
들어가며
- 페이퍼 다운로드 링크: arxiv 링크
- ELMo github: github 링크
- 다양한 언어의 ELMo embedding 다운로드 페이지: resource 다운로드 링크
- 한국어는 압축 상태에서 491MB
- corpus: Korean CoNLL17 corpus
- num of tokens: 551,643,170
- lemmatized: false
- prerequisite: python >= 3.6
1. Abstract
- (1) 단어 사용의 복잡한 특성 (예 : 구문과 의미론)과 (2) 이러한 특성이 언어적 맥락 (즉, 다의어를 모델링하기 위해)에 어떻게 사용되는지 모델링하는 새로운 유형의 심층적인 맥락화 된 단어 representation을 소개
- 이 논문에서 제시한 ‘word vector’는 대형 텍스트 코퍼스에 미리 훈련된 deep bi-directional 언어 모델(biLM)의 내부 상태의 학습된 함수
- 이 representation들은 기존의 모델에 쉽게 추가될 수 있고 문제 해결, 텍스트 entailment, 감정 분석 등 6가지 어려운 NLP 문제에 걸쳐 최고 수준 성능을 크게 개선할 수 있음을 보여주며, 여러 종류의 준지도 감독 신호를 혼합하기 위해 downstream 모델을 사용
2. Introduction
- 사전에 훈련된 단어 representation은 많은 뉴럴 언어 이해 모델의 핵심 구성 요소(Mikolov et al.,2013, Pennington et al., 2014). 하지만 수준 높은 표현을 학습하기는 어려움
- (1) 단어 사용의 복잡한 특성 (예: 구문과 의미론)과 (2) 이러한 사용이 언어적 맥락 (예: 다의어)에 따라 어떻게 다른지를 이상적으로 모델링해야 함
-
이 논문은 두 가지 문제를 직접 다루고, 기존 모델에 쉽게 통합 될 수 있으며, 도전적인 언어 이해 문제에 걸쳐 모든 고려 사항이 있다면 현존 최고 성능을 크게 향상시킬 수 있는 새로운 유형의 심층적인 맥락화 된 단어 representation을 소개
- 우리의 representation은 각 토큰에 전체 입력 문장의 함수인 representation이 할당된다는 점에서 전통적인 단어 유형 임베딩과 다름
- 우리는 큰 텍스트 코퍼스에서 결합된 언어 모델(coupled Language Model) 목표를 가지고 훈련된 양방향 LSTM에서 파생된 벡터를 사용
- 이러한 이유로 우리는 ELMo representation(Embeddings of Language Models)이라고 부름
- 상황별 단어 벡터를 학습하기 위한 이전의 접근방식(Peters et al., 2017; McCann et al., 2017)과는 달리, ELMo의 모든 내부 계층의 함수라는 점에서 ELMo 표현은 깊다
-
구체적으로는 각 실제 task에 대해 각 입력 단어 위에 쌓인 벡터의 선형 조합을 학습하는데, 이는 상위 LSTM 계층을 사용하는 것보다 성능이 현저하게 향상
- 이러한 방식으로 내부 상태를 결합하면 매우 풍부한 단어 표현이 가능해짐
- 내재적 평가를 사용하여 상위(higher-level) LSTM state은 단어 의미의 문맥 의존적 측면(예: 지도 학습 방식의 단어 중의성 해소 task에서 잘 수행하도록 수정하지 않고 사용할 수 있음)을 포착하는 반면, 하위(lower-level) state이 구문적 측면을 학습함(예: POS 태깅 등에 사용할 수 있음)
-
이 모든 신호(signal)를 동시에 노출하는 것은 매우 유익하며, 학습된 모델이 각 과제에 가장 유용한 준지도학습을 선택할 수 있게 함
- 저자들은 광범위한 실험을 통해 ELMo representation이 실제로 매우 잘 작동한다는 것을 보여줌
- 우선 텍스트를 수반한, 질문 응답 및 감정 분석을 포함한 6 가지 다양하고 도전적인 언어 이해 문제에 대해 기존 모델에 쉽게 추가할 수 있음을 보여줌
- ELMo representation을 추가하면 최대 20%의 상대적 오류 감소를 포함하여 모든 경우에 현존 최고 수준의 상태를 크게 개선
- 직접 비교할 수 있는 작업의 경우 ELMo는 CoVe (McCan)보다 우월
- 신경 기계 번역 인코더를 사용하여 상황화된 표현을 계산하는 넷 알., 2017).
