
들어가며
- 페이퍼 다운로드 링크: arxiv 링크
Abstract
- 자연 언어 representation을 미리 학습할 때 모델 크기를 늘리면 세부 NLP task에서 성능이 향상되는 경우가 많음
- 그러나 어느 시점에서 GPU/TPU 메모리 한계, 더 긴 학습시간 및 예상치 못한 모델 성능 저하로 인해 계속 모델 사이즈를 늘려가기는 쉽지 않음
- 이러한 문제를 해결하기 위해, 저자들은 메모리 소비를 줄이고 BERT의 학습 속도를 증가시키기 위해 두 가지 파라미터 감소 기법을 제시(Devlin et al., 2019)
- 종합적이고 경험적 여러 증거들은 우리가 제안한 방법이 원래의 BERT에 비해 훨씬 더 나은 모델로 이어진다는 것을 보여줌
- 또한 문장간 일관성을 모델링하는 데 초점을 맞춘 self-supervised loss를 사용하며, 복수개의 문장들을 입력으로 받는 세부 task에서 지속적으로 도움이 된다는 것을 보임
- 그 결과, 저자들의 최고의 모델은 BERT-large에 비해 파라미터가 적은 GLUE, RACE 및 SQuAD 벤치마크에 대한 새로운 최고 성능 결과를 만들었음
1. Introduction
- 전체 네트워크 pre-training(Radford et al., 2018; Devlin et al., 2019)은 언어 representation 학습에서 일련의 돌파구를 마련
- 제한적인 학습 데이터를 사용하는 task를 포함하여 많은 중요한 NLP task들은 이러한 pre-training된 모델로부터 큰 수혜를 받았음
- 이러한 방식이 유의미하다는 징후 중 하나는 중국의 중고등학교 영어 시험을 위해 설계된 읽기 이해 과제인 RACE 테스트(Laiet al., 2017)에 대한 기계 성능의 진화
- 원래 과제를 기술했던 당시 페이퍼에는 최고 성능이 44.1%
- 최신 발표된 결과는 모델 성능 83.2%(Liu et al., 2019)
- 저자들이 여기서 제시한 결과는 89.4%로 훨씬 더 높아졌으며, 이는 주로 고성능 pre-training된 언어 표현을 구축하는 현재의 능력에 기인하는 놀라운 45.3% 성능의 향상
- 이러한 개선의 증거는 첨단 성능을 달성하기 위해 큰 네트워크의 중요성을 보여줌(Devlin et al., 2019; Radford et al., 2019)
- 대형 모델을 pre-training하고 실제 응용을 위해 더 작은 모델로 변환하는 것이 일반적(Sun et al., 2019; Turc et al.,2019)
- 모델 크기의 중요성을 감안할 때, 저자들은 다음과 같이 질문해야 함
- 더 큰 모델을 제작하는 것만큼 더 나은(좋은) NLP 모델을 만드는 것이 쉬운가?
- 이 질문에 대답하는 데 장애가 되는 것은 가용 하드웨어의 메모리 한계
- 현재의 최신 모델들은 종종 수억 또는 수십억 개의 매개변수를 가지고 있기 때문에, 우리가 모델을 확장하려고 할 때 이러한 한계에 도달하기가 쉬움
- 통신 오버헤드가 모델의 매개변수 수에 직접 비례하기 때문에 학습 속도는 분산 학습에서도 크게 타격을 입을 수 있음
- 또한 BERT-large (Devlin et al., 2019)와 같은 모델의 hidden size를 단순히 증가시키면 성능이 더 나빠질 수 있다는 것을 관찰
- Table 1과 Figure 1은 BERT-large의 hidden size를 2배 더 크게 늘렸을 때 이 BERT-xlarge 모델로 더 나쁜 결과를 얻는 전형적인 예를 보여줌
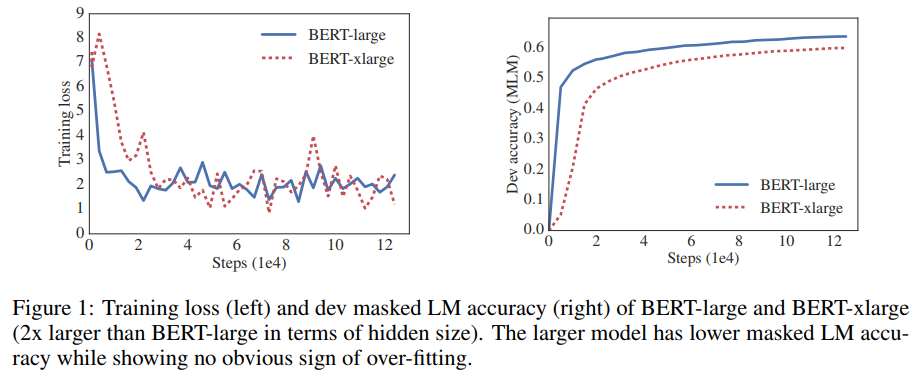
그림1. BERT-large와 BERT-xlarge(BERT-large보다 hidden size가 2배 더 크다) 모델의 train loss(왼쪽)과 dev masked LM accuracy(오른쪽). 더 큰 모델은 masked LM accuracy가 낮지만 과적합의 명백한 징후는 보이지 않음

표1. BERT-large의 hidden size가 증가하면 RACE에서 더 나쁜 성능을 얻을 수 있음
- 앞서 언급한 문제점들에 대한 기존 해결책은 모델 병렬화(Shoeybi et al.,2019)와 영리한(clever) 메모리 관리(Chen et al., 2016; Gomez et al., 2017) 등이 있었음
- 이러한 솔루션은 메모리 제한 문제를 해결하지만 통신 오버헤드 및 모델 열화 문제는 해결하지 않음
-
본 논문에서는 기존의 BERT 아키텍처보다 파라미터가 상당히 적은 A Lite BERT(ALBERT) 아키텍처를 설계하여, 앞서 언급한 모든 문제점을 해결하고자 함
- ALBERT는 pre-training된 모델을 스케일링할 때의 주요 문제점을 해결하는 두 가지 매개 변수 감소 기술을 통합함
- 요인화된 임베딩 파라미터화(factorized embedding parameterization)
- 큰 어휘 임베딩 행렬을 두 개의 작은 행렬로 분해함으로써, hidden layer의 크기를 어휘 임베딩의 크기와 분리
- 이 분리는 어휘 임베딩의 매개 변수 크기를 크게 증가시키지 않고 hidden size를 더 쉽게 늘릴 수 있음
- 교차 계층 파라미터 공유(cross-layer parameter sharing)
