models’에 기반한다.
- 최근에는 새로운 유형의 예측 문제가 등장. 개인 또는 소수가 아니라 수천 수백만 개의 관련된 시계열을 예측한다.
- 예를들어 개별 가정의 에너지소비 예측 , 데이터센터의 서버 부하예측 또는 대형 소매 업체가 제공하는 모든 제품에 대한 수요 예측한다.
- 해당 논문에서는 이러한 새로운 유형의 문제를 해결하기위해 LSTM 기반의 RNN모델인 “DeepAR”을 제시한다.
- 실제 예측문제에서 여러 시계열에서 공동으로 학습하려고 시도할 때 자주 접하는 문제점은 시계열의 구간이 다르다는 것과 값의 크기가 편향되어 있다는 것이다.

- 이러한 편향된 분포로 인해 일반적으로 입력표준화 및 배치 정규화를 사용한다.
- 해당 모델의 장점 두가지는 (1) 이항 확률뿐만 아니라 특별한 경우인 데이터의 크기가 아주 큰 경우에도 사용 가능하다. (2) 여러 도메인의 데이터에 대해서 정확한 예측결과를 산출한다.
- 기존의 방법보다 예측 정확도를 높일 수 있을뿐만 아니라 , 해당 접근 방법은 고전적 및 기타 방법에 비해 다수 주요 이점 존재한다.
- 모델이 계절성 및 시계열의 따른 공변량에 대한 의존성을 포착하기 위해서 최소한의 피처엔지니어링이 필요하다.
- “DeepAR”은 “Monte Carlo(다중확률 시뮬레이션)“의 샘플 형태의 확률적 예측을 산출한다.
- 또한 보유한 데이터의 구간이 짧거나, 전통적인 단일 항목 예측 방법이 실패한 경우에도 예측가능하다.
- “DeepAR”은 “Gaussian noise”을 가정하지 않지만, 다양한 우도 함수를 혼합 할 수 있습니다.
- 이러한 확률적 예측은 많은 응용에서 결정적으로 중요하며 리스크를 최소화함으로써 불확실성 하에서 최적의 의사 결정을 가지게함.
2. Related Work
- 예측의 실용적인 중요성으로인해 다양한 예측 방법이 개발되었습니다. 개별 시계열 예측 방법의 대표적인 “ARIMA” 및 “exponential smoothing methods”
- 특히 수요 예측 영역에서 가우시안 오류와 같이 매우 불규칙하거나 간헐적인 경우가 많아 더 적절한 통합된 “likelihood function”(zero-inflated Poisson distribution,the negative binomial distribution) 을 사용했습니다.
- 시계열을 통해 정보를 공유하면 예측 정확도는 향상 될 수 잇지만 데이터의 성질이 서로 다르기 때문에 실제로 기대하기는 어렵다.
- 베이지안 또는 매트릭스 분해를 통해 여러 관련 시간에 걸쳐 학습하기위한 메커니즘도 제안되었다.
- 최근 “Kourentzes”는 간헐적 데이터에 신경망을 적용했지만 원하는 결과를 얻지 못했습니다.
- 인공신경망 모델은 자연어처리,이미지,음성변환와 같은 다른 응용프로그램에는 매우 성공적으로 적용되었습니다.

3. Model
- 각 시계열에 대해 개별 모델을 피팅하는 대신 Amazon에서 제안한 것은 재조정 및 속도 기반 샘플링을 통해 광범위하게 변화하는 스케일을 처리 할 수있는 관련 글로벌모델 을 만드는 것 입니다.
- 생성된 모델의 목표는 주어진 시간에서 다음을 예측하는 것이다. 네트워크가 이전 관측치 zt-1을 공변량 xi와 함께 입력받아야 합니다.
-
Figure2 에서 볼 수 있듯이, 훈련 중 (왼쪽의 네트워크) 오류는 우도 세타 의 현재 매개 변수를 사용하여 계산됩니다.이것은 역전파를 수행하는 동안 네트워크 매개 변수 (가중치 w)를 조정하여 모든 매개변수를 변경한다는 것을 의미합니다.
- 시간 t에서 시계열 i의 값을 zi, t로 나타내면, 각 시계열의 미래의 조건부 분포를 모델링하는 것이 목표입니다.
