
참고자료
- 원 논문 (Attentional Factorization Machines: Learning the Weight of Feature Interactions via Attention Networks)
들어가기 전에 알아야될 용어
- Factorization Machines
- FM은 고차원 데이터에서도 제품 변수 간의 상호작용을 통해 효율적으로 사용할 수 있는 지도학습으로 회귀분석과 분류분석 기법을 모두 할 수 있는 기계학습
- 다항식 회귀 또는 커널 방법과 동등하지만, 더 작고 빠른 모델 평가를 통해 정확도를 얻을 수 있음
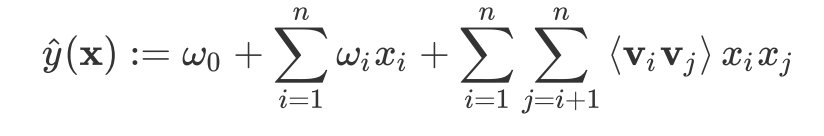
- deepCTR 라이브러리
ABSTRACT
- Factorization Machines(FM)은 2차 피쳐 상호작용을 통합하여 선형회귀 모델을 향상시키는 지도학습 방식
- FM은 모든 기능의 상호 작용이 똑같이 유용하고 예측력을 향상시키는 것이 아니므로 모든 기능의 상호 작용을 동일한 가중치로 모델링함으로써 성능에 방해될 수 있음
- 예를 들어 쓸모없는 기능과의 상호 작용은 노이즈를 발생시키고 성능을 저하시킬 수 있음
- 서로 다른 기능 상호작용의 중요성을 식별하여 FM 모델을 향상시킴
- 각각의 피쳐 상호작용의 중요성을 배우는 AFM(Attentional Factorization Machine)이라는 새로운 모델을 제안
- 신경망 네트워크를 통해 데이터로부터 2개의 실제 데이터 세트에 대한 광범위한 실험을 통해 AFM의 효율성을 입증했음. 경험적으로 AFM은 FM이 8.6%의 상대적 향상을 보였고, 최첨단 딥러닝 학습 방법인 Wide & Deep[Cheng et al., 2016]과 DeepCross[Shan et al., 2016]보다 훨씬 간단한 구조와 더 적은 모델 매개 변수를 제공
- AFM 구현은 https://github.com/hexiangnan/attentional_factorization_machine 에서 사용 가능
1. INTRODUCTION
- 지도학습은 기계학습(ML) 및 데이터마이닝의 기본 작업 중 하나. 목표는 예측변수(일명, 특징)를 입력으로 목표를 예측하는 함수를 추론하는 것 (추천시스템, 온라인 광고, 이미지 인식 등)
- 범주형 예측 변수에 대한 지도학습을 수행할 때는 변수들간에 상호 작용을 설명하는 것이 중요함
- 예를 들어, 1) 직업 = {은행가, 엔지니어, …}, 2) 레벨 = {junior, senior}, 3) 성별 = {남성 여성}, 3가지 카테고리 변수로 고객의 수입을 예측하는 toy 문제를 고려하기
- junior 뱅커는 junior 엔지니어보다 소득이 낮지만 senior 뱅커는 senior 엔지니어보다 소득이 높을 수 있음
- ML 모델이 예측변수 사이의 독립성을 가정하고 상호작용을 무시하면 각 피쳐의 가중치를 연결하는 선형 회귀와 같이 정확하게 예측할 수 없으며 모든 피쳐의 가중치 합으로 목표를 예측함
- 피쳐 간의 상호 작용을 활용하기 위한 하나의 공통된 해결책은 피연산자(교차 피쳐)로 벡터를 명시적으로 증가시키는 것
- 다차 회귀(PR)에서처럼 각 교차 피쳐의 가중치도 배웁니다.
- 그러나 PR (그리고 Wide & Deep [Cheng et al., 2016]의 넓은 구성 요소와 같은 다른 유사한 교차 embeeding 기반 솔루션)의 핵심 문제는 단지 몇 개의 교차 피쳐가 관찰되는 희소 데이터 세트의 경우, 관찰되지 않은 embeeding은 추정될 수 없음
- PR의 일반화 문제를 해결하기 위해 교차 피처의 가중치를 구성하여 피처 벡터들의 inner product으로 매개변수화 하는 인수분해 장치(FM)[Rendle, 2010]가 제안되었음
- FM이 동일한 가중치를 갖는 모든 인수 분해된 상호작용의 모델링에 의해 방해받을 수 있다고 주장.