- 이 기술은 네트워크가 깊어짐에 따라 파라미터 사이즈도 함께 커지는 것을 방지
- 두 기법 모두 성능을 심각하게 손상시키지 않고 BERT에 대한 매개 변수 수를 크게 줄여 매개 변수 효율성을 향상시킴
- 요인화된 임베딩 파라미터화(factorized embedding parameterization)
- BERT-large와 유사한 ALBERT configuration은 매개 변수가 18배 적고 약 1.7배 더 빨리 학습시킬 수 있음
-
매개 변수 감소 기술은 또한 학습을 안정화시키고 일반화를 돕는 정규화의 한 형태로 작용
- 또한, ALBERT의 성능을 향상시키기 위해, 저자들은 문장-순서 예측(SOP; sentence-order prediction)을 위한 self-supervised loss 도입
-
SOP는 우선적으로 문장 간 일관성에 초점을 맞추고, 원래의 BERT에서 제안된 다음 문장 예측(NSP; next sentence prediction) loss의 비효율성(Yang et al., 2019; Liu et al., 2019)을 다루기 위해 고안되었음
- 구조를 이렇게 결정함에 따라, 저자들은 BERT-large보다 더 적은 파라미터를 가지고 있지만 훨씬 더 나은 성능을 달성하는 매우 큰 ALBERT config를 확장할 수 있음
- 저자들은 자연 언어 이해를 위한 잘 알려진 GLUE, SQuAD 및 RACE 벤치 마크에 대한 최신 결과를 수립
- 구체적으로, 저자들은 RACE 정확도를 89.4%로, GLUE를 89.4로, SQuAD 2.0의 F1 점수는 92.2로 높였음
2. Related work
2.1. SCALING UP REPRESENTATION LEARNING FOR NATURAL LANGUAGE
- 자연 언어의 representation을 학습하는 것은 다양한 NLP task에 유용한 것으로 밝혀졌으며 널리 채택되었음 (Mikolov et al., 2013; Le & Mikolov, 2014; Peters et al., 2018; Devlin et al., 2019; Radford et al., 2018; 2019)
- 지난 2년 동안 가장 중요한 변화 중 하나는 pre-training된 단어 임베딩에서 full-network pre-training과 fine-tuning으로의 전환(Radford et al., 2018; Devlin et al., 2019)
- 문맥과 무관한 단어 임베딩(Mikolov et al., 2013; Pennington et al., 2014)
- 문맥을 반영한 단어 임베딩(McCann et al., 2017; Peters et al., 2018)
- 이러한 task에서 모델 크기가 클수록 성능이 향상되는 경우가 많음
- 예를 들어, Devlin et al.(2019)는 3가지 자연어 이해 과제를 통해 더 큰 hidden size, 더 많은 hidden layer, 더 많은 attention head를 사용하는 것이 항상 더 나은 성능을 이끌어낸다는 것을 증명
- 그러나 그들은 hidden size 1024에서 실험을 멈추었음
- 저자들은 같은 설정 하에서 hidden size를 2048로 증가 시키면 모델의 성능 악화(degradation)가 발생하고 결국 성능이 저하된다는 것을 보여줌
-
따라서 자연어에 대한 representation 학습을 확장하는 것은 단순히 모델 크기를 증가시키는 것만큼 쉽지 않음
- 또한, 특히 GPU/TPU 메모리 제한 측면에서 계산 제약으로 인해 대형 모델을 실험하기가 어려움
- 현재의 최신 모델들은 수억 또는 수십억 개의 파라미터를 가지고 있기 때문에, 메모리 한계점에 다다르기가 쉬움
- 이 문제를 해결하기 위해
- Chen et al.(2016)은 추가 순방향 패스의 비용으로 메모리 요구 사항을 부분선형으로 줄이기 위해 gradient checkpoint라고 불리는 방법을 제안
- Gomez et al. (2017)은 각 층의 activation을 다음 층으로부터 재구성하여 중간 activation을 저장할 필요가 없도록 하는 방법을 제안
- 두 가지 방법 모두 속도를 포기하고 메모리 소비를 줄임
- 대조적으로, 본 연구에서의 파라미터 감소 기술은 메모리 소비를 줄이고 학습 속도를 증가시킴
2.2. CROSS-LAYER PARAMETER SHARING
- 계층 간 매개 변수 공유 아이디어는 이전에 Transformer 아키텍처(Vaswani et al., 2017)와 함께 탐구되었지만, 그 당시의 연구는 pre-training/fine-tuning 세팅보다는 표준 인코더-디코더 task 학습에 중점을 두었음
- 저자들의 관찰과는 달리, Dehghani et al. (2018)은 표준형의 Transformer보다 교차 계층 파라미터 공유(Universal Transformer, UT)를 가진 네트워크가 언어 모델링 및 주어-서술어 일치도 측면에서 더 나은 성능을 보인다는 것을 보여줌
- 매우 최근에, Bai et al. (2019)는 transformer 네트워크를 위한 Deep Equilibrium Model(DQE)을 제안하고, DQE가 특정 층의 입력 임베딩과 출력 임베딩이 동일하게 유지되는 평형점에 도달할 수 있음을 보여주었음