- 마침내 ELMo와 CoVe의 분석은 깊은 표현이 LSTM의 최상층에서 파생된 표현보다 더 잘 표현된다는 것을 발견
- 훈련된 모델과 코드는 공개적으로 이용 가능하며 ELMo가 다른 많은 NLP 문제에 대해서도 비슷한 이득을 제공할 것으로 기대
3. ELMo: Embeddings from Language Models
- 대부분의 널리 사용되는 단어 임베딩(Pennington et al., 2014)과는 달리, ELMo 단어 표현은 이 절에서 설명한 바와 같이 전체 입력 문장의 함수
- 이들은 내부 네트워크 상태의 선형 함수(Sec. 3.2)로, 캐릭터 콘볼루션(Sec. 3.1)이 있는 2단 biLM 위에 연산. 이 설정을 통해 우리는 반감속 학습을 할 수 있는데, 여기서 biLM은 대규모로 사전 훈련되고(Sec. 3.4) 광범위한 기존 신경 NLP 아키텍처에 쉽게 통합(Sec. 3.3)
3-1. Bidirectional language models
- N 토큰 시퀀스 가 주어지면 전방 언어 모델은 히스토리 가 주어진 토큰 의 확률을 모델링하여 시퀀스의 확률을 계산
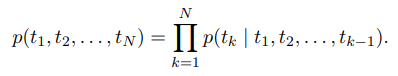
까지의 시퀀스 정보를 가지고 의 확률 계산
- 최신 신경 언어 모델(Jozefowicz et al. 2016; Melis et al., 2017; Merity et al., 2017) 문맥 독립적인 토큰 표현 (토큰 포함 또는 CNN을 통해 문자 위에 표시)를 계산한 다음 LSTM의 L개 레이어를 통과
- 각 위치 k에서, 각 LSTM 계층은 상황에 따라 표현되는 를 출력 (j = 1, . . . , L)
- 최상위 계층 LSTM 출력 는 소프트맥스 계층으로 다음 토큰 을 예측하는 데 사용
- backward LM은 향후 상황에 따라 이전 토큰을 예측하면서 역순으로 시퀀스를 실행하는 것을 제외하고 forward LM과 유사:
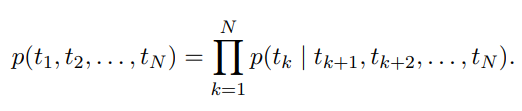
- L개 레이어 딥 모델에서 각 역 LSTM 레이어 j가 주어진 에서 의 representation 을 생성하면서 forward LM과 유사한 방식으로 구현될 수 있음
- biLM은 전방 및 후방 LM을 모두 결합. 본 논문의 수식은 앞 방향과 뒤 방향의 로그 가능성을 함께(jointly) 최대화:
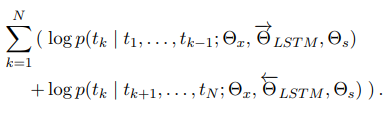
- 각 방향에서 LSTM에 대한 별도의 매개 변수를 유지하면서 토큰 representation 과 소프트 맥스 레이어 의 매개 변수를 전후 방향으로 묶음