- 실제 응용 프로그램에서 서로 다른 예측 변수는 일반적으로 예측력이 다르며 모든 기능에 이전 예제처럼 고객 수입을 예측하는 성별 변수와 같이 대상을 예측하는데 유용한 신호가 들어있는 것은 아님
- 덜 유용한 피쳐와의 상호작용은 예측에 덜 기여하므로 더 낮은 가중치를 할당해야 함
- 그럼에도 불구하고 FM은 기능 상호작용의 중요성을 차별화하는 기능이 부족하여 예측이 차선적일 수 있음
- 논문에서는 피쳐 상호작용의 중요성을 식별하여 FM을 향상시키는 AFM이라는 새로운 모델을 고안함
- 신경망 모델링에서 Attention Mechanism을 이용함. 특징 상호작용이 예측과 다르게 기여할 수 있게 함
- 중요한 것은 피쳐 인터랙션의 중요성이 사람의 도메인 지식 없이 데이터에서 자동으로 학습된다는 것
- 상황인식 예측과 개인화된 태그 추천이라는 두가지 공개 벤치마크 데이터 세트에 대한 실험을 수행함
- 폭넓은 실험을 통해 FM에 대한 관심이 두 가지 이점을 제공한다는 것을 보여주었습니다.
- 성능 향상뿐 아니라 기능 상호 작용이 예측에 더 많은 기여를 하는지에 대한 통찰력을 제공, FM의 해석 가능성과 투명성을 크게 향상시켜 behavior가 깊은 분석을 수행 할 수 있도록 함
2. Factorization Machines
- 지도학습을 위한 일반적인 ML 모델로서, 인수분해 기계는 원래 Collaborative Recommendation를 위해 제안되었음
- 실제 가치있는 특징 벡터 x ∈ Rn이 주어지면, n은 피처의 수를 나타내고, FM은 피처의 각 쌍 사이의 모든 상호 작용을 모델링하여 목표를 추정
- w0는 전역 바이어스이고, wi는 i번째 피쳐의 가중치이며, wij는 교차 특징 xixj의 가중치를 나타내며, wij = vTivj로 분해됨
- vi ∈ Rk는 특징 i에 대한 임베딩 벡터이고, k는 임베딩 벡터의 크기이다. 계수 xi xj로 인해, 0이 아닌 피처 간의 상호 작용만 고려됨
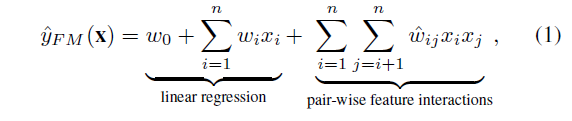
- FM 모델은 모두 동일한 방식으로 상호작용을 특징으로 한다는 점에 주목할 필요가 있음
- 첫째, 잠재적 벡터 vi는 i번째 기능이 포함하는 모든 기능 상호작용을 추정하는 데 공유됨
- 둘째, 추정된 모든 특징 상호작용(wij)은 같은 균일한 가중치를 갖음. 실제로, 모든 특징이 예측과 관련되는 것은 아님
- 예를 들어, “미국이 해외 지불 투명성에 주도적인 역할을 계속하고 있다”는 문장으로 뉴스 분류 문제를 생각해보십시오.
- “외국 지불 투명성” 이외의 단어는 (금융) 뉴스의 주제를 나타내는 것이 아니라는 것은 명백합니다. 관련없는 기능과 상호작용을 고려할 수 있습니다.
- 예측에 아무런 기여도 없는 Feature는 소음이지만 FM은 동일한 가중치로 가능한 모든 기능 상호작용을 모델링하므로 일반화 성능을 저하시킬 수 있음
3. Attentional Factorization Machines
3.1 Model
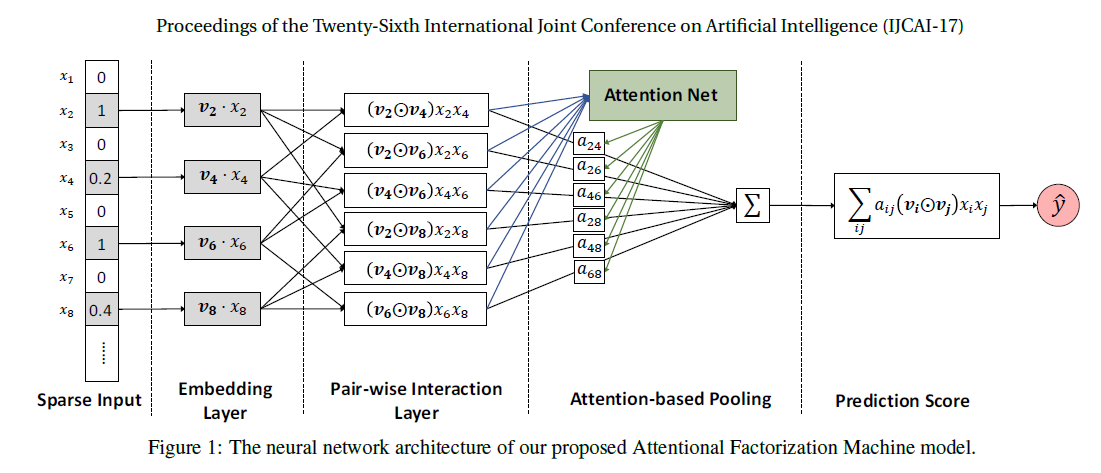
- 그림 1은 제안된 AFM 모델의 신경망 구조를 보여줍니다. 그림에서 선형 회귀 분석을 생략. 입력 레이어와 임베디드 레이어는 입력 피쳐에 대해 희소 표현을 채택하고 각각의 0이 아닌 피쳐를 고밀도 벡터에 포함시키는 FM과 동일합니다.
