
참고자료
- Follow-the-Regularized-Leader and Mirror Descent: Equivalence Theorems and L1 Regularization
- 오늘 리뷰할 논문은 Ad Click Prediction: a View from the Trenches 입니다.
- 광고 클릭 예측 문제에서 FTRL 적용 : https://static.googleusercontent.com/media/research.google.com/ko//pubs/archive/41159.pdf
- FTRL Python Starter Code
- FTRL R Code
- 카카오AI리포트 - 광고 알고리즘 소개
ABSTRACT
- 예상 광고 클릭률(CTR)은 수십억 달러 규모의 온라인 광고 산업의 중심. 대규모 학습으로 얻어진 CTR 예측 시스템의 설정에 관한 최근의 실험을 통해 얻어진 사례 연구 및 주제를 제시합니다.
- FTRL-Proximal 온라인 학습 알고리즘 (희소성 및 수렴 특성이 우수함) 및 에 Per-coordinate learning rate에 기반한 기존 Supervised Learning의 맥락에서의 개선이 포함
- 전통적인 기계학습 연구의 영역. 메모리 절약을 위한 유용한 기법(트릭), 성능을 평가하고 시각화하는 방법, 예상 확률에 대한 신뢰도 추정을 제공하는 실제 방법, 보정 방법 및 기능의 자동 관리 방법이 포함됩니다.
- 마지막으로, 다른 곳에서도 유망한 결과를 얻었음에도 불구하고 우리에게 유익하지 못한 몇 가지 지시 사항을 자세히 설명합니다.
- 산업 환경에서 이론적 진보와 실제 현장에서의 공학 간의 밀접한 관계를 강조하고 복잡한 동적 시스템에서 전통적인 기계학습 방법을 적용 할 때 나타나는 문제의 깊이를 보여주기 위한 것
1. INTRODUCTION
- 온라인 광고 분야는 수십억 달러 규모의 업계입니다. 온라인 광고에서 모델은 기계에 대한 위대한 성공 사례 중 하나 역할을 했습니다.
- 스폰서 검색 광고, 문맥 광고, 디스플레이 광고 및 실시간 입찰 경매 모두는 학습된 모델이 광고 클릭률을 정확하고 신속하며 안정적으로 예측할 수 있는 능력에 크게 의존했습니다.
- 10 년 전만 하더라도 상상할 수 없었던 규모의 문제를 다루기 위해 이 분야들이 발생
- 전형적인 산업 모델의 상응하는 큰 특징 공간 (Feature Space)**을 사용하여 하루에 수십억 개의 사건에 대한 예측을 제공 할 수 있으며 그 결과 데이터의 많은 양으로부터 학습 할 수 있습니다.
- 본 백서에서는 스폰서 검색 광고에 대한 광고 클릭률을 예측하기 위해 Google에서 사용되어 배포된 시스템의 설정에 대한 최근의 실험을 바탕으로 일련의 사례 연구를 제시합니다.
- 따라서 우리는 효과적인 학습 알고리즘을 설계하는 문제에 전통적으로 주어지는 것과 동일한 엄격함으로 메모리 절약, 성능 분석, 예측에 대한 confidence, 보정(calibration) 및 기능 관리 문제를 탐구합니다.
- 이 백서의 목표는 실제 산업 환경에서 발생하는 문제의 깊이에 대한 인식을 제공하고 다른 대규모 문제 영역에 적용될 수 있는 트릭과 통찰력을 공유하는 것입니다.
2. BRIEF SYSTEM OVERVIEW
- 사용자가 검색 q를 할 때, 초기 후보 집합은 광고는 광고주가 선택한 키워드를 기반으로 하는 쿼리 q와 일치합니다.
- 그런 다음 경매 메커니즘은 이러한 광고가 사용자에게 표시 되는지, 표시되는 순서 및 광고 클릭 시 광고주가 지불하는 가격을 결정합니다.
- 광고 입찰에 더하여, 경매에 대한 중요한 입력은 각 광고 a에 대해 P(Click | query, advertiser) 의 추정치, 광고가 표시될 때 클릭 될 확률입니다.
- Google 시스템에서 사용되는 기능은 검색어, 광고 문안 및 다양한 광고 관련 메타 데이터를 비롯한 다양한 출처에서 가져옵니다.
- 데이터는 극단적으로 희박한 경향이 있으며, 일반적으로… only a tiny fraction of nonzero feature values per example.
- 정규화된 로지스틱 회귀와 같은 방법이 자연적으로 문제 설정에 적합합니다. 하루에 수십억 번 예측을 해야하고 새로운 클릭 및 비-클릭이 관찰될 때 모델을 신속하게 업데이트 해야 합니다.