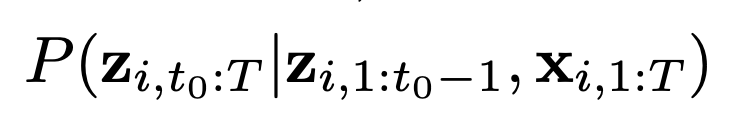
- zi,1:t0:i의 시점 1부터 t까지의 target값 , xi,1:T :i의 시점 1부터 T까지의 공변량
- 혼동을 피하기 위해 [1, t0-1],[t0 ,T]으로 과거와 미래를 각각 구분하고 ‘conditioning range’, ‘prediction range’으로 말한다.
- 모델을 학습하는 기간에는, zi,t가 관찰되도록 두 범위가 과거에 있어야합니다.
- 하지만 예측하는 기간에는, zi,t가 오직 ‘conditioning range’에서만 사용할 수 있다.
- “DeepAR”모델의 요약은 Figure2에서 확인할 수 있으며 RNN구조를 기반으로 하고있다.
- “DeepAR”모델의 분포는 QΘ(zi,t0:T|zi,1:t0−1, xi,1:T)로 나타낼 수 있으며 최대우도의 곱으로 구성된다.

- hi,t=h(hi,t−1, zi,t−1, xi,t,Θ)은 RNN의 출력값이다.

- 여기서 h는 LSTM의 cell에서 구현된 함수입니다.LSTM설명블로그
- 최대우도 l(zi,t|θ(hi,t))은 RNN의 출력값 hi,t의 출력값에 대한 함수 θ(hi,t,Θ)에 의해 고정된 분포를 가진다.
- “conditioning range”의 zi, 1:t0-1은 초기값 hi, t0-1에 의해 “prediction range”로 이동된다.
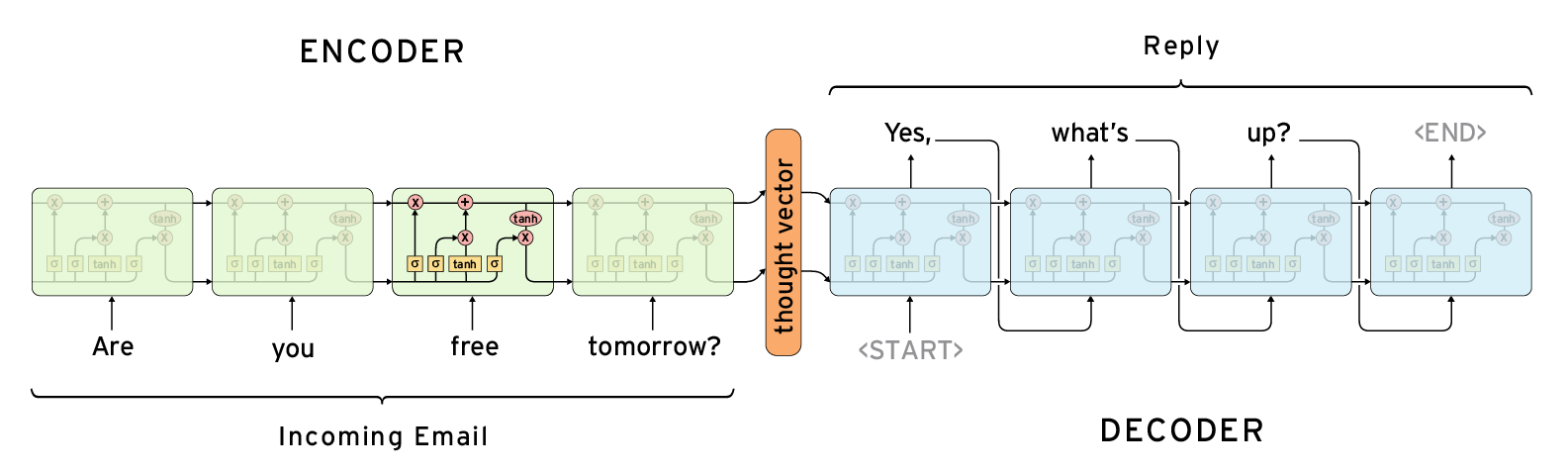
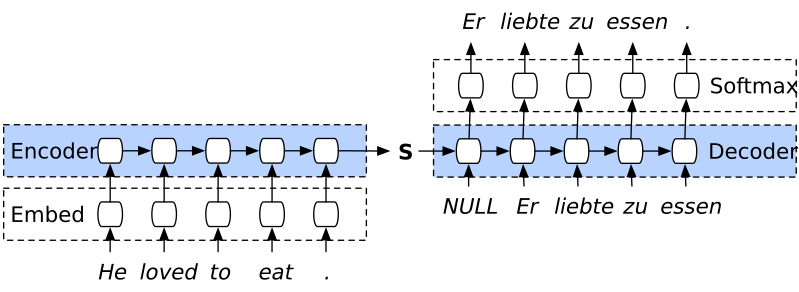
- seq2seq의 초기 상태는 인코더 네트워크의 출력입니다. 일반적으로이 인코더 네트워크는 ‘conditioning range’ 와 ‘prediction range’에 다른 아키텍처를 가질 수 있지만 동일한 아키텍처를 사용합니다.