- 전체적으로 이 공식은 Peters et al.(2017)의 접근 방식과 유사하며, 예외적으로 저자들은 완전히 독립적인 매개변수를 사용하는 대신 방향 간에 일부 가중치를 공유
- 다음 절에서는 biLM 레이어의 선형 결합인 단어 representation을 학습하는 새로운 접근법을 도입하여 이전 작업에서 출발
3.2 ELMo
아래 그림들은 다양한 사람들이 그린 ELMo 모델 아키텍처(원본 페이퍼에는 그림이 없음)
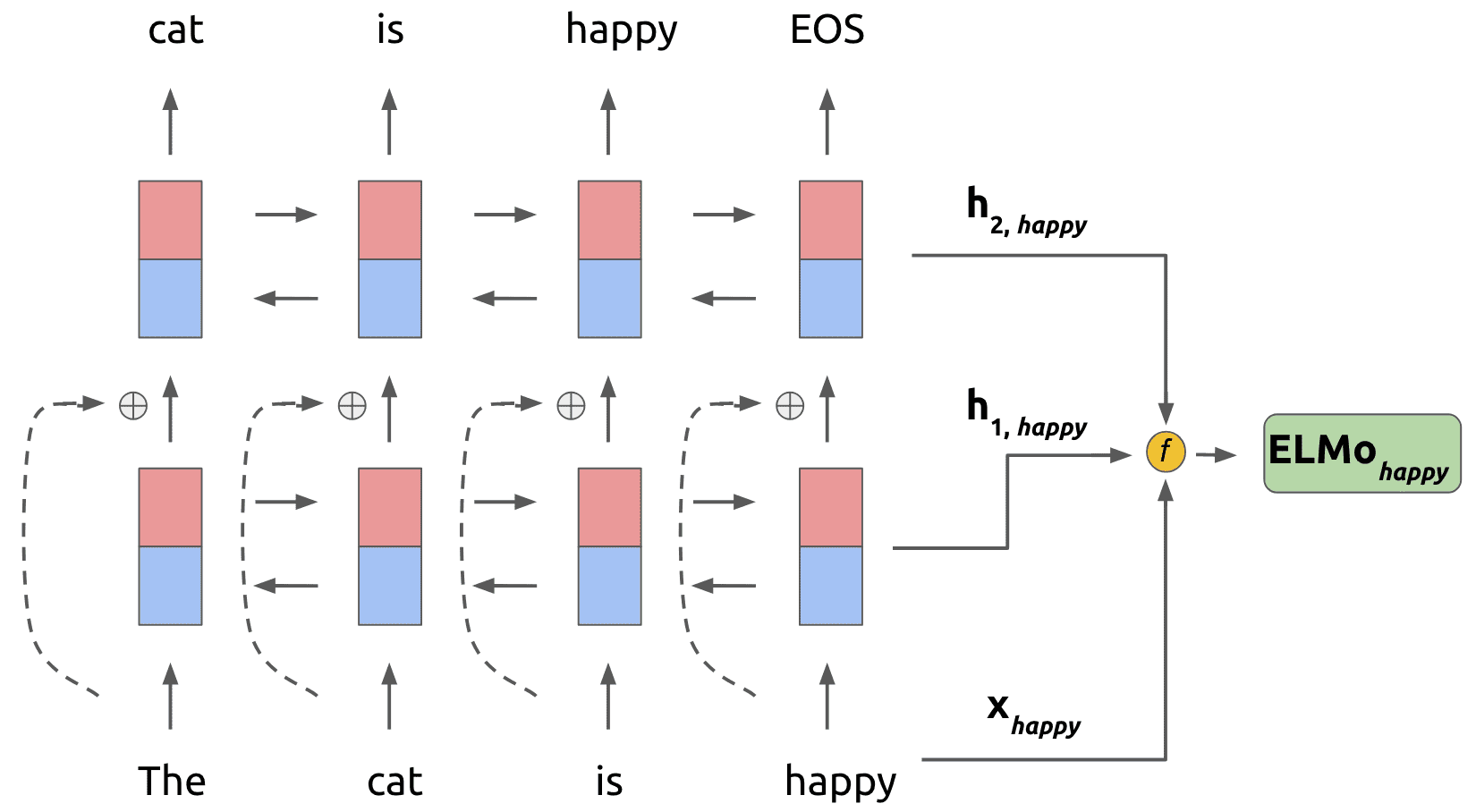
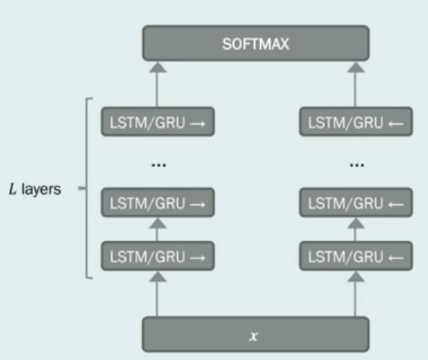
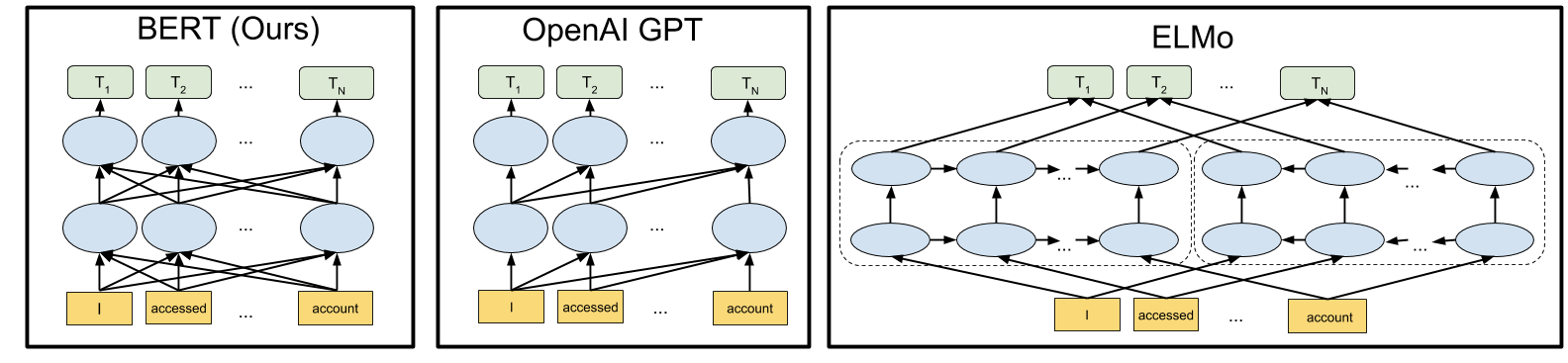
- ELMo는 특정 task를 위한, biLM의 중간층 표현의 조합이라 할 수 있음. 각 토큰 에 대해 biLM은 representation 집합을 계산
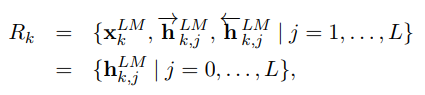
- 여기서 은 각 biLSTM 계층에 대해 토큰 레이어이며
- downstream 모델에 포함시키기 위해 ELMo는 의 모든 레이어를 단일 벡터인 로 만듬
- 가장 간단한 경우, ELMo는 TagLM(Peters et al., 2017) 및 CoVe(McCann et al., 2017)와 같이 최상단 레이어 을 선택
- 보다 일반적으로 모든 biLM 레이어에 대한 task 별 가중치를 계산
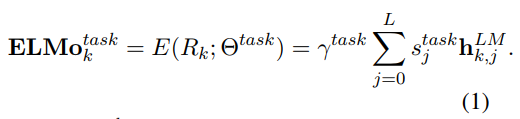
- (1)에서 는 소프트맥스 정규화 가중치이고 스칼라 매개 변수 는 작업 모델이 전체 ELMo 벡터를 스케일링할 수 있게 해줌
- y는 최적화 프로세스를 지원하는 데 실질적인 중요성을 가지고 있음 (자세한 내용은 논문 말미의 추가 자료 참조)
- 각 biLM 레이어의 활성화가 다른 분포를 가지고 있다는 것을 고려할 때, 어떤 경우에는 레이어 정규화(Ba et al., 2016)를 가중치하기 전에 각 biLM 레이어에 적용하는 데 도움이 될 수 있음
3.3 Using biLMs for supervised NLP tasks
- 사전에 훈련된 biLM과 목표 NLP 작업을 위한 지도학습 아키텍처를 고려할 때, 다음 내용들은 biLM을 사용하여 task별 모델을 개선하는 간단한 과정
-
우리는 biLM을 실행하고 각 단어에 대한 모든 레이어 representation을 기록함. 그런 다음, 아래 설명된 바와 같이 최종 task별 모델이 이러한 representation의 선형 조합을 학습할 수 있도록 함