-
훈련을 받은 모델은 많은 데이터 센터에 복제되어 있기 때문에 (그림 1 참조) 훈련 기간이 아닌 서빙 시간의 Sparse 형태에 훨씬 더 관심이 있습니다
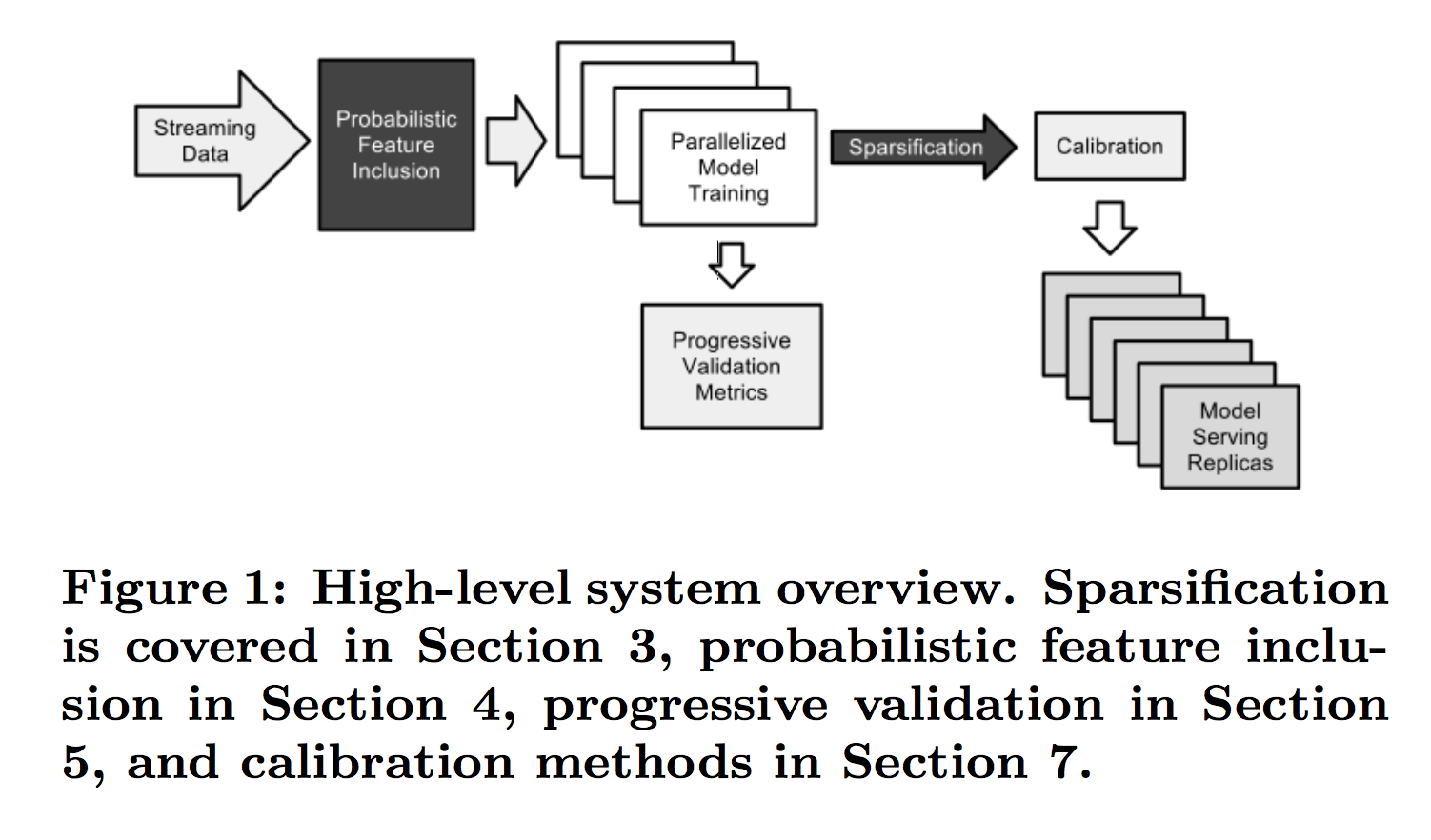
- 물론 이 데이터 전송률은 훈련 데이터 세트가 엄청나다는 것을 의미합니다. 데이터는 Photon 시스템을 기반으로 하는 스트리밍 서비스에 의해 제공됩니다. 자세한 내용은 [2] 논문을 참조하십시오.
- 대규모 학습은 매우 잘 연구되어 왔기 때문에 최근 몇 년 동안 (예를 들어, [3] 참조) 우리는 이 논문에서 우리의 시스템 아키텍처를 상세하게 설명하는 데 많은 공간을 투자하지 않았습니다.
-
그러나 훈련 방법은 Google Brain 팀에서 설명한 Downpour SGD 방법과 유사하지만 많은 계층의 네트워크가 아닌 단일 계층 모델을 훈련 한다는 차이점이 있습니다. Downpour SGD: Downpour SGD는 DistBelif라는 구글의 모델, 데이터 병렬화 학습 모델에서 소개된 방법이다. 간단히 말하면 여러 개로 모델을 쪼개어, 여러 개의 머신에서 동시에 학습을 하는데 이 때 여러 모델들에서 계산된 gradient를 평균내서 각각의 모델에 적용하는 방법이다. 이렇게 해도 충분히 전체 데이터와 모델에 대한 근사적인 학습이 가능하다고 하다. http://static.googleusercontent.com/media/research.google.com/ko//archive/large_deep_networks_nips2012.pdf 출처: http://newsight.tistory.com/224 [New Sight]
- 수십억 개의 계수를 사용하여 우리가 알고있는 다른 곳에서 보고 된 것보다 훨씬 더 큰 데이터 세트와 큰 모델을 처리 할 수 있습니다.
3. ONLINE LEARNING AND SPARSITY
- 거대한 규모로 학습하기 위해, 일반 선형 모델 (예 : 로지스틱 회귀)을 위한 온라인 알고리즘은 많은 장점을 가지고 있습니다.
- 특성 벡터 x에는 수십억 개의 dimension이 있을 수 있지만 일반적으로 각 인스턴스에는 0이 아닌 값이 수백 개만 있습니다.
- 이렇게 하면 디스크 또는 네트워크에서 예제를 스트리밍하여 대용량 데이터 세트를 효율적으로 학습 할 수 있습니다. 각 훈련 사례는 한 번만 고려하면 됩니다.