-
또한 이들 사이의 가중치를 공유한다, 그래서 t=1 부터 t0-1시점의 계산에 의해 디코더 hi,t0-1에 대한 초기값을 구할 수 있다. 모든 필요한 양이 관찰될때. 초기 상태 인코더 hi,0 및 zi,0은 0으로 초기화된다.
-
모델의 파라미터 Θ를 얻으면, 우리는 직접적으로 표본을 얻을 수 있다. z˜i,t0:T ∼ QΘ(zi,t0:T |zi,1:t0−1, xi,1:T)
- 첫번째로 t=1부터 t0동안의 계산을 통해 hi,t01을 구한다.
- 이후 t=t0에서 T까지의 샘플 z˜i,t∼ l(·|θ(h˜ i,t, Θ)) 초기값으로 h˜i,t0-1 = hi,t0-1 , z˜i,t0-1 = zi,t0-1 -모델에서 얻어진 샘플은 미래의 어떤 시간의 값에 합계에대한 분포를 계산하는데 사용된다.
3.1 Likelhood model
- target value가 real-valued인 경우 Gaussian likelihood를, Count data인 경우 negative-binomial likelihood를 사용한다.
- 평균 및 표준편차를 사용하여 가우시안 확률을 매게 변수화하고 θ = (μ, σ), 여기서 평균은 네트워크 출력의 아핀 함수에 의해 주어진다. 평균은 ‘affine function‘에 의해 구해지며 표준편차는 ‘affine function’변환 후 softplus activation function을 적용해서 구한다.
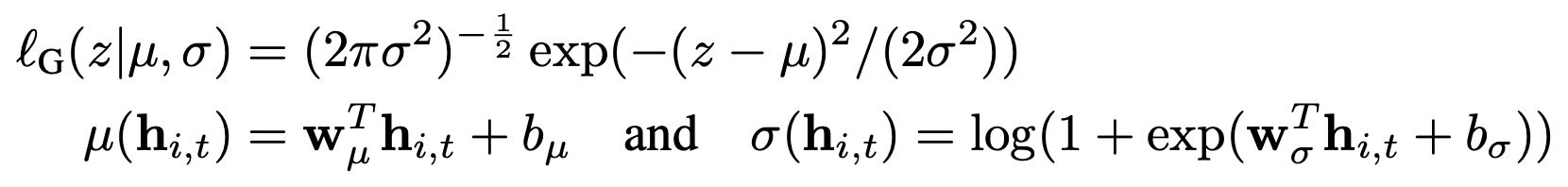
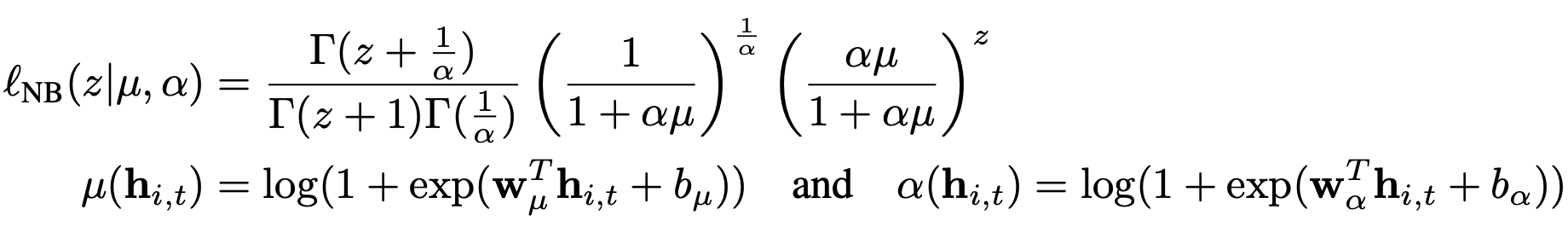
3.2 Training
- ‘prediction range’에서 zi,t가 알려진 범위를 선택하고 시계열 데이터 {zi:1:T}i=1,…,N 와 공변량 xi,1:T이 주어졌을때, RNN의 h(·)로 구성된 파라미터 Θ 뿐만 아니라 θ(.)파라미터 또한 로그우도의 최대화로 얻을 수 있다.