- 저자들의 관찰에 따르면 저자들의 임베딩은 수렴하기보다는 값이 왔다갔다 함(oscillating)
- Hao et al. (2019)은 파라미터-공유 트랜스포머를 표준 트랜스포머와 결합시켜, 표준 트랜스포머의 파라미터의 수를 더욱 증가시켰음
2.3. SENTENCE ORDERING OBJECTIVES
- ALBERT는 텍스트의 두 연속 세그먼트의 순서를 예측하는 데 기반한 pre-training loss를 사용
- 몇몇 연구자들은 담화 일관성과 유사한 pre-training 목적함수를 실험해 왔음
- 담화에서의 일관성과 응집성은 널리 연구되어 왔으며, 이웃한 텍스트 세그먼트를 연결하는 많은 현상이 확인됨(Hobbs, 1979; Halliday & Hasan, 1976; Grossz et al., 1995)
- 실제로 효과적인 목적함수들은 대부분 단순함
- Skip-thought(Kiros et al., 2015)과 FastSent(Hill et al., 2016) 문장 임베딩은 이웃 문장의 단어를 예측하기 위해 문장의 인코딩을 사용하여 학습
- 문장 임베딩 학습의 다른 목적함수는 이웃들만이 아닌 미래의(다음에 올) 문장을 예측하는 것(Gan et al., 2017)과 명시적 담화 표지(discourse markers)를 예측하는 것(Jernite et al., 2017; Nie et al., 2019)을 포함
- 저자들의 loss는 두 개의 연속 문장의 순서를 결정하기 위해 문장 임베딩을 학습한 Jernite et al.(2017년)의 문장 순서 목적함수와 가장 유사
- 그러나 위의 대부분의 task와 달리, 본 연구의 loss는 문장보다는 텍스트 단위 세그먼트를 기준으로 함
- BERT(Devlin et al.,2019)는 한 쌍의 텍스트가 있을 때, 두 번째 세그먼트가 다른 문서의 세그먼트와 바뀌었는지 여부를 예측하는 것에 기초한 loss를 사용
- 저자들은 실험에서 이 loss과 비교한 결과, 문장 순서 맞추기가 더 어려운 pre-training 과제이며 특정한 세부 task에 더 유용하다는 것을 발견
- 이와 동시에 Wang et al. (2019) 또한 두 개의 연속된 텍스트의 순서를 예측하려고 시도하지만, 두 개의 텍스트를 경험적으로 비교하기보다는 3-way 분류 task에서 원래의 다음 문장 예측과 결합하는 형태를 취함
3. THE ELEMENTS OF ALBERT
- 이 절에서는 ALBERT를 설계하는 데 작용한 결정들을 제시하고, 원래의 BERT 아키텍처의(Devlin et al., 2019) 구성과 정량화된 비교를 제공함
3.1. MODEL ARCHITECTURE CHOICES
- ALBERT 아키텍처의 근간은 GELU 비선형성을(Hendrycks & Gimpel, 2016) 가진 Transformer 인코더(Vaswani et al., 2017)를 사용한다는 점에서 BERT와 유사
- 저자들은 BERT 표기법 규칙을 따라 어휘 임베딩 크기를 로, 인코더 레이어 수를 로, hidden size는 로 표시함
-
Devlin et al.(2019)를 따라 feed-forward/filter size를 로 설정하고 attention head 수를 로 설정
- ALBERT가 BERT의 구조에서 개선된 데에는 세 가지 주요 공헌이 있음
Factorized embedding parameterization.
- XLNet(Yang et al., 2019), RoBERTa(Liu et al., 2019)과 같은 후속 모델들을 포함하여 BERT에서는 WordPiece 임베딩 사이즈 는 hidden layer 크기 에 묶이도록 되어 있음
- 즉
- 이러한 결정은 다음과 같이 모델링 자체와 실질적인 이유 모두에 대해 최적으로 나타남
- 모델링 관점에서 WordPiece 임베딩은 컨텍스트 독립적인 representation을 배우기 위한 것이고, 히든 레이어 임베딩은 컨텍스트 의존적인 representation을 배우기 위한 것
- 컨텍스트 길이 실험(Liu et al., 2019)에서 알 수 있듯이, BERT 스타일 represenatation의 힘은 컨텍스트를 사용하여 그러한 컨텍스트 의존 representation을 배우기 위한 신호를 제공하는 데서 나옴
- 이와 같이, hidden layer 크기에서 WordPiece 임베딩 크기 를 풀어 를 지시하는 모델링 필요에 의해 알려지는 전체 모델 파라미터를 보다 효율적으로 사용할 수 있음
- 실제적인(practical) 관점에서 NLP는 대개 매우 큰 어휘(vocab) 사이즈 를 요구 1
- 인 경우, 가 증가하면 인 임베딩 행렬의 크기도 증가하게 됨
- 이는 수십억 개의 매개 변수를 갖는 모델을 초래하는 문제를 일으키는데, 심지어 대부분은 학습 중에 아주 가끔 업데이트됨
- 따라서 ALBERT의 경우 임베딩 매개 변수의 인수 분해를 사용하여 더 작은 두 행렬을 분해
- 크기의 hidden space에 직접 1-hot 벡터를 투영하는 대신, 먼저 크기 의 낮은 차원 임베딩 공간에 투영한 다음 hidden space로 투영