- 로지스틱 회귀를 사용하여 문제를 모델링 하고자 한다면 다음 온라인 프레임 워크를 따릅니다.
- 벡터 gt의 i 번째 항목은 gt, i로 표시
- 라운드 t에서, 우리는 특징 벡터 xt ∈ Rd에 의해 기술된 예를 예측할 것을 요구받았음
- pt = σ (wt · xt)를 예측한다. 여기서 σ (a) = 1 / (1 + exp (-a))는 시그 모이드 함수이다. 그런 다음 레이블 yt ∈ {0, 1}을 관찰하고 결과 LogLoss
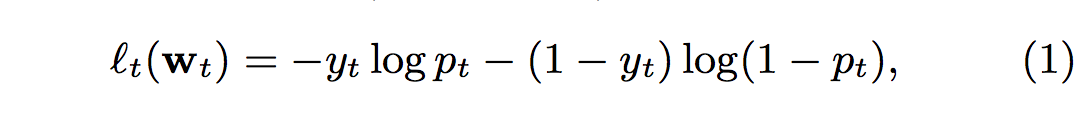
- 가중치 w 벡터를 얻어내기 위하여 일반적으로 negative log-likelihood loss 함수를 계산하고, 해당 손실함수는 볼록성을 띄기 때문에 보통 최적화 문제로 기울기(gradient) 기반의 최적화 방식으로 해결함
-
Stochastic gradient descent는 이러한 종류의 문제에 대해 매우 효과적이며, 최소한의 컴퓨팅 리소스로 뛰어난 예측 정확도를 제공합니다.
SGD (Stochastic Gradeint Descent): SGD는 Gradient Descent가 갖는 너무 큰 계산량 문제를 해결하기 위해 전체 데이터중에서 랜덤하게 추출한 1/N의 데이터만을 사용해 훨씬 더 빠르게, 자주 업데이트하는 방법이다. 이 때 추출한 1/N의 데이터를 Minibatch라고 부르며, 이 데이터가 전체 데이터의 분포를 따라야만 제대로 된 학습이 가능하다. 만약 이 데이터가 전체 데이터의 분포를 따르지 않고, 계속 분포가 바뀌는 non-stationary한 경우를 online learning이라고도 부른다. 전체 데이터를 잘 섞어서, 너무 작지 않은 크기로 N 등분하면, 계산량이 1/N 배가되어, 빠르게 Weight를 업데이트할 수 있어, 이론상 N배 더 빠른 학습이 가능하다. 추후 SGD에서 각 Minibatch 분포가 매번 약간씩 달라지는 noise를 internal covariate shift라고 부르며, 이를 해결하기 위한 방법으로 batch-normalization이 등장한다. 출처: http://newsight.tistory.com/224 [New Sight]
- 그러나 실제로 또 다른 주요 고려 사항은 최종 모델의 크기입니다. 모델이 희박(sparsely)하게 저장 될 수 있기 때문에 w의 0이 아닌 계수의 수는 메모리 사용의 결정 요인이다.
- 불행하게도, SGD 모델은 Sparse한 데이터의 모델을 계산할 때 특히 효과적이지 않습니다.
-
손실의 그라디언트에 L1 페널티의 하위 그라디언트를 추가하는 것만으로도 일부 해결 되었습니다. Forward-Backward Splitting(FOBOS)과 같이 절단된 그래디언트와 같은 보다 정교한 접근법은 희소성을 도입하는 데 성공합니다.
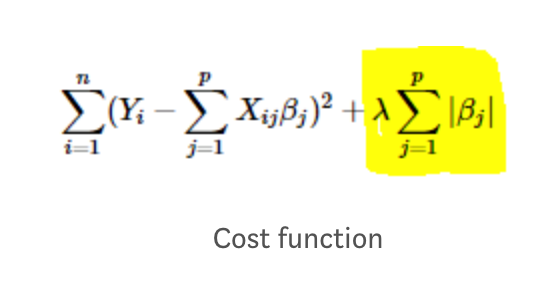
- Lasso (L1 “absolute value of magnitude” of coefficient as penalty term to the loss function.)
- Regularized Dual Averaging (RDA) 알고리즘은 FOBOS보다 더 나은 정확도와 희소성 절충점을 생성합니다.
- 그러나 gradient-descent style methods 이 우리의 데이터 세트에서 RDA보다 더 나은 정확도를 생성 할 수 있음을 관찰했습니다.
- 따라서 문제는 RDA가 제공하는 희소성과 SGD의 정확성을 모두 얻을 수 있는가 해결하고 싶은 것
- 대답은 “예, Follow The (Proximally) Regularized Leader algorithm, or FTRL-Proximal. Without regularization”
- 정규화가 없으면 이 알고리즘은 표준 SGD와 동일하지만 모델 계수 w를 다른 게으른 표현으로 사용하기 때문에 L1 정규화를 훨씬 효과적으로 구현할 수 있습니다
FTRL
 )
)
- FTRL Proximal == Online Gradient Descent(OGD) + Regularized Dual Averaging(RDA)
-
첫 번째 term g1:t 는 the gradient part, 이전 샘플 1~t에 대한 그래디언트 합계. (해당 샘플에서 가설의 손실을 줄이면 그 방향으로 이동)
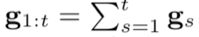
- FTL(follow the leader)를 표현한 것으로, t 시간까지 가장 작은 손실을 갖도록 한 leader(gradient)들을 취해서 손실의 근사치를 구한다.