- 논문의 주된 부분인 pair-wise interaction layer와 attention-based pooling layer에 대해 자세히 설명합니다.
Pair-wise Interaction Layer
- inner product을 사용하여 각 피쳐 간 상호 작용을 모델링하는 FM에 영감을 받아 신경망 모델링에서 새로운 Pairwise Interaction Layer를 제안합니다.
- m 벡터를 m(m - 1)/2 상호 작용 벡터로 확장합니다. 각 상호 작용 벡터는 상호 작용을 인코딩하는 두 개의 별개 벡터의 요소 별 결과입니다.
- 형식적으로, 특징 벡터 x에서 0이 아닌 피처 집합을 X라고 하고, 임베디드 계층의 출력을 E = {vixi} i ∈ X 라고 하면, pair-wise interaction layer의 출력을 집합은 다음과 같음
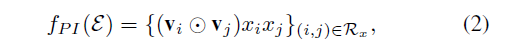
- 두 벡터의 element-wise 곱을 나타내며, pair-wise interaction layer를 정의함으로써 신경망 네트워크 구조 하에서 FM을 표현할 수 있음
- Sum Pooling을 사용하여 pair-wise 레이어를 압축한 다음 fully connected layer를 사용하여 예측 점수에 투영
- p와 b는 각 예측 레이어의 가중치와 바이어스를 나타냅니다. 확실히 p를 1로 고정하고 b를 0으로 설정하면 FM 모델을 정확하게 복구할 수 있습니다.
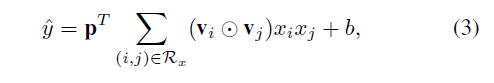
- 최근 신경망 FM의 연구는 Bilinear Interaction 풀링 연산를 제안했는데, pair-wise 상호작용 계층에서 sum 풀링을 사용하는 것으로 볼 수 있음
Attention-based Pooling Layer
- Attention Mechanism은 신경망 모델링에 도입되었기 때문에 추천, 정보 검색, 컴퓨터 시각에서 아이디어는 여러 부분을 단일 표현으로 압축할 때 다르게 기여하도록 허용하는 것입니다.
- FM 모델의 단점에 동기를 두어 상호작용 벡터에 대해 가중합을 수행하여 특징 상호작용에 Attention Mechansim을 적용할 것을 제안
- aij는 특징 상호 작용 wij에 대한 Attention 점수이며 wij는 다음을 예측하는 데 중요한 요소로 해석될 수 있음
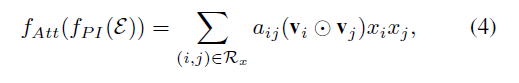
- 기술적으로 예측 손실을 최소화하여 직접 학습하는 직관적인 솔루션인 aij를 평가함
- 그러나 문제는 훈련 데이터에서 결코 공동 발생하지 않은 기능의 경우 상호작용의 Attention 점수를 예측할 수 없다는 것
- 일반화 문제를 해결하기 위해 Attention Network 에서 MLP (multi-layer perceptron)를 사용하여 Attention 점수를 매개 변수화 함
- Attention Network에 대한 입력은 상호작용 정보를 포함하여 영역에 인코딩하는 두 가지 기능의 상호 작용 벡터입니다.
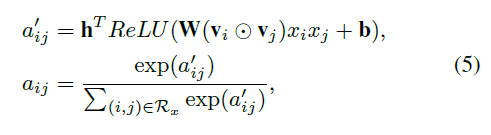
- 공식적으로, Attention Network는 다음과 같이 정의
- t(모델 파라미터)는 Attention Network의 숨겨진 계층 크기를 나타냅니다. Attention 점수는 softmax 기능을 통해 정상화됩니다.
- rectifier 함수를 활성화 기능으로 사용함 (경험적으로 좋은 성능을 보여줌)
- Attention 기반 풀링 계층의 출력은 k차원 벡터
- Attention 벡터는 중요도를 구분하여 임베딩 공간에서 모든 피쳐 상호 작용을 압축하여 다음 이를 예측 점수에 투영함
- 요약하면, 우리는 AFM 모델의 전체 공식을 다음과 같이 제시
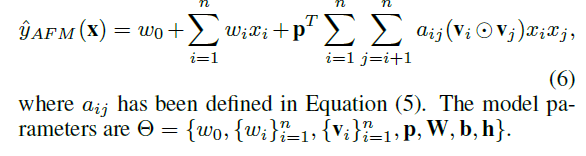
3.2 Learning
- AFM은 데이터 모델링의 관점에서 FM을 직접 강화하므로 회귀분석, 분류 및 순위 지정 등 다양한 예측 작업에도 적용할 수 있음
- 다른 목적(분류/회귀/…)을 위해서는 AFM 모델 학습하려면 다른 목적 함수가 사용되어야 함
- 목표 y(x)가 실수 값인 회귀작업의 경우 목적 함수는 제곱된 손실(squared loss)입니다. 여기서 T는 학습 인스턴스 집합을 나타냅니다.