- 이 분해를 이용하여 임베딩 파라미터를 에서 로 감소
- 이 파라미터 감소는 에서 유의했음
Cross-layer parameter sharing
- 파라미터 효율을 향상시키기 위한 또 다른 방법으로 교차층 파라미터 공유를 제안
- 기존 방식(여러가지 방식이 있었음)
- 계층 간에 피드 포워드 네트워크(FFN) 매개변수만 공유
- attention 파라미터만 공유하는 등 일부 매개변수만 공유
-
ALBERT에서 기본적인 결정 사항은 계층 간에 모든 매개변수를 공유하는 것. 저자들은 이 설계 결정을 섹션 4.5에서 다른 전략들과 비교함
- Transformer 네트워크에 대해서는 Dehghani et al.(2018) (Universal Transformer, UT)와 Bai et al. (2019) (Deep Equilibrium Models, DQE)에 의해 유사한 전략들이 탐구되었음
- 저자들의 관측과 달리 Dehghani et al. (2018)는 UT가 순정(vanilla) 트랜스포머보다 우월함을 보여줌
- Bai et al. (2019)은 그들의 DQE가 특정 층의 입력과 출력 임베딩이 동일하게 유지되는 평형점에 도달한다는 것을 보임
- L2 거리와 코사인 유사성 측정 결과, 저자들의 임베딩이 수렴하기보다는 왔다갔다함을 보여줌
- 아래 Figure2는 BERT-large 및 ALBERT-large config를 사용하여 각 레이어에 대한 입력 및 출력 임베딩의 L2 거리와 코사인 유사성을 보여줌(Table2 참조)
- 저자들은 층에서 층으로의 전이가 BERT보다 ALBERT에서 훨씬 더 부드럽다는(smoother) 것을 관찰할 수 있었음
- 이러한 결과는 가중치 공유가 네트워크 파라미터를 안정화시키는데 영향을 미친다는 것을 보여줌
- BERT에 비해 두 가지 지표에 대한 성능 저하가 있지만 그럼에도 불구하고 24개 레이어를 지나서도 0으로 수렴하지 않았음
- 이는 ALBERT 매개 변수에 대한 솔루션 space가 DQE에서 발견된 솔루션 space와 매우 다르다는 것을 보여줌

BERT-large와 ALBERT-large를 위한 각 레이어의 입력 및 출력 임베딩의 L2 거리 및 코사인 유사도
Inter-sentence coherence loss
- BERT는 Masked Language Modeling(MLM) loss(Devlin et al., 2019) 외에도 다음 문장 예측(NSP)이라는 추가 loss를 사용
- NSP는 다음과 같이 두 세그먼트가 원본 텍스트에 연속적으로 나타나는지 여부를 예측하기 위한 2진 분류 loss
- positive example: 학습 코퍼스에서 연속적인 세그먼트를 취함으로써 생성
- negative example: 다른 문서에서 세그먼트를 페어링하여 생성
- positive, negative example은 동등한 확률로 샘플링됨
- NSP는 다음과 같이 두 세그먼트가 원본 텍스트에 연속적으로 나타나는지 여부를 예측하기 위한 2진 분류 loss
- NSP 목표는 문장 쌍 간의 관계에 대한 추론을 필요로하는 자연 언어 추론과 같은 세부 task에서 성능을 향상시키기 위해 고안되었음
- 그러나 후속 연구들은(Yang et al., 2019; Liu et al.,2019) NSP의 영향을 신뢰할 수 없다는 것을 발견하고 여러 task에 걸친 세부 task 성능의 향상에 뒷받침되는 요소인 NSP를 제거하기로 결정
- NSP의 비효율성 이면의 주된 이유는 MLM에 비해 과제로서의 어려움이 부족하기 때문이라고 추측
- 공식화된 NSP는 주제 예측과 일관성 예측을 하나의 task2로 통합
-
그러나 주제 예측은 일관성 예측에 비해 학습하기가 더 쉽고 MLM loss를 사용하여 배운 결과에 더 영향을 많이 받음
- 저자들은 문장 간 모델링이 언어 이해의 중요한 측면이지만 주로 __일관성(coherent)__에 기초한 loss를 제안하기로 함
- 즉, ALBERT의 경우, 저자들은 문장 순서 예측(SOP) loss를 사용하며, 이는 주제 예측을 피하고 대신 문장간 일관성을 모델링하는 데 초점을 맞춤
- SOP loss는 BERT(동일 문서에서 두 개의 연속 세그먼트)와 동일한 기술, 그리고 negative sample로서 동일한 두 개의 연속 세그먼트를 사용하지만 순서는 바뀜
- 이로 인해 모델이 담화 수준 일관성 특성에 대해 더 세밀한 구별을 배우게 됨
- 섹션 4.6에서 나타나듯이, NSP는 SOP task를 전혀 해결할 수 없는 것으로 판명
- 더 쉬운 주제 예측 신호를 배우고 SOP task에 대해 랜덤 베이스라인 레벨에서 수행됨
- SOP는 잘못된 일관성 큐를 분석함으로써 NSP task를 합리적인 수준으로 해결할 수 있었음
- 그 결과, ALBERT 모델은 복수의 문장 인코딩 task에 대한 세부 task 성능을 지속적으로 개선
3.2. MODEL SETUP
- 아래 Table2에서는 BERT와 ALBERT 모델에서 상호 비교 가능한 하이퍼 파라미터 설정의 차이점을 제시
- 위에서 논의한 설계 선택(design choice)으로 인해 ALBERT 모델은 BERT 모델에 비해 훨씬 작은 매개 변수 크기를 가짐