- 두 번째 term은 근접화 부분 (proximal strong convexity)
- 새로운 가중치가 이전에 사용했던 가중치들에서 큰 변동이 없도록 제약하는 근접치(proximal) 파트다.
- 이런 강한 볼록성(convexity)을 추가함으로써 알고리듬의 안정성을 높인다.
-
**세 번째 term은 정규화 부분 (기존의 l1 norm, lasso)**
- FTRL Proximal은 서브그레디언트(subgradient)의 궤적을 쫓으며 근사한 손실을 최소화하고 규칙화와 근접치를 통해서 모델의 급격한 변동성을 막는 안정된 모델을 구축한다.
- 온라인 최적화 방식이 모든 학습 데이터로 한꺼번에 계산하는 배치(batch) 방식보다 정확도는 다소 낮을 수 밖에 없다.
- 그럼에도 빠른 학습/업데이트 시간과 최소 리그렛 바운드(regret bound)를 보장하는 최적화 방법 중에 FTRL-Proximal이 현재의 최신기술(state-of-the-art, SOTA)
- 온라인 학습 방식을 사용하는 것은 최근 데이터로 교체하기 위해서
(모델의 새로움(freshness)을 유지하는 것이 중요하다. 즉, 하루 이틀동안 학습한 모델을 일주일, 한달동안 계속 사용할 수가 없고, 수분에서 1시간 주기로 새로운 데이터로 모델을 계속 업데이트해줘야 한다)
-
- learning rate 스케줄의 관점에서 σs를 정의한다
- learning rate :
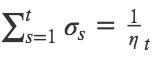
- learning rate :
- 표면적으로, 이러한 업데이트는 매우 다르게 보이지만 실제로 λ1 = 0을 취하면 identical sequence of coefficient vectors가 생성됩니다.
- 그러나 λ1> 0 인 FTRL-Proximal 업데이트는 희소성을 유발하는 훌륭한 작업입니다 (아래 실험 결과 참조)
- 빠른 검사에서 FTRL-Proximal 업데이트가 그라디언트 디센트보다 구현하기가 어렵거나 모든 과거 계수를 저장해야 한다고 생각할 수 있습니다.
- 그러나 실제로 계수 당 하나의 숫자만 저장하면 됩니다. ( re-write the update as the argmin over w ∈ R d )
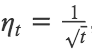
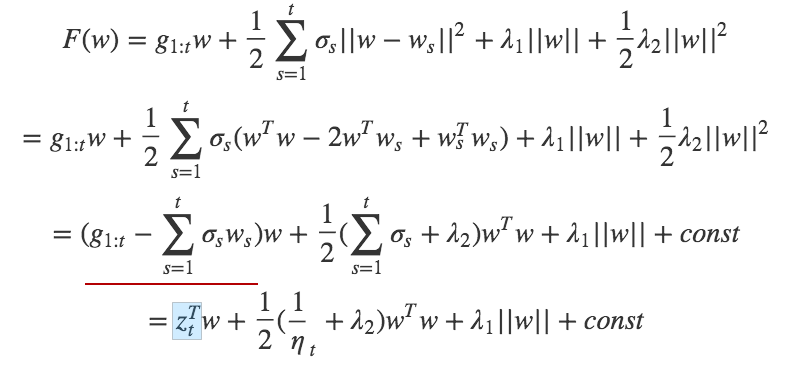

- FTRL-Proximal 함수를 w에 대해서 최소화 하기 위해서 미분하면 wt + 1, i에 대해 per coordinate base에서 closed 형태로 풀면
- Per-coordinate learning rate
- 서로 다른 좌표에 대해 동일한 학습 속도를 사용하면 안된다는 것입니다. 미분 크기에 따라 달라지기 때문에 일부 좌표는 많은 값이 0을 가질 수 있습니다. (자세한 부분은 다음 부분에서 설명)
- Per-parameter adaptive learning rates (Adagrad, RMSprop, Adam)**
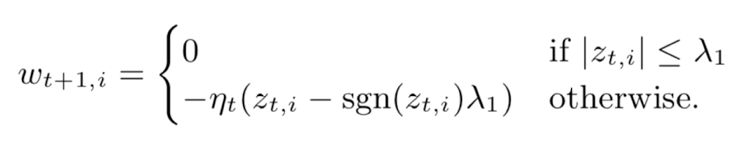
- Per-coordinate learning rate
Experimental Results.