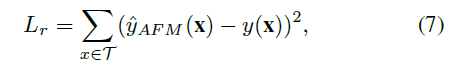
- implicit feedback에 의한 바이너리 분류 또는 추천 모델링을 위해 로그 손실을 최소화 할 수 있음. 논문에서는 회귀 분석에 중점을 두고 제곱 손실을 최적화
- 목적 함수를 최적화하기 위해 우리는 Stochastic Gradient Descent(SGD) - 신경망 모델을 위한 범용 해법을 사용합니다.
- SGD 알고리즘을 구현하는 핵심은 예측 모델 yAFM (x) w.r.t의 미분을 얻는 것
- 딥러닝을 위한 대부분의 최신 툴킷이 Theano 및 TensorFlow와 같은 라이브러리에서 automatic differentiation 기능을 제공하므로 여기에서 세부 정보는 생략
Overfitting Prevention
- 오버피팅은 ML 모델을 최적화 할 때 영구적인 문제. FM은 overfitting에 시달릴 수 있음
- L2 정규화는 FM에 대한 overfitting를 방지하는 필수 요소
- AFM은 FM보다 표현력이 강하기 때문에 훈련 데이터를 너무 많이 맞추는 것이 더 쉬움. overfitting (dropout 및 L2 regularization)을 방지하는 두 가지 기술을 고려했음
- dropout의 개념은 훈련 중 일부 신경망을 (연결에 따라) 무작위로 떨어뜨리는것
- dropout은 훈련 데이터에 대한 뉴런의 복잡한 동시 적응을 예방할 수 있는 것으로 나타났음
- AFM은 모든 상호 작용이 유용하지는 않지만 피쳐 간의 모든 pair-wise 상호 작용을 모델링하기 때문에 pair-wise 상호 작용 계층의 뉴런은 서로 쉽게 상호 적응하여 overfitting 을 초래할 수 있음
- 공동 적응을 피하기 위해 pair-wise 상호 작용 계층에서 dropout을 사용
- 또한 dropout은 테스트 및 전체 네트워크가 예측에 사용되는 경우 dropout은 잠재적으로 성능을 향상시킬 수 있는 더 작은 신경망으로 모델 평균을 수행하는 또 다른 부작용을 가지고 있음
- 하나의 계층 MLP인 네트워크 구성 요소에 대해 가능한 오버피팅을 방지하기 위해 가중치 행렬 W에 L2 정규화를 적용함. 즉, 우리가 최적화하는 실제 목적 함수는 다음과 같음
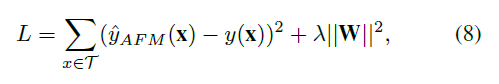
- λ는 정규화 강도를 제어함. Attention 네트워크에서 드롭아웃을 사용하지 않음
- 상호작용 레이어와 Attention 네트워크에서 드롭아웃을 공동으로 사용하면 안정성 문제가 발생하고 성능이 저하됨
4. Related Work
- FM 모델은 주로 스파스 한 상황에 있는 지도학습에 사용됨
- 예를 들어 범주형 변수가 one-hot 인코딩을 통해 스파스 특성 벡터로 변환되는 상황에서
- 이미지와 오디오에서 발견되는 연속적인 원시 기능과는 달리 웹 도메인의 입력 기능은 대부분 이산되고 범주화되어 있음
- 희소한 데이터를 이용한 예측을 위해, 피쳐 간의 상호 작용을 모델링하는 것이 중요
- 두 개체 사이의 상호 작용을 모델링하는 행렬인수 분해(MF)와는 달리 FM은 여러 엔터티 간의 상호 작용을 모델링하기 위한 일반적인 기계학습으로 설계되어있음
- 입력 특징 벡터를 지정함으로써 FM이 MF, SVD++와 같은 많은 특정 인수분해 모델을 포함할 수 있음을 보여줍니다.
- FM은 희소 데이터 예측을 위한 가장 효과적인 선형 방법으로 인식되고 있습니다.