- 예를 들어 ALBERT-large(18M)는 BERT-large(334M)와 비교하여 약 18배 적은 파라미터를 가지고 있음
- BERT를 로 확장할 수 있도록 설정하면, 결국 12억 7천만 개의 매개변수와 저성능(Fig.1)을 가진 모델이 탄생
- ALBERT-xlarge: 59M
- ALBERT-xxlarge: 233M (여전히 BERT-large 파라미터의 약 70%밖에 되지 않음)
- ALBERTxxlarge의 경우, 24-layer 네트워크(동일한 구성을 가진)가 유사한 결과를 얻었지만 계산적으로 더 비싸기 때문에 주로 12-layer 네트워크에서의 결과를 담았음

Table2. 본 논문에서 분석된 주요 BERT 모델과 ALBERT 모델의 구성
- 이러한 파라미터 효율 향상은 ALBERT의 설계 선택에서 가장 중요한 이점
4. EXPERIMENTAL RESULTS
4.1. EXPERIMENTAL SETUP
- 비교를 더욱 의미있게 만들기 위해 본 연구는 BOOKCORPUS (Zhu et al., 2015)와 English Wikipedia (Devlin et al., 2019)를 이용하여 BERT 베이스라인 모델을 pre-training 했고, Devlin et al., (2019)의 설정을 그대로 이용함
- 이 두 말뭉치는 약 16GB의 비압축 텍스트로 구성
- 저자들은 입력을 로 형태를 맞춰줌3
- 저자들은 항상 최대 입력 길이를 512로 제한하고, 10% 확률로 512보다 짧은 입력 시퀀스를 무작위로 생성
-
BERT와 마찬가지로, 저자들은 XLNet (Yang et al., 2019)에서와 같이 SentencePiece (Kudo & Richardson, 2018)를 사용하여 토큰화한 3만 개의 어휘 크기를 사용
- 저자들은 n-gram masking (Joshi et al., 2019)을 이용하여 MLM target에 대한 masked 입력을 생성하고, 각 n-gram mask의 길이를 임의로 선택
- 길이 n에 대한 확률은 다음과 같이 주어짐
- 저자들은 n-gram(즉, n)의 최대 길이를 3으로 설정
- 즉, MLM 타겟은 “White House correspondents”과 같은 완전한 단어의 최대 3-gram으로 구성
- 모든 모델 업데이트는 학습 속도 0.00176(You et al., 2019)을 가진 4096의 batch size와 LAMB optimizer를 사용
- 달리 명시하지 않는 한 모든 모델을 125,000 step으로 학습
- 클라우드 TPU V3에서 학습
- TPU의 수는 모델 크기에 따라 64에서 1024까지 다양함
- 이 섹션에서 설명한 실험 설정은 달리 명시되지 않는 한 ALBERT 모델뿐만 아니라 페이퍼 내의 모든 BERT 버전에도 사용
4.2 EVALUATION BENCHMARKS
4.2.1. INTRINSIC EVALUATION
- 학습 진행을 모니터링하기 위해 SQuAD와 RACE의 dev set을 기반으로 섹션 4.1.과 동일한 절차를 사용하여 dev set을 제작
- MLM과 문장 분류 task에 대한 정확도 확인용
- 이 데이터셋은 모델이 어떻게 수렴하는지 확인하기 위해서만 사용; 모델 선택을 통해 세부 task 평가의 성능에 영향을 미치는 방식으로 사용되지 않았음
4.2.2. DOWNSTREAM EVALUATION
- Yang et al. (2019)과 Liu et al. (2019), 저자들은 세 가지의 인기있는 벤치마크에 대해 모델을 평가
- General Language Understanding Evaluation(GLUE) (Wang et al., 2018)
- Stanford Question Answering Dataset의 두 가지 버전(SQuAD; Rajpurkar et al., 2016; 2018)
- ReAding Comprehension from Examinations(RACE) (Lai et al., 2017).
- 부록 A.1에 이러한 벤치마크에 대한 설명을 제공함
- Liu et al., (2019)에서와 같이, 저자들은 dev set에 대해 early stopping을 수행
4.3. OVERALL COMPARISON BETWEEN BERT AND ALBERT
- 파라미터 효율의 향상은 ALBERT의 설계 선택의 가장 중요한 이점을 보여줌
- BERT-large의 파라미터의 약 70%만 가지고, ALBERT-xxlarge는 몇 가지 대표적인 세부 task에 대한 dev set 점수의 차이로 측정한 BERT-large보다 상당한 개선을 달성
- SQuAD v1.1 (+1.7%)
- SQuAD v2.0 (+4.2%)
- MNLI(+2.2%)
- SST-2(+3.0%)
- RACE(+8.5%)
- BERT-large의 파라미터의 약 70%만 가지고, ALBERT-xxlarge는 몇 가지 대표적인 세부 task에 대한 dev set 점수의 차이로 측정한 BERT-large보다 상당한 개선을 달성
- 또한 모든 메트릭에서 BERT-xlarge가 BERT-base보다 훨씬 더 나쁜 결과를 얻을 수 있음을 관찰
- 이는 BERT-xlarge와 같은 모델이 더 작은 매개 변수 크기를 가진 모델보다 학습하기가 더 어렵다는 것을 나타냄