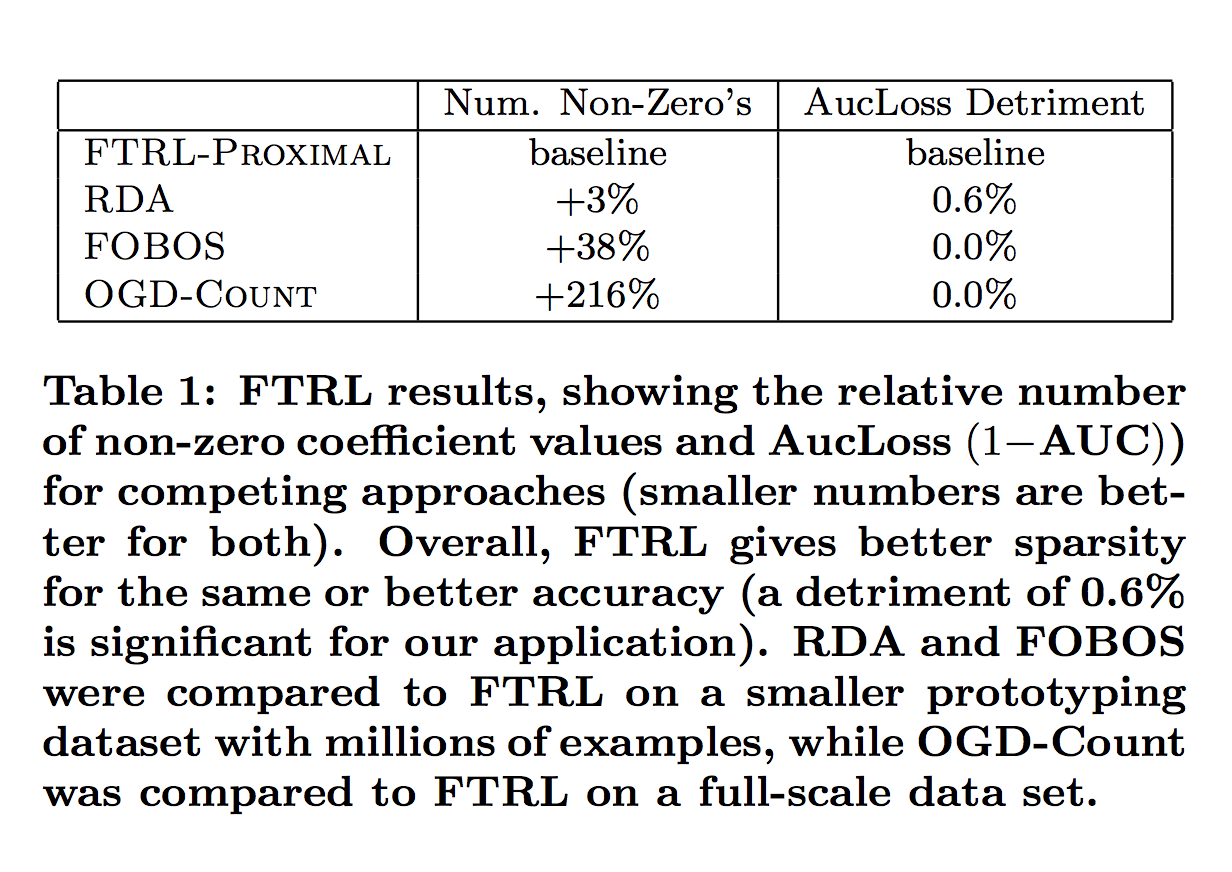
- 간단한 휴리스틱에 대해 FTRL-Proximal을 테스트하기 위해 매우 큰 데이터 세트를 실행했습니다.
- 전반적으로 결과는 FTRL- 근사값이 같거나 그보다 나은 예측 정확도로 현저하게 개선 된 희박성을 제공함을 보여줍니다
- L1 정규화가 적용된 FTRL-Proximal이 크기 대 정확도의 절충 면에서 RDA와 FOBOS를 크게 능가하는 것으로 나타났습니다.
Per-Coordinate Learning Rates.
- 온라인 그래디언트 디센트에 대한 표준 이론은 global하게 learning rate의 스케줄를 사용하는 것을 제안합니다, 이것은 모든 좌표에 공통적인 것
- 로지스틱 회귀를 사용하여 10 개의 동전에 대해
Pr(heads | coin i)을 추정한다고 가정 해보십시오.- 각의 라운드 t, 코인 i는 뒤집혔고, 특징 벡터 R10을 본다. 따라서 우리는 본질적으로 하나의 문제로 포장된 10 개의 독립적인 로지스틱 회귀 문제를 풀고있다.
- 우리는 온라인 그라디언트의 10 개의 독립 사본을 실행할 수 있습니다
- 여기서, 문제 i에 대한 알고리즘 인스턴스는 위 그림과 같은 학습률을 사용합니다.
- nt, i는 동전 i가 지금까지 뒤집혔던 횟수입니다. 동전 i가 동전 j보다 훨씬 자주 뒤집힌다면, 동전 i의 학습 속도는 더 빨리 감소 할 것이며, 우리는 더 많은 데이터를 가지고 있음을 반영합니다.
- 우리는 현재 추정치에 대한 확신이 낮기 때문에 학습률은 동전 j에 대해 높게 유지 될 것이므로 새로운 데이터에서 보다 신속하게 반응해야합니다.
- 다른 한편, 우리가 이것을 하나의 학습으로 본다면 표준 학습 속도 스케줄 t는 모든 좌표에 적용됩니다.
- 즉, 동전 i가 뒤집히지 않을 때 동전 i의 학습률을 줄입니다. (학습률이 줄어든다는 의미는 거의 변화가 없다는 것?)
- gs, i는 그래디언트의 i 번째 좌표입니다. 좌표가 특정 의미에서 거의 최적이라고 나타납니다, 좋은 성능을 내기 위해 α와 β를 선택하는 학습 속도를 사용합니다.
- α의 최적값은 피처와 데이터 세트에 따라 적절한 비트가 다를 수 있으며 일반적으로 β = 1이면 충분합니다. 이것은 단순히 초기 학습 속도가 너무 높지 않도록 보장합니다.
- 상대적으로 간단한 좌표 - 당 학습률의 분석은 작은 Google 데이터 세트에 대한 실험 결과 뿐만 아니라 다른 곳에도 나타납니다.
- 실험 결과. 두 개의 동일한 모델을 하나의 글로벌 학습 속도로 테스트하고 per coordinate 학습 속도를 사용하여 테스트함으로써 percoordinate 학습 속도의 영향을 평가했습니다.