- 고차원 기능을 상호 작용을 학습하기 위해 신경망 프레임 워크에서 FM을 깊게하는 Neural FM과 field-aware FM과 같은 FM에 대한 많은 변형이 제안되었음
- 피쳐에 대한 여러 임베딩 벡터를 연결하여 다른 필드의 다른 피쳐와의 상호 작용을 구분함. 피쳐 상호 작용의 중요성을 식별하여 FM 개선에 기여함
- 우리의 제안과 유사한 작업을 알고 있습니다
- GBFM : 그래디언트 부스팅으로 “좋은” 기능을 선택하고 좋은 기능 사이의 상호 작용만 모델링함. 선택한 기능 간의 상호 작용을 위해 GBFM은 FM과 동일한 가중치로 요약합니다. 따라서 GBFM은 본질적으로 기능 선택 알고리즘입니다. 이 알고리즘은 각 기능 상호 작용의 중요성을 알 수 있는 AFM과 근본적으로 다릅니다.
- 다른 라인을 따라, 딥러닝 네트워크가 점점 인기를 얻고 있으며 최근에 스파스 설정 하에서 예측에 사용되었음
- 구체적으로, Wide & Deep for App 모델이 제안되었음. Deep 구성 요소는 특징 상호 작용을 학습하기 위해 특징 embedding 벡터의 연결에 대한 MLP, 크로스 - 피쳐를 배우기 위해 residual units 을 이용한 DeepCross가 제안되기도 함
- 여러가지 방법들에서, 피쳐 인터랙션은 암묵적으로 각각의 상호 작용을 명시적으로 두개의 피쳐의 inner product로 모델링하는 FM보다는 딥러닝 신경망에 의해 캡쳐됩니다.
- 각 기능 상호 작용의 기여도를 알 수 없으므로 해석할 수 없음
- 각 기능 상호작용의 중요성을 배우는 Attnetion 메커니즘으로 FM을 직접 확장하면 AMF가 더 해석 가능하고 경험적으로 Wide & Deep 및 DeepCross보다 우수한 성능을 보여줌
5. Experiments
- 다음 질문에 답하기 위해 실험을 수행합니다.
RQ1. AFM의 핵심 하이퍼 매개 변수 (즉, 기능 상호작용 및 Attention 네트워크의 정규화)가 성능에 미치는 영향은 무엇입니까?
RQ2. Attention 네트워크가 피쳐 상호작용의 중요성을 효과적으로 배울수 있습니까?
RQ3. 스파스 데이터 예측을 위한 최첨단 방법에 비해 AFM은 어떻게 작동합니까?
5.1 Experimental Settings
Datasets
- 두 개의 공용 데이터 세트를 사용하여 실험을 수행함
- Frappe 및 MovieLens2
- Frappe 데이터 세트는 다양한 상황에서 사용자의 앱 사용 로그가 96 개, 203개 포함된 context-aware recommendation에 사용되었음
- 8 개의 컨텍스트 변수는 날씨, 도시, 주간 등을 포함하여 범주 형입니다.
- 각 로그 (사용자 ID, 앱 ID 및 컨텍스트 변수)를 원핫 인코딩을 통해 피쳐 벡터로 변환하여 5,382개의 피쳐를 얻습니다.
- MovieLens 데이터는 영화에 사용자의 668,953 태그 응용 프로그램을 포함하는 개인화 된 태그 권장 사항에 사용되었습니다.
- 우리는 각 태그 어플리케이션 (사용자 ID, 영화 ID 및 태그)을 특성 벡터로 변환하고 90, 445개 기능을 얻을 수 있습니다.
Evaluation Protocol
- 두 데이터 세트의 경우 각 로그에는 값 1의 대상이 지정됩니다.
- 즉 사용자가 컨텍스트에서 응용 프로그램을 사용했거나 영화에 태그를 적용했음을 의미합니다.
- 우리는 무작위로 두개의 음의 샘플을 각 로그와 쌍을 이루고 대상을 -1로 설정합니다.
- 따라서 Frappe 및 MovieLens의 최종 실험 데이터에는 각각 288, 609 및 2,006,859 인스턴스가 포함됩니다.
- 각 데이터 세트를 무작위로 세 부분으로 나눕니다 : 훈련 데이터 70 %, 유효성 검사 20 %, 테스트 10 %.
- 유효성 검사 집합은 하이퍼 매개 변수 조정에만 사용되며 성능 비교는 테스트 집합에서 수행됩니다.
-
성능을 평가하는데 더 낮은 점수가 더 나은 성능을 나타내는 RMSE (root mean square error)를 채택합니다. (베이스 라인)
- AFM을 스파스 데이터 예측을 위해 설계된 다음과 같은 경쟁 방식과 비교합니다.
- LibFM : FM에 대한 공식 C ++ 구현. 다른 방법은 모두 SGD (또는 그 변형)에 의해 최적화되므로 SGD 학습자를 선택합니다.
- HOFM : 고차원 FM의 TensorFlow 구현, MovieLens 데이터는 세 가지 유형의 예측 변수 (사용자, 항목 및 태그) 만 가지기 때문에 주문 크기를 3으로 설정했습니다.