- 먼저 biLM이 없는 지도학습 모델에서 가장 아래쪽의 레이어를 고려. 대부분의 지도학습 기반 NLP 모델들은 하위 계층에서 공통 아키텍처를 공유하여 일관되고 통일된 방식으로 ELMo를 병합할 수 있음
- 토큰 시퀀스 은 사전 훈련된 단어 임베딩 및 선택적으로 문자 기반 표현을 사용하여 각 토큰 위치에 대해 컨텍스트 독립 토큰 representation 를 형성하는 것이 표준임
-
그러면 모델은 일반적으로 양방향 RNN, CNN 또는 FNN을 사용하는 맥락에 민감한 representation 를 생성
- ELMo를 지도학습 모델에 추가하기 위해 먼저 biLM의 가중치를 동결시킨 다음 로 ELMo 벡터 를 연결하고 ELMo 강화(enhanced) representation 을 task RNN에 전달
- 일부 task(예: SNLI, SQuAD)의 경우, 또 다른 출력 특정 선형 가중치 세트를 도입하고 를 로 대체하여 task RNN의 출력에 ELMo를 포함함으로써 추가적인 개선을 관찰
- 지도학습 모델의 나머지 부분이 변하지 않으므로 이러한 추가는 보다 복잡한 뉴럴 모델의 맥락에서 발생할 수 있음
- 예를 들어, bi-attention 레이어가 biLSTM를 따르는 Sec. 4에서의 SNLI 실험이나, 클러스터링 모델이 biLSTM 상층부에 계층화되는 상호참조 실험을 참조
- 마지막으로, 우리는 ELMo에 적당한 양의 dropout을 추가하는 것이 유익하다는 것을 발견(Srivastava et al.,2014)
- 그리고 어떤 경우에는 loss에 를 추가하여 ELMo 가중치를 정규화하는 것이 유익함
- 이것은 모든 biLM 레이어의 평균에 가깝게 유지하기 위해 ELMo 가중치에 유도성 바이어스(inductive bias)를 부과하는 것
활용 단계
(1) Pretrained 된 BiLM 에 Embedding 하고자 하는 문장을 Input 으로 넣어서 Inference 실행
(2) BiLM 각 Layer 의 Vector 의 합을 각 Layer 별 가중치를 적용하여 구한다.
(3) RNN Sequence Length 수 만큼의 Vector 가 생성이 된다.
3.4 Pre-trained bidirectional language model architecture
- 본 논문에서 pre-trained biLM은 Jozefowicz et al. (2016), Kim et al. (2015) 에서의 모델과 유사하지만 양방향의 통합(joint) 학습을 지원하고 LSTM 레이어 사이의 residual connection을 추가하기 위해 형태가 변경되었음
-
Peters et al.(2017)이 전방 전용 LM과 대규모 훈련에 비해 biLM의 사용의 중요성을 강조하였기 때문에, 저자들도 이 작품에서 대규모 biLM에 초점을 맞추었음