- 기본 파라미터 α는 각 모델에 대해 개별적으로 조정되었습니다. 대표적인 데이터 세트를 실행하고 AucLoss를 평가 척도로 사용했습니다 (5 절 참조).
- 결과에 따르면 좌표 별 학습률을 사용하면 global 학습 속도 기준에 비해 AucLoss가 11.2 % 감소했습니다. 이 결과를 컨텍스트에 적용하려면 AucLoss를 1 % 줄이면 큰 것으로 간주됩니다.
4. SAVING MEMORY AT MASSIVE SCALE
- 위에서 설명한 것처럼 L1 정규화를 사용하여 예측 시간에 메모리를 절약합니다. 이 섹션에서는 트레이닝 중에 메모리를 절약하기 위한 추가 트릭을 설명합니다.
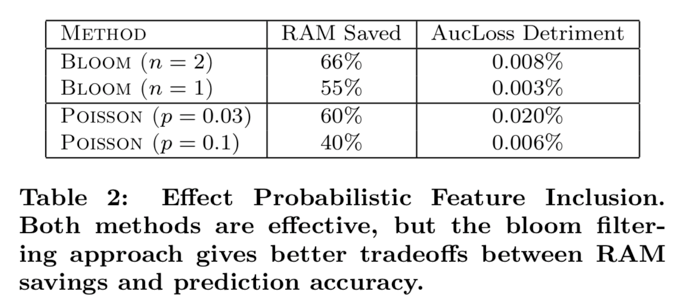
4.1 Probabilistic Feature Inclusion
- 높은 차원의 데이터를 가진 많은 영역에서 기능의 대부분은 매우 드뭅니다. 사실, 일부 모델에서는 고유한 기능의 절반이 수십억 가지의 예제의 전체 훈련 세트에서 한 번만 발생합니다 .
- 불행히도 우리는 어떤 기능이 드문 일인지 미리 알지 못합니다. 드문 형상을 제거하기 위해 데이터를 사전 처리하는 것은 온라인 설정에서 문제가 됩니다.
- 데이터의 추가 읽기 및 쓰기는 비용이 많이 들며 일부 기능이 삭제되면 (예 : k 번 미만으로 발생 함) 이러한 기능을 사용하는 모델을 더 이상 정밀도 측면에서 전처리 비용을 예측하는 데 사용할 수 없습니다.
- 방법은..
- 제로 계수를 갖는 특징에 대한 임의의 통계를 추적 할 필요가 없는 L1 정규화의 구현을 통해 훈련에서 희소성을 달성한다.
- 훈련이 진행됨에 따라 유익하지 않은 기능을 제거 할 수 있습니다. 그러나 우리는 이러한 희소성의 유형이 훈련에서 더 많은 기능을 추적하고 서빙에 대해서만 Sparse하는 방법 (FTRL- 근사법)과 비교할 때 정확성의 손실을 초래한다는 것을 발견했습니다.
- 이 문제에 대한 또 다른 일반적인 해결책인 hashing with collisions 역시 유용한 이점을 제공하지 못했습니다 (9.1절)
- 우리가 탐구한 또 다른 방법은 확률론적 피쳐 포함으로, 새로운 피쳐가 처음 발생할 때 모델에 확률적으로 포함됩니다. 이렇게 하면 데이터를 사전 처리하는 효과를 얻을 수 있지만 온라인 설정에서 실행할 수 있어야 합니다.
- Poisson Inclusion
- New feature are inserted with probability p
- 모델에 아직 존재하지 않는 특징을 만날 때, 그것을 확률 p로 모델에만 추가합니다.
- 피쳐가 추가되면 이후의 관측에서 SGD에서 사용하는 계수 값 및 관련 통계를 평소와 같이 업데이트합니다. 형상을 모델에 추가하기 전에 형상을 볼 필요가 있는 횟수는 예상 값 1/p geometric distribution 를 따릅니다.
- Bloom Filter Inclusion
- Once a feature has occurred more than n times (according to the filter), we add it to the model
- 블룸 필터 [4,12]를 계산하는 롤링 세트를 사용하여 훈련에서 특징이 발생한 첫 번째 n 시간을 탐지합니다. 피쳐가 필터에 따라 n 번 이상 발생하면 이를 모델에 추가하고 위와 같은 후속 관측에서 훈련에 사용합니다.
- 계수 블룸 필터는 오탐지 (false negative)가 가능하기 때문에 이 방법 또한 확률적. 즉, 실제로 n 번 미만으로 발생한 기능을 포함합니다.

4.2 Encoding Values with Fewer Bits
- SGD의 순진한 구현은 32 또는 64 비트 부동 소수점 인코딩을 사용하여 계수 값을 저장합니다. 부동 소수점 인코딩은 종종 동적 범위가 넓고 세밀한 정밀도 때문에 매력적이지만..
- 그러나 우리의 정규화 된 로지스틱 회귀 모델의 계수에 대해 이것은 과잉이라고 판명됩니다, 거의 모든 계수 값은 범위 (-2, +2) 내에 있습니다.
- 분석 결과 세밀한 정밀도도 필요하지 않다는 것을 보여 주며, 부동 소수점 대신 fixed-point q2.13 encoding 인코딩의 사용을 탐구하도록 동기를 부여합니다.
- q2.13 인코딩에서 우리는 두 비트를2 진 소수점, 2 진 소수점 오른쪽에 13 비트, 부호 당 하나의 비트 (값 당 총 16 비트 사용)가 있습니다.