- hi,t은 입력에의한 결정론적 함수이며 위의 최대우도를 계산하기 위해 모든 데이터값이 요구된다.
- 최대우도는 Θ와 관련하여 ‘stochastic gradient descent’을 통해 직접 최적화 될 수 있습니다.
- 인코더 모델이 디코더 모델과 동일한 경우 Training 기간동안 인코더 , 디코더를 구분하는 것은 다소 부자연스럽다. 그래서 최대우도의 조건을 시간과 무관하게 동일한 조건을 주어준다.
- 데이터 집합의 각 시계열에 대해 원래 시계열로부터 다른 시작점의 시간구간을 선택하여 여러 개의 교육 인스턴스를 생성합니다.
- 전체길이 T 뿐만아니라 모든 훈련 예에 대해 고정 된 조절 및 예측 범위의 상대적 길이도 유지합니다.
- 예를 들어, 주어진 시계열의 총 사용 가능 범위가 2013-01-01에서 2017-01-01까지 인 경우 2013-01-01, 2013-01-02, 2013-01-03등 t = 1의 해당하는 교육 사례를 만들 수 있습니다.
- 이 창을 선택할 때 우리는 전체 예측 범위가 항상 보장되도록합니다.
- 그러나 우리는 시계열 데이터 시작 전 값인 t=1이 2012-12-01인 경우를 선택할 수 있다, 이러한 관측되지 않은 target값은 0으로 채운다. 이것은 새로운 시계열의 행동에 대해 학습할 수 있도록 도와준다.
- Bengio et al는 그러한 모델의 자동 회귀 특성으로 인해 최적화가 직접 모델을 훈련 중에 사용하는 방법과 예측을 얻을 때 모순을 야기한다고 지적했습니다.
- 학습을 하는동안 zi,t은 예측범위에 알려져있다, 그리고 hi,t을 계산할 수 있다.
-
하지만 zi,t은 t ≥ t0인 t에 대해서는 알려져 있지 않다, 그리고 z˜i,t∼ l(· θ(hi,t)) 대신 모델의분포 hi,t의 계산에 사용됩니다.
3.3 Scale handling
- Figure1 에서 묘사 된 것과 같이 지수적으로 나타내는 데이터에 모델을 적용하면 두 가지 문제가 발생합니다.
- 첫째, 모델의 자기 회귀 특성으로 인해 네트워크의 출력뿐만 아니라 자기 회귀 입력 zi, t-1은 관측치 zi, t로 직접 스케일링되지만 그 사이의 네트워크의 비선형 성은 제한된 작동 범위를 갖는다
- 더 이상 수정하지 않으면 네트워크는 입력을 입력 레이어의 적절한 범위로 스케일링 한 다음 출력에서이 스케일링을 반전시켜야합니다.
3.4 Features
- 공변량 xi,t은 시간, 아이템 또는 두가지 모두 종속될 수 있다.
- 공변량은 아이템 또는 시간에대해 추가적인 정보를 제공합니다.