- 전체 언어 모델의 복잡도를 하위 과제에 대한 모델 크기 및 계산 요구 사항과 균형을 맞추기 위해 Jozefowicz et al. (2016)의 단일 베스트 모델
CNN-BIG-LSTM에서 모든 임베딩 및 hidden 차원을 반으로 나누었음 - 최종 모델은 4096개의 유닛 및 512 차원을 갖는 biLSTM 레이어. 첫번째 레이어에서 두번째 레이어 사이에 residual connection을 사용
- 문맥에 민감하지 않은 타입의 representation은 2개의 highway 레이어(Srivastava et al.,2015)에 뒤이어 2048개의 character 단위 n-gram 컨볼루션 필터를 사용하며, 선형 프로젝션을 통해 512 representation으로 축소시킴
-
결과적으로, biLM은 순전히 문자 입력으로 인해 훈련 세트 외부를 포함하여 각 입력 토큰에 대해 3개의 representation 레이어를 제공. 대조적으로, 전통적인 단어 임베딩 방법은 고정된 어휘의 토큰에 대한 하나의 representation 레이어만 제공
1B Word Benchmark(Chelba et al., 2014)을 이용해 10 epoch 학습한 후, 평균 forward, backward perplexity는 30.0(비교: forwardCNN-BIG-LSTM은 39.7)- 일반적으로 forward, backward의 복잡성이 거의 동일하며, backward 값이 약간 낮다는 것을 확인함
- biLM은 일단 pre-trained되고 나면 모든 task에 대한 representation을 계산할 수 있음
- 어떤 경우에는 도메인 특정 데이터에서 biLM을 fine tuning하면 perplexity가 현저히 감소하고 downstream task 성능이 향상. 이것은 biLM에 대한 도메인 transfer의 유형으로 볼 수 있음
- 결과적으로 대부분의 경우 downstream task에서 fine-tuned biLM을 사용. 자세한 내용은 보충 데이터를 참조
perplexity: 1) 확률 분포가 얼마나 쉬운지를 측정하는 척도 2) 예측 모델이 얼마나 가변적인지를 측정 3) 예측 오차의 척도
4. Evaluation
- 표 1은 다양한 6 개의 벤치 마크 NLP task 세트에서 ELMo의 성능을 보여줌. 이것은 다양한 모델 아키텍처와 언어 이해 task에 대한 매우 일반적인 결과라 할 수 있음
- 이 섹션의 나머지 부분은 개별 작업 task에 대한 높은 수준의 스케치를 제공. 전체 실험 세부 사항에 대한 논문 말미의 추가 자료를 참조