- 정밀도가 낮으면 SGD 설정에서 누적된 반올림 오류로 인해 많은 수의 작은 단계가 누적되어야 하는 문제가 발생할 수 있습니다. (사실 64 비트가 아닌 32 비트 부동 소수점을 사용하는 심각한 라운드 오프 문제조차도 보았습니다.)
-
그러나 단순한 무작위 라운딩 전략은 작은 추가 regret term [14]를 사용하여 이를 수정합니다. 핵심은 명시적으로 반올림하여 이산화 오류가 제로 평균임을 보장 할 수 있다는 것입니다.
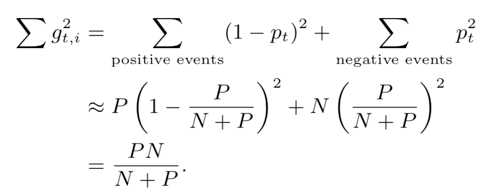
- 실험 결과. 실제로 64 비트 부동 소수점 값 대신 q2.13 인코딩을 사용하는 모델의 결과를 비교할 때 측정 가능한 손실은 없으며 계수 저장을 위해 RAM의 75 %를 절약함
4.3 Training Many Similar Models
- 하이퍼 파라미터 설정이나 기능에 대한 변경을 테스트 할 때 한 가지 형식의 많은 변형을 평가하는 것이 유용합니다. 일반적인 유스 케이스는 효율적인 훈련 전략을 허용한다.
- 이전 모델로 고정 된 모델을 사용하여 residual 오류에 대해 변형을 평가할 수있었습니다. 이 방법은 매우 저렴하지만 기능 삭제 또는 대체 학습 설정 평가를 쉽게 허용하지 않습니다.
- 주요 접근 방식은 각 좌표가 모델 변형을 통해 효율적으로 공유 할 수 있는 일부 데이터에 의존하는 반면 다른 데이터 (계수 값 자체와 같은)는 각 모델 변형에 고유하며 공유 할 수 없다는 관찰에 의존합니다.
- 모델 계수를 해시 테이블에 저장하면 모든 변형에 대해 하나의 테이블을 사용하여 키 저장 비용 (문자열 또는 여러 바이트 해시)을 상환 할 수 있습니다.
- 다음 섹션 (4.5)에서는 모델 별 학습률 카운터 ni를 모든 변형에 의해 공유되는 통계로 대체 할 수있는 방법을 보여 주며 저장 공간도 줄입니다.
- 특정 기능이 없는 변형은 해당 기능의 계수를 0으로 저장 하므로 적은 공간을 낭비합니다. (우리는 이러한 기능에 대한 학습 속도를 0으로 설정하여 이를 시행합니다.)
- 매우 유사한 모델만 함께 학습하기 때문에 키와 모델 당 카운트를 나타내지 않기 때문에 메모리를 절약하는 것이 공통적이지 않은 기능의 손실보다 훨씬 큽니다
4.4 A Single Value Structure
- 때로는 매우 큰 세트의 모델을 평가하기를 원합니다. 작은 그룹의 기능을 추가하거나 제거 할 때만 다른 변형이 함께 나타납니다. 여기서 우리는 더 많은 압축 된 데이터 구조를 사용할 수 있습니다. 이 데이터 구조는 손실이 많으며 특별합니다. 그러나 실제로는 매우 유용한 결과를 제공합니다.
- This Single Value Structure stores just one coefficient value for each coordinate which is shared by all model variants that include that feature, rather than storing separate coefficient values for each model variant.
- 비트 필드는 주어진 모델을 포함하는 모델 변형을 추적하는 데 사용됩니다.
4.5 Computing Learning Rates with Counts
- As presented in Section 3.1 에 나왔듯이 그레디언트를 저장할 필요가 있음 (each feature both sum of the gradients and the sum of the squares of the gradients.)
- 그래디언트 계산이 정확해야 하지만 학습 속도 계산을 위해 근사가 이루어져야 합니다.
- Suppose that all events containing a given feature have the same probability
- 모델이 확률을 정확하게 배웠다고 가정 해보십시오. N 개의 음의 사건과 P 개의 양의 사건이 있는 경우 확률은 p = P / (N + P)이다.
- 로지스틱 회귀 분석을 사용하면, P(positive)의 이벤트에 대한 기울기는 p - 1이고 음(negative)의 이벤트에 대한 기울기는 p이며
- 해당 근사법은 카운트 (N and P)만 추적하고, and dispense with storing
저장하는 것을 배제할 수 있음
- 해당 프레임 워크를 사용하면 모든 변형 모델의 수가 동일하므로 총 저장 비용이 낮으므로 N 및 P의 저장 비용이 감소됩니다.
- 카운트는 가변 길이의 비트 인코딩으로 저장할 수 있으며 대다수의 기능에는 많은 비트가 필요하지 않습니다.
4.6 Subsampling Training Data
- 일반적인 CTR은 50 % 보다 훨씬 낮습니다.긍정적인 예 (클릭 수)는 비교적 드뭅니다.
- 간단한 통계 계산을 통해 CTR 견적을 학습 할 때 클릭 수가 상대적으로 더 중요함을 나타냅니다. 정확성에 미치는 영향을 최소화하면서 훈련 데이터 크기를 크게 줄이기 위해 이 기능을 활용할 수 있습니다.
- 샘플에 포함시켜 서브 샘플링 된 학습 데이터를 만듭니다. (Any query for which at least one of the ads was clicked)
-
A fraction r ∈ (0, 1] of the queries where none of the ads were clicked.