- 모든 실험에서 우리는 “age”특성, 즉 그 시계열에서 첫 번째 관찰까지의 거리를 사용합니다.
- 또한 시간별 데이터, 일주일 단위의 요일과 시간대를 추가합니다.월별 데이터의 주별 데이터 및 월별 데이터입니다.
- 또한 하나의 범주형 변수를 포함하는데 이러한 변수는 모델에 의해 학습됩니다.
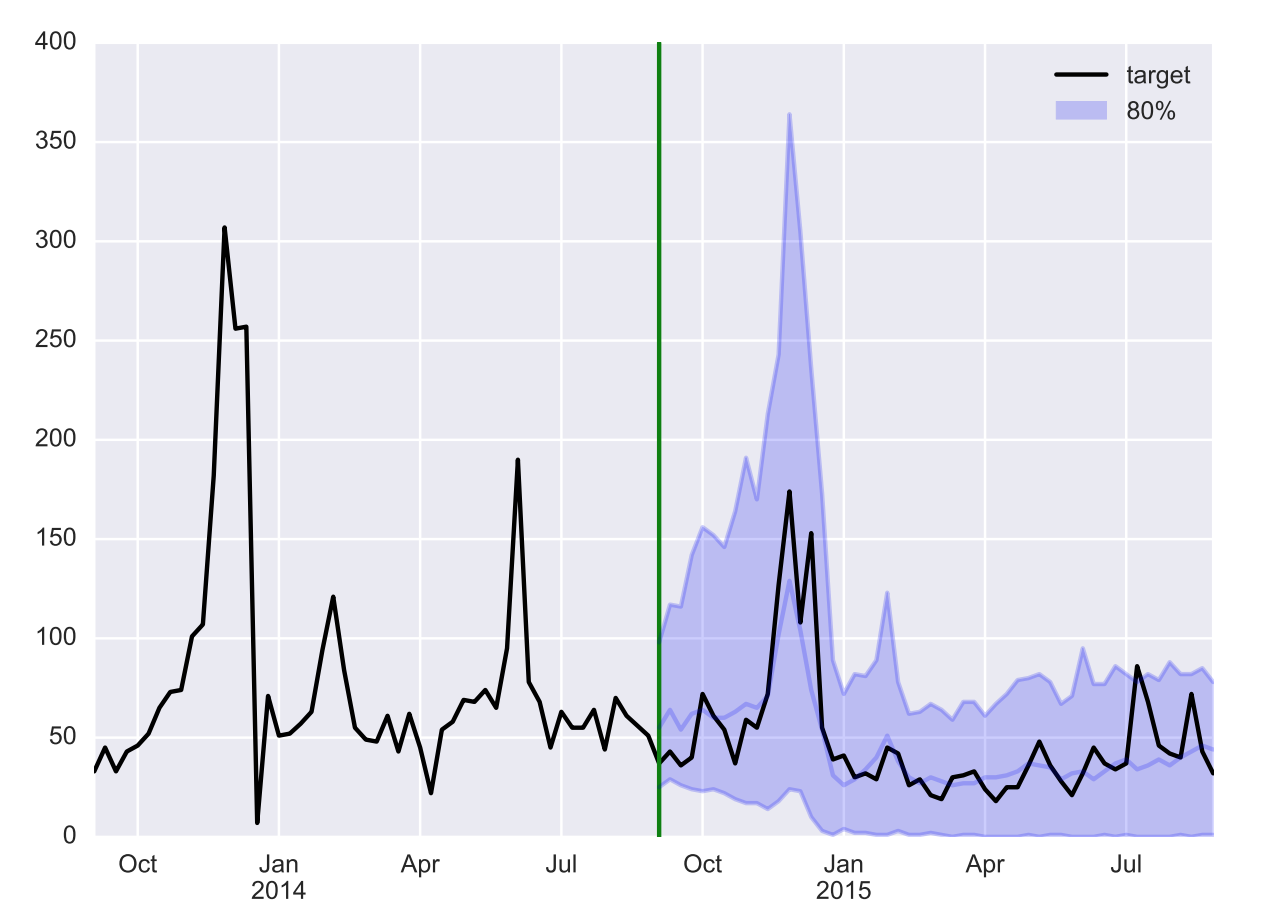
- 소비전력의 시계열 예제 : 초록색 수직선은 condition range를 나누는 기준선이다.