Question Ansering
- 스탠포드 질의응답 데이터 세트(SQuAD)(Rajpurkar et al.,2016)에는 100K+ 크라우드소싱된 질문 답안 쌍이 포함되어 있음
- 주어진 위키피디아 단락에서 답변 구절이 추출되어 있음
- 우리의 기본 모델(Clarkand Gardner, 2017)은 Seo et al.에서 Bidirectional Attention Flow 모델의 개선된 버전(BiDAF; 2017)
- 이것은 bidirectional attention 요소 뒤에 self-attention layer를 추가하고, 일부 풀링 작업을 단순화하며, LSTM을 GRU로 대체(GRU; Choet al., 2014)
- 기본 모델에 ELMo를 추가한 후 테스트 세트 F1은 81.1%에서 85.8%로 4.7% 향상, 베이스라인에 비해 24.9%의 상대적 오류 감소와 전체 단일 모델 최신의 1.4% 향상
- 11명의 멤버 앙상블이 리더보드에 제출할 때 전체 첨단 기술인 F1을 87.4로 밀어낸다. 2 ELMo를 사용한 4.7%의 증가도 기준선 모델에 CoVe를 추가하는 것보다 1.8% 향상(Mcan et al., 2017)
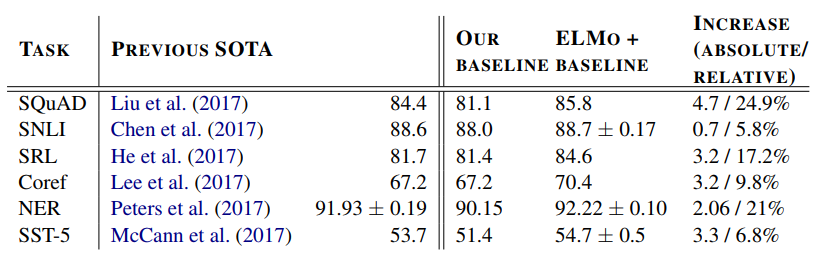
표 1: 6가지 벤치마크 NLP 작업에서 ELMo의 향상된 신경 모델과 최첨단 단일 모델 기준선의 비교 테스트 세트 성능 메트릭은 SNLI 및 SST-5의 정확도, SQuAD, SRL 및 NER의 경우 F1, Coref의 경우 평균 F1 등 작업마다 다름 NER과 SST-5의 시험 크기가 작기 때문에, 우리는 서로 다른 무작위 시드로 5회 주행의 평균과 표준 편차를 보고한다. “증가” 열에는 기준선에 대한 절대적 및 상대적 개선사항이 모두 나열되어 있다.
Textual entailment
- Text entailment는 “가설”이 사실인지 여부를 결정하는 과제
- 스탠포드 자연어 추론(SNLI) 코퍼스(Bowmanet al., 2015)는 약 550K 가설/프리미스 쌍을 제공
- 우리의 기준선인 ESIM sequence model from Chen et al. (2017)은 전제와 가설을 인코딩하기 위해 biLSTM을 사용하고, 그 다음에 매트릭스 주의 계층, 로컬 추론 계층, 또 다른 biLSTM 추론 구성 계층, 그리고 마지막으로 출력 계층 전에 풀링 연산을 사용
- 전반적으로 ELMo를 theESIM 모델에 추가하면 5개의 무작위 시드에 평균 0.7%의 정확도가 향상
- 5개의 멤버 앰블은 전체 정확도를 89.3%로 밀어넣어 이전 앙상블을 88.9%로 최고치로 능가(공 외, 2018).