- Wide & Deep : 해당 방법을 구현. Deep 신경망의 구조 (예를 들어, 각 층의 깊이 및 크기)가 완전히 조정되기 어렵기 때문에, 우리는 논문에서보고 된 것과 동일한 구조를 사용한다. 넓은 부분은 FM의 선형 회귀 부분과 동일하며 심층 부분은 레이어 크기가 1024, 512 및 256 인 3 레이어 MLP입니다.
- DeepCross : Original paper와 동일한 구조, 숨겨진 차원 512, 512, 256, 128, 64 / 5 개의 residual units (각 단위는 두 개의 계층을 가짐)를 쌓음
- 공정한 비교를 위해 제곱된 손실을 최적화하여 모든 모델을 학습
- LibFM 외에도 모든 방법은 미니 배치 Adagrad에 의해 학습
- Frappe 및 MovieLens의 배치 크기는 각각 128 및 4096으로 설정
- 모든 메서드에 대해 embedding size 가 256으로 설정, Attention factor도 256 크기
- LibFM과 HOFM의 L2 정규화와 Wide & Deep 및 DeepCross의 드롭 아웃 비율을 조심스럽게 조정했습니다.
- Early stopping strategy은 유효성 검증 세트의 성능을 기준으로 사용됨
- Wide & Deep, DeepCross 및 AFM의 경우 FM을 사용하여 피쳐 embeddings을 사전 교육하면 무작위 초기화보다 RMSE가 낮아집니다. 따라서 pre-training 을 통해 퍼포먼스를 리포팅 함
5.2. Hyper-parameter Investigation (RQ1)
- 먼저, pair-wise 상호작용 계층에 대한 dropout의 영향을 조사
- λ를 0으로 설정하여 L2 정규화가 Attention 네트워크에 사용되지 않도록 함
- 또한 AFM의 Attention 구성 요소를 제거하여 FM 구현에 대한 dropout을 검증합니다
- 그림 2는 AFM 및 FM w.r.t의 유효성 검증 오류를 보여줍니다. 다른 드롭아웃 비율; LibFM의 결과는 또한 벤치마크로 표시됩니다.
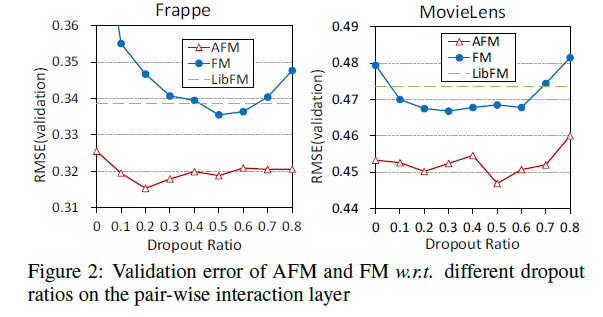
- dropout 비율을 적절한 값으로 설정하면 AFM과 FM을 크게 향상시킬 수 있습니다.
- 특히 AFM의 경우 Frappe 및 MovieLens의 최적 드롭아웃 비율은 각각 0.2와 0.5.
- FM과 AFM의 일반화를 향상시키는 pair-wise interaction layer에서의 dropout의 유용성을 검증
- FM 구현은 LibFM보다 우수한 성능을 제공함. 이유는 두 가지.
- 첫째, LibFM은 모든 매개변수에 대해 고정학습 속도를 채택하는 바닐라 SGD를 사용하여 최적화합니다.
- 우리는 Adagrad를 통해 FM을 최적화합니다. Adagrad는 빈도에 따라 각 매개 변수의 학습 속도를 조정합니다 (즉, 빈번한 간헐적인 매개 변수에 대한 더 큰 업데이트).
- 둘째, LibFM은 L2 정규화를 통한 오버피팅을 방지하는 반면, 모델 평균화 효과를 볼 수 있는 드롭아웃을 사용
- 첫째, LibFM은 모든 매개변수에 대해 고정학습 속도를 채택하는 바닐라 SGD를 사용하여 최적화합니다.
- AFM은 FM과 LibFM보다 큰 성능을 발휘합니다.
- 드롭 아웃을 사용하지 않고 overfitting 문제가 어느정도 존재하더라도 AFM은 LibFM 및 FM의 최적 성능보다 훨씬 우수한 성능을 제공합니다 (드롭 아웃비율 0의 결과)
- 기능 상호 작용의 중요성을 학습할 때 Attention 네트워크의 이점을 보여줍니다.