- 검은색선은 실제 target value , 음영부분은 80%의 신뢰구간을 나타냅니다.
4. Applications and Experiments
- MxNet 딥러닝 프레임워크를 사용하며 4개의 CPU를 포함하는 단일 p2.xlarge AWS인스턴스를 사용합니다.
Datasets
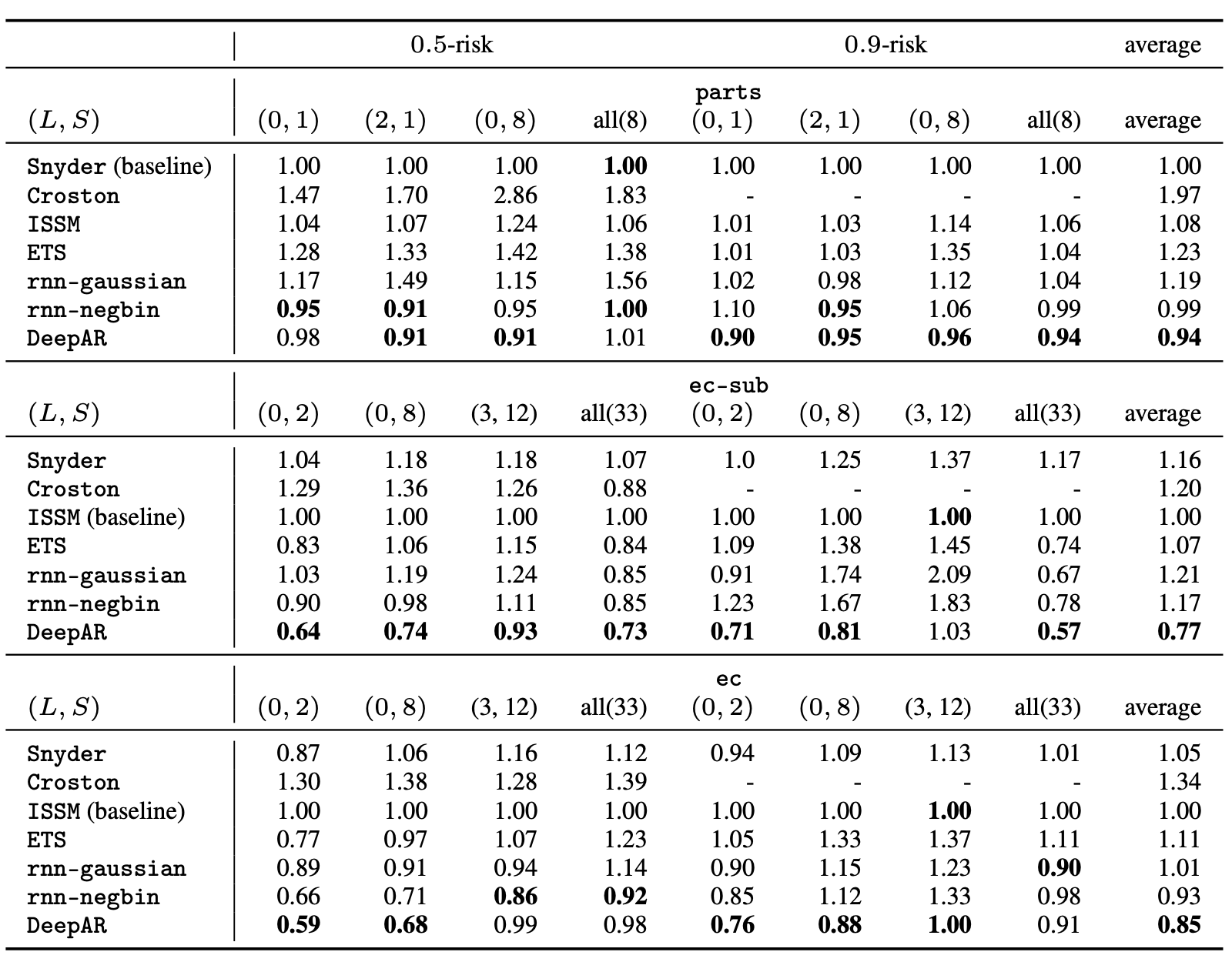
- 평가를 위해 사용한 데이터셋은 전기사용량,교통량 한 사기업의 판매액 등의 공개된 시계열 데이터 셋입니다.