Semantic role labeling
- 의미적 역할 라벨링(SRL) 시스템은 문장의 술어-논증 구조를 모델링하며, 종종 “누가 누구에게 무엇을 했는지”라고 대답하는 것으로 묘사
- He et al. (2017)는 SRL을 BIO 태깅 문제로 모델링하고 Zhou와 Xu(2015)를 따라 전후 방향이 인터리빙된 8층 딥 biLSTM을 사용
- 표 1에서 보듯이, ELMo를 He et al.의 재 구현에 추가할 때.(2017) 단일 모델 테스트 세트 F1은 81.4%에서 84.6%로 3.2% 증가하여 OntoNotes 벤치마크(Pradhan et al., 2013)의 새로운 최첨단 앙상블 결과보다 1.2% 향상
Coreference resolution
Named entity extraction
Sentiment analysis
5. Analysis
- 이 절에서는 주요 주장의 유효성을 확인하고 ELMo 표현의 몇 가지 흥미로운 측면을 설명하기 위한 절제 분석을 제공
- Sec.5.1은 다운스트림 작업에서 깊은 맥락 표현을 사용하면 biLM 또는 MT 인코더에서 생산되는지 여부에 관계없이 최상위 계층만을 사용하는 이전 작업의 성능을 향상시키고 ELMo 표현이 최상의 전반적인 성능을 제공한다는 것을 보여줌
- Sec.5.3은 다양한 유형의 ELMo 표현을 탐구
- 또한, biLM에서 캡처된 상황 정보를 사용하여 두 가지 독특한 평가를 통해 구문 정보가 하위 계층에서 더 잘 표현되고 의미 정보가 MT 인코더와 일치하는 상위 계층에서 캡처된다는 것을 알 수 있음
- ELMo는 과제 전반에 걸쳐 배운 가중치를 시각화한다(Sec.5.5).
5.1 Alternate layer weighting schemes
- biLM 층을 결합하기 위한 방정식 1에는 많은 대안이 있음
- 문맥 표현에 대한 이전의 연구는 biLM (Peters et al., 2017) 또는 MT 인코더 (CoVe, McCann et al., 2017)에서 나온 것이든 마지막 레이어 만 사용
- 정규화 매개 변수의 선택도 중요
- 1과 같은 큰 값은 가중 함수를 효과적으로 레이어에 대한 간단한 평균으로 감소시키는 반면, 작은 값 (예 : 0.001)은 레이어 가중치를 바꿀 수 있기 때문
- 표 2는 SQUAD, SNLI 및 SRL에 대한 이러한 대안을 비교
- Alllayer의 표현을 포함하면 마지막 레이어를 사용하는 것에 비해 전반적인 성능이 향상되고 마지막 레이어의 컨텍스트 표현이 포함되면 기본 라인에 비해 성능이 향상
- 예를 들어, SQUAD의 경우 마지막 biLM 레이어를 사용하는 것이 기본 라인보다 개발 F1을 3.9 % 향상시킴
- 마지막 레이어를 사용하는 대신 모든 biLM 레이어를 평균하는 것은 F1을 또 다른 0.3 % 개선한다 ( “마지막 전용”= 1 열에 비해).
- 세타스크 모델이 개별 레이어 가중치를 배울 수 있게하면 F1이 또 다른 0.2 % 개선된다. (=1 대 0.001).
-
작은 lambda을 선호하지만 NER의 경우 훈련 세트가 작은 작업의 경우 결과는 민감하지 않다 (표시되지 않음).
- 전반적인 추세는 CoVe와 유사하지만 기준선에 비해 증가폭이 더 작음
- SNLI의 경우, λ=1로 모든 레이어를 평균화하면 마지막 레이어보다 개발 정확도가 88.2~88.7% 향상
- SRL F1은 마지막 계층만 사용한 것에 비해 λ=1 케이스에 대해 한계 0.1% 증가한 82.2를 기록
5.2 Where to include ELMo?
- 본 논문에서 모든 업무 아키텍처는 최하위 계층 biRNN에 대한 입력으로 단어 내장만을 포함
- 그러나, 우리는 업무별 아키텍처에서 생체RNN의 출력에 ELMo를 포함하면 일부 업무의 전반적인 결과가 개선된다는 것을 발견
- 표 3에서 보듯이 SNLI와 SQuAD에 대한 입력 및 출력 레이어의 ELMo는 입력 레이어보다 개선되지만, SRL(및 코어 분해능은 표시되지 않음)의 경우, 성능이 입력 레이어에만 포함될 때 가장 높음
- 이 결과에 대한 한 가지 가능한 설명은 SNLI와 SQuAD 아키텍처가 모두 biRNN 이후의 주의 계층을 사용하므로, 이 계층에 ELMo를 도입하면 모델이 biLM의 내부 표현에 직접 참여할 수 있다는 것