- Attention 네트워크 상의 L2 정규화가 AFM에 유익한 지 여부를 연구함
- dropout 비율은 이전 실험에서 입증된 것처럼 각 데이터 세트에 대해 최적값으로 설정됨
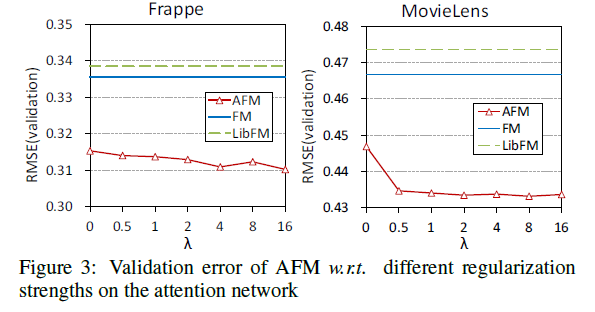
- 그림 3에서 알 수 있듯이 λ를 0보다 큰 값으로 설정하면 AFM이 향상됩니다 (λ = 0의 결과는 그림 2에서 AFM으로 얻은 최상의 성능에 해당함)
- 단순히 쌍방향 상호작용 층에 드롭아웃을 사용하는 것이 AFM의 overfitting을 방지하기에 불충분하다는 것을 의미
- 더 중요한 것은 Attention 네트워크를 조정하면 AFM의 일반화를 더욱 향상시킬 수 있다는 것
5-3. Impact of the Attention Network (RQ2)
- Attention 네트워크가 AFM에 미치는 영향을 분석하는데 초점을 맞춤. 대답할 첫번째 질문은 적절한 주의력 요소를 선택하는 방법
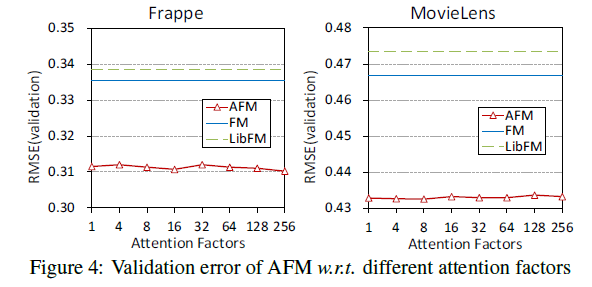
- 그림 4는 AFM w.r.t의 유효성 검사 에러를 보여줍니다.
- 다른 Attention 요인. λ는 각 주의력 요소에 대해 개별적으로 조정되었습니다.
- 두 데이터 세트 모두 AFM의 성능은 관심 요소 전반에 걸쳐 안정적이라는 것을 알 수 있습니다.
- 구체적으로, Attention 요인이 1일 때, W 행렬은 벡터가 되고 Attention 네트워크는 본질적으로 상호작용 벡터 (즉, vivj)를 입력 특징으로 하는 선형 회귀 모델로 저하됨
- 상호작용 벡터를 기반으로 형상 상호 작용의 중요도 점수를 평가하는 AFM 설계의 합리성을 정당화합니다.
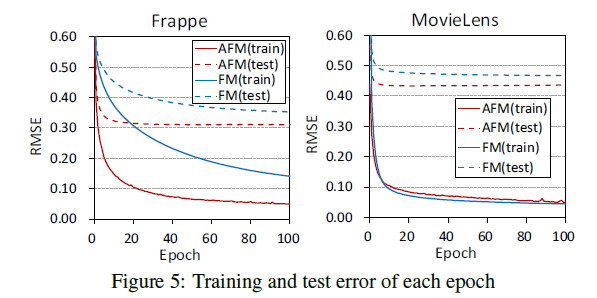
- 그림 5는 각 Epoch 별로 AFM과 FM의 훈련 및 테스트 오류를 비교합니다.
- AFM이 FM보다 빠르게 수렴한다는 것을 관찰합니다.
- Frappe의 경우 AFM의 훈련 및 테스트 오류가 모두 FM보다 낮으므로 AFM이 데이터를 잘 맞추고 보다 정확한 예측을 유도합니다.
- MovieLens에서 AFM은 FM보다 약간 높은 훈련 에러를 달성하지만 AFM이 보이지 않는 데이터보다 잘 일반화되어 있음을 보여주는 테스트 에러가 더 낮습니다.
Micro-level Analysis
- 향상된 성능 외에도 AFM의 또 다른 주요 이점은 각 기능 상호 작용의 Attention 점수를 해석하여 설명이 가능하다는 것
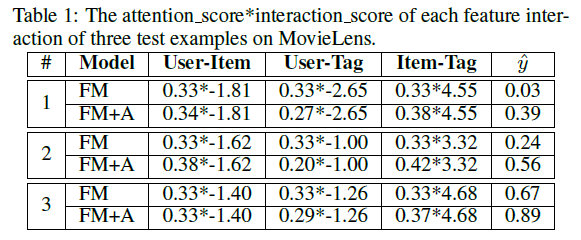
- MovieLens에서 각 피쳐 상호작용의 점수를 조사하여 몇 가지 미시적 수준의 분석을 수행합니다.
- Attention 네트워크에 대한 분석을 허용하기 위해 먼저 aij를 균일 한 숫자 1 / Rx로 수정하여 FM을 시뮬레이션 하는 모델을 학습
- 다음 feature embeddings을 수정하고 Attention 네트워크만 훈련합니다.