- 또 다른 흥미로운 관찰은 동일한 학습 구성(동일한 TPU 수) 하에서의 학습 시간에 데이터 처리 속도
- 통신 및 연산량이 적기 때문에 ALBERT 모델은 해당 BERT 모델에 비해 데이터 처리량이 높음
- 가장 느린 것은 BERT-xlarge 모델인데, 저자들은 이를 베이스라인으로 사용
- 모델이 커지면 BERT와 ALBERT 모델의 차이가 커짐
- 예를 들어 ALBERT-xlarge는 BERT-xlarge보다 2.4x 빨리 학습할 수 있음
4.4. FACTORIZED EMBEDDING PARAMETERIZATION
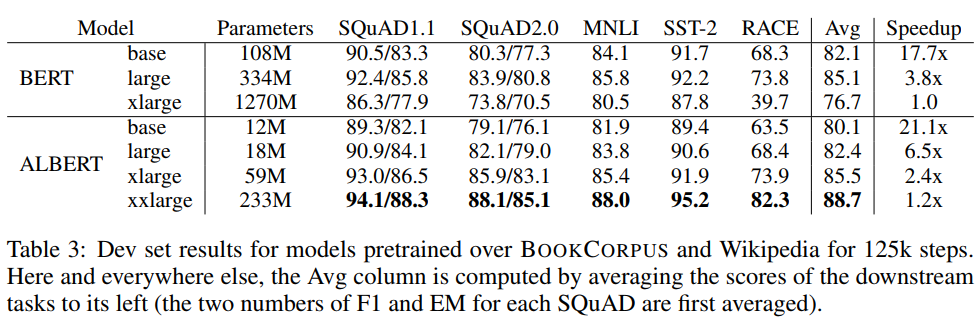
- 표 4는 동일한 대표적인 세부 task 세트를 사용하여 ALBERT 기반 구성 설정을 사용하여 어휘 임베딩 크기 를 변경하는 효과를 보여줌(표 2 참조)
- 비공유 조건(BERT 스타일) 하에서, 더 큰 임베딩 크기는 더 나은 성능을 제공하지만, 전혀 그렇지 않음
- 모든 공유 조건(ALBERT 스타일)에서 128 크기의 임베딩이 가장 좋은 것으로 보임
- 이러한 결과를 바탕으로, 저자들은 향후 모든 설정에서 임베딩 크기 을 추가 스케일링을 위한 필요한 단계로 사용
4.5. CROSS-LAYER PARAMETER SHARING
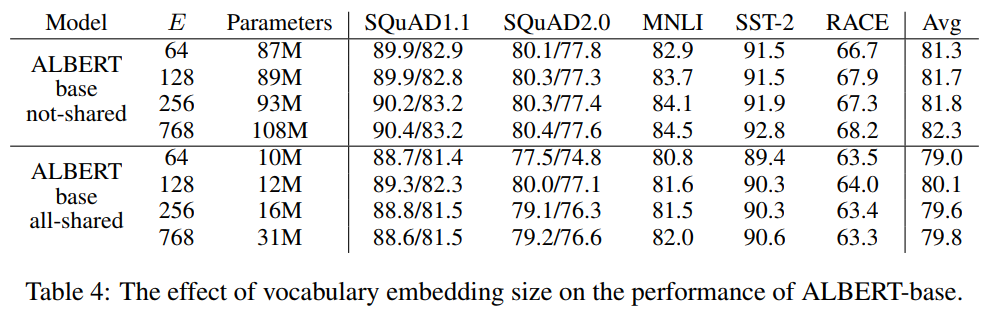
- 표 5는 두 개의 임베딩 크기( 및 )를 갖는 ALBERT-base 구성(표 2)을 사용하여 다양한 교차층 파라미터 공유 전략에 대한 실험을 제시
-
어텐션 파라미터들만 공유되거나(FNN 파라미터들은 공유되지 않지만) FFN 파라미터들만 공유되는(attention 파라미터들은 공유하지 않는다) 모든 공유 전략(ALBERT-style), 비공유 전략(BERT-style), 중간 전략을 비교한다.
- 모든 공유 전략은 두 조건 모두에서 성능을 해치지만 (-1.5 on Avg)에 비해 E = 768(-2.5 on Avg)에 비해 덜 심각함
- 또한, 성능 저하의 대부분은 FFN-layer 파라미터를 공유하는 것으로 보이며, attention 파라미터를 공유하는 것은 E = 128(+0.1 on Avg)일 때, E = 768(-0.7 on Avg)일 때 약간의 감소를 초래
4.6. SENTENCE ORDER PREDICTION (SOP)
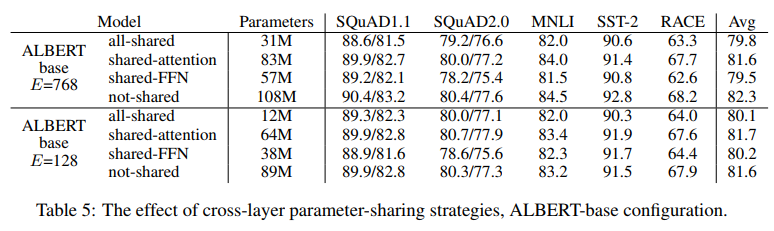
- ALBERTbase 구성을 이용하여 None(XLNet- and RoBERTa-style), NSP(BERT-style), SOP(ALBERT-style)의 추가 문장간 loss에 대한 3가지 실험 조건을 비교
- 결과는 표 6에서 내재적(MLM, NSP, SOP task의 정확성)과 세부 task 모두에 대해 보여짐
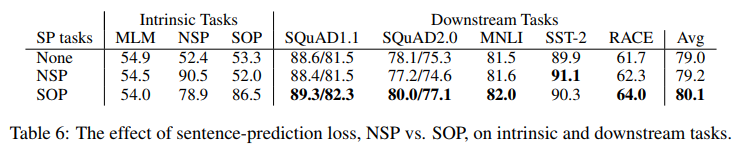
- 본 연구의 결과 NSP loss는 SOPtask에 차별적인 영향을 미치지 않는 것으로 나타남(“None” 조건에 대한 랜덤-가치 성능과 유사한 52.0% 정확도)
- 이로써 NSP는 토픽 시프트만을 모델링하는 것으로 결론지을 수 있음
- 반면, SOP loss는 NSP task를 비교적 잘 해결하고(78.9% 정확도), SOP task는 훨씬 더 잘 해결한다(86.5% 정확도)
- 더 중요한 것은 SOP loss가 다문장 인코딩 task의 세부 task 성능을 지속적으로 향상시키는 것으로 보임(약 +1% SQuAD1.1, +2% SQuAD2.0, +1.7% forRACE)
4.7. EFFECT OF NETWORK DEPTH AND WIDTH
- 이 섹션에서는 깊이(층 수)와 width(hidden size)가 ALBERT의 성능에 미치는 영향을 확인
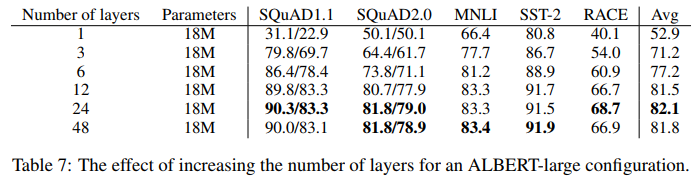
- 표 7은 다른 수의 레이어를 사용하는 ALBERT 대형 구성의 성능을 보여줌(표 2 참조)
- 3개 이상의 레이어를 갖는 네트워크는 이전 깊이로부터의 파라미터를 사용하여 fine-tuning함으로써 학습됨(예를 들어, 12-레이어 네트워크 파라미터는 6-레이어 네트워크 파라미터의 체크포인트로부터 fine-tuning된다)
- 4 만약 3-레이어 ALBERT 모델을 1-레이어 ALBERT 모델과 비교한다면, 동일한 수의 파라미터를 가지고 있지만, 성능은 상당히 증가
- 그러나 계층 수를 계속 증가시킬 때 수익률이 감소. 12- 레이어 네트워크의 결과는 24- 레이어 네트워크의 결과와 비교적 가깝고 48- 레이어 네트워크의 성능은 감소하는 것으로 보임
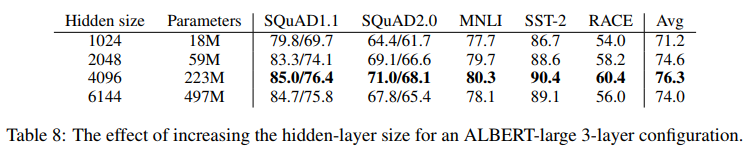
- width에 대한 유사한 현상은 표 8에서 3층 ALBERT 대형 구성에 대해 볼 수 있음
- hidden size를 증가시키면 수익이 감소하면서 성능이 증가
- 은닉된 6144의 크기에서 성능은 상당히 감소하는 것으로 보임
- 저자들은 이 모델들 중 어느 것도 학습 데이터를 과대 적합하지 않은 것으로 보이며, 그들은 모두 가장 잘 수행되는 ALBERT 구성에 비해 더 높은 학습과 개발 loss를 가지고 있다는 것을 주목