- SRL의 경우, 작업별 컨텍스트 표현은 biLM의 컨텍스트 표현보다 더 중요할 수 있음
5.3 What information is captured by the biLM’s representations?
- ELMo를 추가하면 단어 벡터에만 작업 성능이 향상되므로 biLM의 맥락 표현은 단어 벡터에 캡처되지 않은 NLP 작업에 일반적으로 유용한 정보를 인코딩해야 함
-
직관적으로, biLM은 그들의 맥락을 사용하여 단어의 의미를 모호하게해야 함
- 아주 다의적인 단어인 ‘놀이’를 생각해보자
- 표 4의 맨 위에는 글로브 벡터를 사용하여 “플레이”에 가장 가까운 이웃이 나열되어 있음
- 이들은 언어의 여러 부분(예를 들어 「연주」「연주」「동사」로 「연주」「명사」로 「게임」에 걸쳐 퍼져나가지만 스포츠관련 「연주」감각에 집중돼 있음
- 대조적으로, 두 개의 하단 행은 소스 문장에서 “플레이”에 대한 biLM의 컨텍스트 표현을 사용하여 SemCor 데이터셋에서 가장 가까운 이웃 문장을 보여줌 (아래 참조)
- 이러한 경우, biLM은 소스 문장에서 언어와 단어 감각의 일부를 모호하게 만들 수 있음
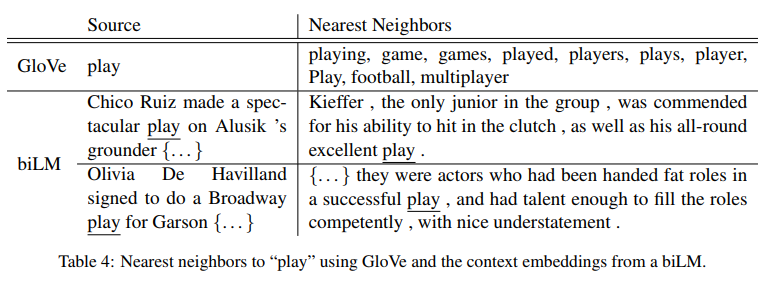
- 이러한 관측치는 Belinkov 등과 유사한 맥락 표현의 내재적 평가를 사용하여 정량화할 수 있음 (2017).
- biLM에 의해 인코딩 된 정보를 분리하기 위해, 표현은 미세 결정형 단어 감각 모호성 (WSD) 작업 및 POS 태그 작업에 대한 예측을 직접 만드는 데 사용
- 이 접근법을 사용하여 CoVe와 비교하고 각 개별 층을 비교할 수도 있다.
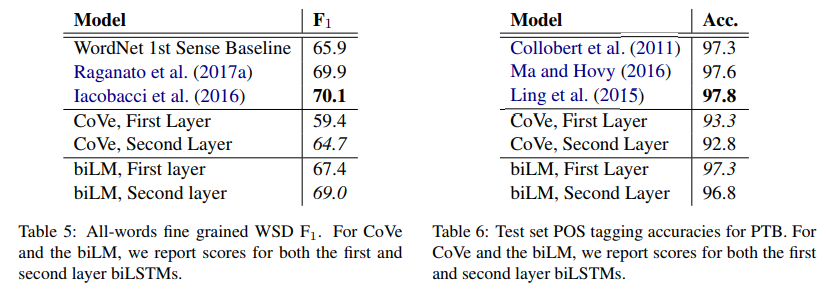
Word sense disambiguation
POS tagging
Implications for supervised tasks
5.4 Sample efficiency
5.5 Visualization of learned weights
6. Conclusion
- 이 논문은 biLMs로부터 고품질의 심층 문맥 의존 표현을 배우는 일반적인 접근법을 소개하고 ELMo를 광범위한 NLP 작업에 적용할 때 큰 개선점을 보여 주었음
- 또 ablation 등 제어된 실험을 통해 biLM 계층이 문맥에서 단어에 대한 다양한 유형의 통사적 및 의미적 정보를 효율적으로 인코딩하고 모든 계층을 사용하면 전반적인 작업 성능이 향상된다는 것을 확인



댓글남기기