- 시간간 경과에 따른 불확실성 증가가 ISSM모델과 다르게 비선형적이다.ISSM(Innovation State Space Model)
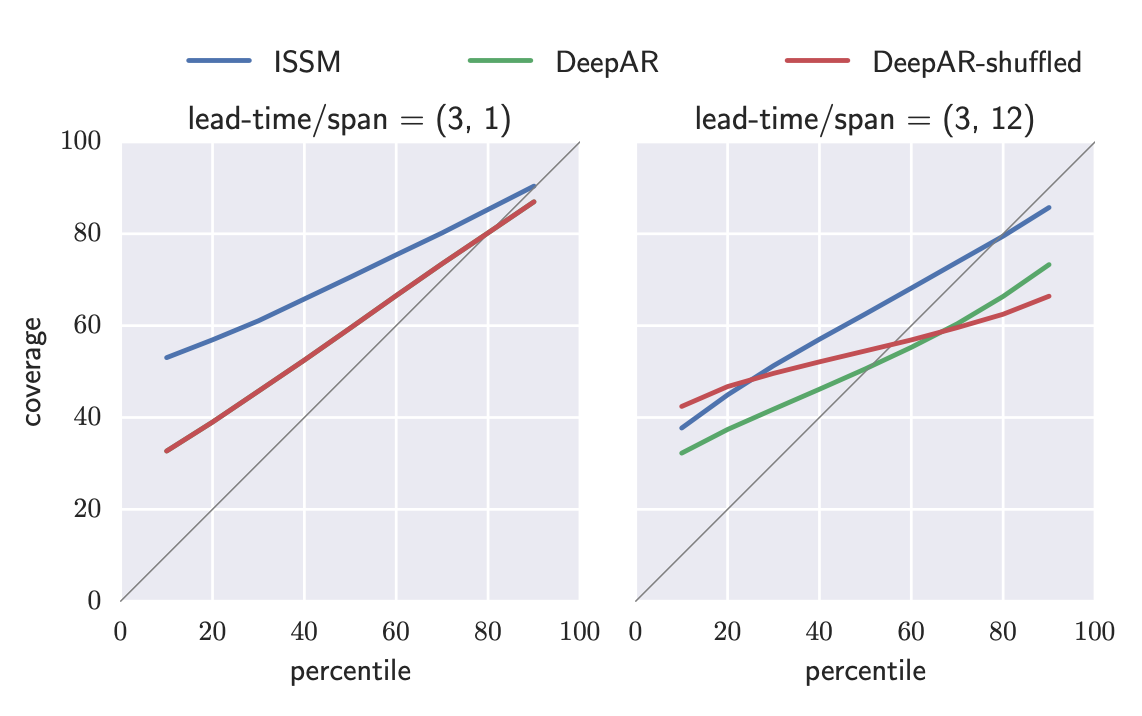
- 왼쪽은 단일시간간격 , 오른쪽은 더 긴 시간에 간격에 대한 평가를 보여줍니다.
5. Conclusion
- 우리는 현대의 딥러닝에 기반한 예측 접근법이 다양한 데이터셋에 대한 예측 정확도를 대폭 향상시킬 수 있음을 보여주었습니다.
- “DeepAR”모델은 관련된 시계열로부터 글로벌 모델을 효과적으로 학습하고, 재사용 및 샘플링을 통해 광범위하게 변화하는 스케일을 처리하고, 보정된 신호를 생성합니다.
- 계절성과같은 복잡한 패턴을 학습할 수 있어 정확한 확률적 예측이 가능합니다.
- 다양한 데이터세트에 대해 하이퍼 파라미터튜닝을 거의 사용하지않고 모델사용이 가능합니다.
- 그리고 몇백개의 시계열을 포함하는 중간 크기의 데이터 세트에 적용할 수 있습니다.




댓글남기기