4.8. WHAT IF WE TRAIN FOR THE SAME AMOUNT OF TIME?
- 표 3의 속도 향상 결과는 BERT-large의 데이터 처리량이 ALBERT-xxlarge에 비해 약 3.17x 더 높다는 것을 나타냄
- 학습이 길어지면 대개 더 좋은 성능을 발휘하기 때문에 데이터 처리량(학습 단계 수)을 제어하는 대신 실제 학습 시간을 제어(즉, 모델이 동일한 시간 동안 학습하도록 한다)하는 비교를 수행
- Table9에서는 400k 학습 단계(34hof 학습 후) 이후의 BERT-large 모델의 성능을 125k 학습 단계(32h 학습)로 ALBERT-xxlarge 모델을 학습하는 데 필요한 시간과 대략 동일하게 비교

- 대략 같은 시간 동안 학습한 후, ALBERT-xxlarge는 BERT-large보다 유의하게 우수함
- Avg에서 +1.5% 더 우수하며, RACE의 차이는 +5.2%로 높음
4.9. DO VERY WIDE ALBERT MODELS NEED TO BE DEEP(ER) TOO?
- 4.7절에서는 ALBERT-large (H=1024)의 경우 12-layer와 a24-layer 구성의 차이가 작음을 보여줌
- 이 결과는 ALBERT-xxlarge (H=4096)와 같이 훨씬 더 넓은 ALBERT 구성에 여전히 유효할까?

- 답은 표 10의 결과에 의해 주어짐
- 세부 정확도 측면에서 12-layer와 24-layerALBERT-xlarge 구성의 차이는 무시할 수 있으며 Avg 점수는 동일
- 저자들은 모든 교차층 파라미터(ALBERT 스타일)를 공유할 때 12층 구성보다 더 깊은 모델이 필요하지 않다고 결론
4.10. ADDITIONAL TRAINING DATA AND DROPOUT EFFECTS
- 이때까지 수행된 실험은 Devlin et al., (2019)와 동일하게 위키피디아와 북코퍼스 데이터셋만을 사용
-
여기에서는 XLNet (Yang et al., 2019)과 RoBERTa (Liu et al., 2019)가 사용하는 추가 데이터의 영향에 대한 측정을 보고
- Fig.3a는 추가 데이터가 없는 두 가지 조건에서 dev set MLM 정확도를 시각화하고 후자의 조건은 상당한 부스트를 제공
- 또한, SQuAD 벤치마크(위키피디아 기반이며, 따라서 도메인 외 학습 자료에 의해 부정적인 영향을 받는)를 제외하고, 표 11의 세부 task에 대한 성능 향상을 관찰
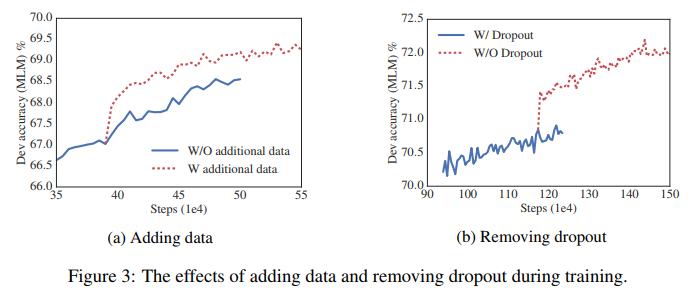

- 또한 1M 단계의 학습을 받은 후에도 가장 큰 모델은 여전히 학습 데이터에 과적합하지 않는다는 점에 유의해야 함
- 그 결과, 저자들은 모델 용량을 더 늘리기 위해 dropout을 제거하기로 결정
- 3b는 dropout을 제거하면 MLM의 정확도가 크게 향상됨을 보여줌
- 1M 학습 단계(표 12)에서 ALBERT-xlarge에 대한 중간 평가도 dropout 제거가 세부 task에 도움이 된다는 것을 확인시켜 줌
- Convolutional Neural Networks에서 배치 정규화와 dropout의 조합이 유해한 결과를 가져올 수 있다는 것을 보여주는 경험적 (Szegedy et al., 2017)과 이론적 (Liet al., 2019) 증거가 있음