- 컨버전스가 발생하면 성능이 약 3% 향상되어 Attention 네트워크의 효율성을 정당화합니다.
- 다음 표 1의 각 기능 상호작용의 Attention 점수와 상호작용 점수를 보여주는 목표값 1의 세 가지 테스트 예제를 선택합니다.
- 세 가지 상호 작용 중에서 항목- 태그 상호 작용이 가장 중요하다는 것을 알 수 있습니다.
- 그러나 FM은 모든 상호 작용에 대해 동일한 중요도 점수를 할당하므로 큰 예측 에러가 발생합니다.
- Attention 네트워크 (참조 행 FM + A)로 FM을 보강함으로써 항목 - 태그 상호 작용에 더 높은 중요도 점수가 할당되고 예측 에러가 감소됩니다.
5.4. Performance Comparison (RQ3)
- 마지막 단원에서는 테스트 세트에서 여러 메서드의 성능을 비교합니다.
-
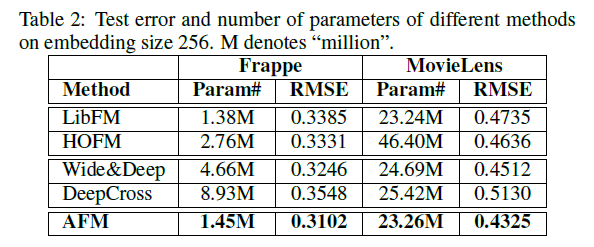
표 2는 크기 256을 embedding 할 때 얻은 최상의 성능과 각 방법의 학습 가능한 매개 변수의 수를 요약합니다.
- 첫째, AFM이 모든 방법 중에서 최상의 성능을 달성하는 것을 볼 수 있습니다.
- 특히, AFM은 0.1M 미만의 추가 매개 변수를 사용하여 상대적 향상이 8.6%인 LibFM을 개선합니다.
- AFM은 더 적은 모델 파라미터를 사용하면서 4.3%의 두 번째로 좋은 방법인 Wide & Deep을 능가합니다.
- 얕은 모델임에도 불구하고 Deep한 학습 방법보다 우수한 성능을 제공하는 AFM의 효율성을 보여줍니다.
- 둘째, HOFM은 고차원 피쳐 상호 작용의 모델링에 기인하는 FM보다 향상됩니다.
- 그러나 HOFM은 각 order의 기능 상호 작용을 모델링하기 위해 별도의 임베딩 세트를 사용하기 때문에 매개변수의 수를 거의 두 배로 늘리는 다소 비싼 비용을 기반으로 약간의 개선이 이루어졌습니다.
- 향후 연구의 방향을 제시하며 고차원 형상 상호 작용을 포착하기 위한 보다 효과적인 방법을 고안합니다.
- 마지막으로, DeepCross는 과도한 overfitting 문제로 인해 최악의 상황을 처리합니다
- DeepCross의 드롭아웃은 일괄 정규화 사용으로 인해 발생할 수 있습니다.
- DeepCross가 모든 비교된 방법 중에서 가장 Deep한 방법 (임베디드 레이어 위에 10 개의 레이어를 쌓음)을 고려할 때, 심층 네트워크가 과잉으로 인해 어려움을 겪을 수 있고 실제로 최적화하기가 더 어렵기 때문에 깊은 기울기가 항상 도움이 되지 않는다는 증거를 제공합니다
6. Conclusion and Future Work
- 지도 학습을 위한 간단하면서도 효과적인 모델 AFM을 제시했습니다.
- AFM은 Attention 네트워크와 기능 상호작용의 중요성을 학습함으로써 FM을 향상시킵니다.
- Attention은 모델의 성능 향상뿐만 아니라 FM 모델의 해석 가능성을 향상시킵니다.
-
연구는 고차원의 특징 상호 작용을 모델링하기 위한 FM의 깊은 변형을 개발한 Neural FM에 대한 최근 연구와 직결되며, 인수 분해 기계에 Attention 메커니즘을 도입하는 시기
- 앞으로는 Attention-based 풀링 레이어 위에 여러 개의 비선형 레이어를 쌓아 성능을 더욱 향상시킬 수 있는지 여부를 확인하여 AFM의 심층 버전을 살펴 보겠습니다.
- AFM은 0이 아닌 피처의 수에 비해 비교적 2차의 복잡성을 가지기 때문에,
- 예를 들어 해시 학습을 사용하여 학습 효율을 향상시킬 것을 고려할 것 (데이터 샘플링 기술을 포함)
- 폭넓게 사용되는 그래프인 Laplacian을 통합하여 semi-supervised 및 multi-view 학습을 위한 FM 변형을 개발하는 것이 유망한 방향이 될 것이다




댓글남기기