- 우리가 아는 한, 저자들은 중퇴자가 대형 트랜스포머 기반 모델에서 성능을 해칠 수 있다는 것을 처음으로 보여주는 것

4.11. CURRENT STATE-OF-THE-ART ON NLU TASKS
- 이 섹션에서 보고한 결과는 Devlin et al.이 사용한 학습 데이터를 이용
- (2019)는 Liu et al. (2019)과 Yang et al. (2019)이 사용한 추가 자료로 아쉬움을 사용
- 저자들은 fine tuning을 위한 두 가지 설정, 즉 단일 모델과 앙상블에 따라 최첨단 결과를 보고
-
두 가지 설정 모두에서 저자들은 단일 과제 fine-tuning5만 한다.(2019)의 dev set에서 저자들은 5점 이상의 중간 결과를 보고
- 단일 모델 ALBERT 구성은 논의된 최상의 성능 설정을 통합: MLM과 SOP loss를 결합한 ALBERT-xlarge 구성 (표 2) 및 중도 탈락이 없음
- 최종 앙상블 모델에 기여하는 체크 포인트는 개발 설정 성능에 따라 선택
- 이 선택에 고려된 체크 포인트 수는 task에 따라 6에서 17까지
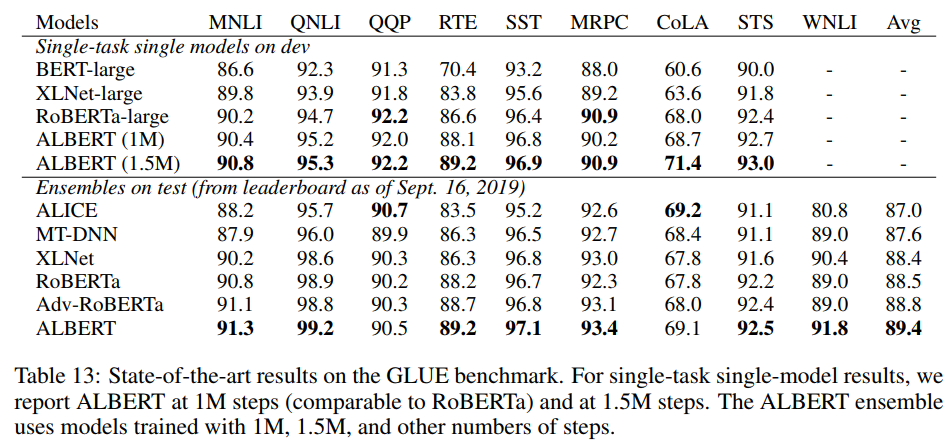
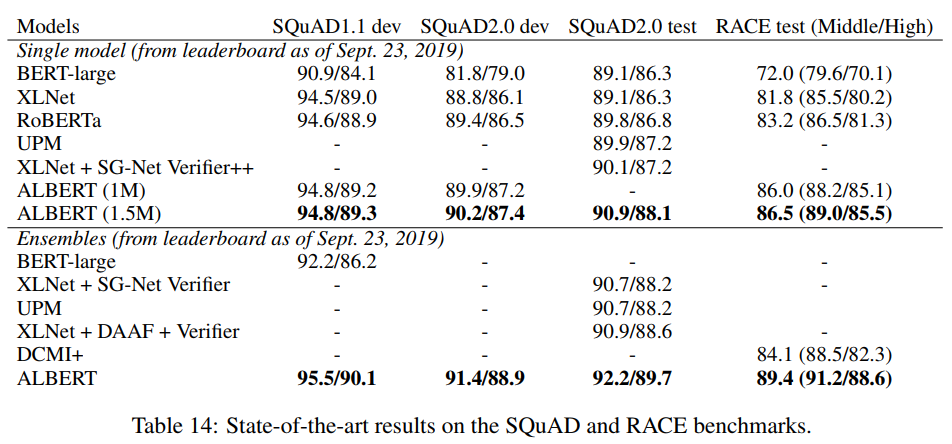
- GLUE(표 13)와 RACE(표 14) 벤치마크의 경우, 12층 및 24층 아키텍처를 사용하여 후보들이 서로 다른 학습 단계에서 fine-tuning되는 앙상블 모델의 모델 예측을 평균
- SQuAD (표 14)의 경우, 저자들은 여러 확률을 갖는 스팬의 예측 점수를 평균. 저자들은 또한 “답변할 수 없는”결정의 점수를 평균
- 단일 모델과 앙상블 결과 모두 ALBERT가 세 가지 벤치마크 모두에서 현저하게 개선되어 GLUE 점수 89.4, SQuAD 2.0 테스트 F1 점수 92.2, RACE 테스트 정확도 89.4를 달성
- 후자는 특히 강한 개선으로 보이며, BERT(Devlin et al., 2019), XLNet(Yang et al.,2019), +7.6%의 XLNet(Yang et al., 2019), +6.2%의 RoBERTa(Liu et al., 2019), 그리고 DCMI+(Zhang et al., 2019)의 앙상블로, 독해 과제를 위해 특별히 고안된 여러 모델의 앙상블
- 저자들의 단일 모델은 86.5%의 정확도를 보이며, 이는 여전히 최첨단 앙상블 모델보다 2.4% 더 나음
5. DISCUSSION
- ALBERT-xlarge는 BERT-large보다 매개 변수가 적고 훨씬 더 좋은 결과를 얻지만, 더 큰 구조로 인해 계산적으로 더 비쌈
- 따라서 중요한 다음 단계는 ALBERT의 학습과 추론 속도를 희소주의(Child et al.,2019)와 차단주의(Shen et al., 2018)와 같은 방법을 통해 가속화하는 것
- 추가 표현력을 제공할 수 있는 직교 연구 라인에는 하드 예제 마이닝(Mikolov et al., 2013)과 보다 효율적인 언어 모델링 학습(Yang et al., 2019)이 포함
- 또한 문장 순서 예측이 더 나은 언어 표현을 이끌어내는 더 일관되게 유용한 학습 과제라는 설득력 있는 증거를 가지고 있지만, 저자들은 아직 그 결과 표현을 위한 추가적인 표현력을 창출할 수 있는 현재의 자체 감독 학습 loss에 의해 포착되지 않은 더 많은 차원이 있을 수 있다고 가정



댓글남기기