- 서브 샘플링 된 데이터에 대한 순진한 훈련은 상당히 편향된 예측으로 이어질 것입니다. 이 문제는 각 예제에 중요도 가중치 ωt를 할당함으로써 쉽게 해결됩니다.

- 샘플링 분포를 제어하기 때문에 일반적인 샘플 선택에서와 같이 가중치 ω를 추정 할 필요가 없습니다. 중요도 가중치는 각 이벤트의 손실을 단순하게 확장합니다 (Eq. (1), 따라서 그라데이션을 조정합니다. 이것이 의도 한 효과를 가지는지 보기 위해
- 샘플링되지 않은 데이터에서 무작위로 선택된 이벤트 t가 서브 샘플링 된 목적 함수에 기대되는 기여도
- 샘플링 될 확률 (1 또는 r)을 st라고 하고 (1/wt)
- 기대의 선형성은 서브 샘플링 된 훈련 데이터의 예상 가중치가 원래의 데이터 세트의 목표 함수와 같음을 의미합니다.
- 실험을 통해 클릭되지 않은 쿼리의 상당히 적극적인 하위 샘플링조차도 정확도에 미치는 영향은 미미하며 예측 성능은 r의 특정 값에 특별히 영향을 받지 않는다는 점을 확인했습니다.
- 샘플링 될 확률 (1 또는 r)을 st라고 하고 (1/wt)
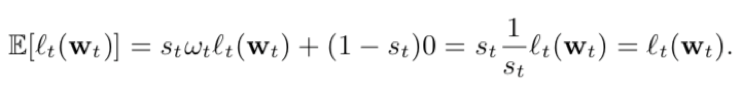
5. EVALUATING MODEL PERFORMANCE
- 가능한 여러 실적 측정 항목에 대한 모델 변경 사항을 평가하는 것이 일반적으로 유용하다는 것을 알게되었습니다. (변경 방식에 따라서 달라서)
- AucLoss (즉, AUC는 ROC 곡선 메트릭 [13]에서 표준 영역 인 1-AUC), LogLoss (SqaredError) 및 SquaredError와 같은 메트릭을 계산합니다. 일관성을 위해 메트릭을 설계하여 값이 작을수록 항상 좋습니다.
5.1 Progressive Validation
- 일반적으로 a held out dataset에 대한 교차 유효성 검사 또는 평가보다는 progressive validation (sometimes called online loss)를 사용합니다.
- 학습을 위한 그래디언트 컴퓨팅은 어쨌든 예측을 계산해야 하기 때문에 우리는 후속 분석을 위해 이러한 예측을 저렴하게 스트리밍하여 매시간 집계 할 수 있습니다. 또한 국가 별 분석, 쿼리 주제 및 레이아웃과 같은 다양한 하위 데이터 조각에 대해 이러한 측정 항목을 계산합니다.
- 온라인 손실은 Google에서 훈련하기 전에 가장 최근 데이터의 실적 만 측정하기 때문에 검색어 게재에 있어 Google의 정확성에 대한 좋은 대명사입니다. 모델에서 검색어를 제공 할 때와 매우 유사합니다.
- 온라인 손실은 훈련 및 테스트 모두에 대해 100 %의 데이터를 사용할 수 있기 때문에 a held out dataset 세트보다 상당히 우수한 통계를 제공합니다. 작은 개선이 규모에 의미있는 영향을 미칠 수 있고 높은 신뢰도로 많은 양의 데이터를 관찰해야하기 때문에 이것은 중요합니다
- 절대 메트릭 값은 오도 된 경우가 많습니다. 예측이 완벽하더라도 LogLoss 및 기타 메트릭은 문제의 어려움 (즉, 베이즈 위험)에 따라 다릅니다. 클릭률이 50 %에 가까울수록 클릭률이 2 %에 가까울 때보다 LogLoss가 가장 높습니다.
- 클릭률은 국가마다 다르므로 중요합니다.
- because click rates vary from country to country and from query to query, and therefore the averages change over the course of a single day
- 따라서 항상 상대적인 변화를 관찰합니다. 일반적으로 기준 모델과 관련하여 메트릭의 백분율 변화로 표현됩니다. 상대적인 변화는 시간이 지남에 따라 훨씬 더 안정적입니다.
- 또한 정확히 동일한 데이터에서 계산된 메트릭을 비교하는 데만 주의를 기울입니다.
- 예를 들어, 하나의 시간 범위에 걸친 모델에서 계산 된 손실 메트릭은 다른 시간 범위에 걸친 다른 모델에서 계산 된 동일한 손실 메트릭과 비교할 수 없습니다.
5.2 Deep Understanding through Visualization
- 막대한 규모의 학습에서 잠재적인 함정 중 하나는 집계된 성과 척도가 데이터의 특정 하위 집단에 특정한 영향을 숨길 수 있다는 것입니다.
- 예를 들어 특정 메트릭에 대한 작은 집계 정확도가 실제로는 별개 국가 또는 특정 쿼리 항목에 대한 긍정적인 변화와 부정적 변화가 혼합되어 발생합니다.
- 따라서 집계 데이터 뿐만 아니라 국가 별 또는 주제별로 데이터의 다양한 부분에 대한 성능 메트릭을 제공하는 것이 중요합니다.
- 의미있는 방식으로 데이터를 조각 낼 수있는 방법은 수백 가지가 있기 때문에 데이터의 시각적 요약을 효과적으로 검토 할 수 있어야합니다.
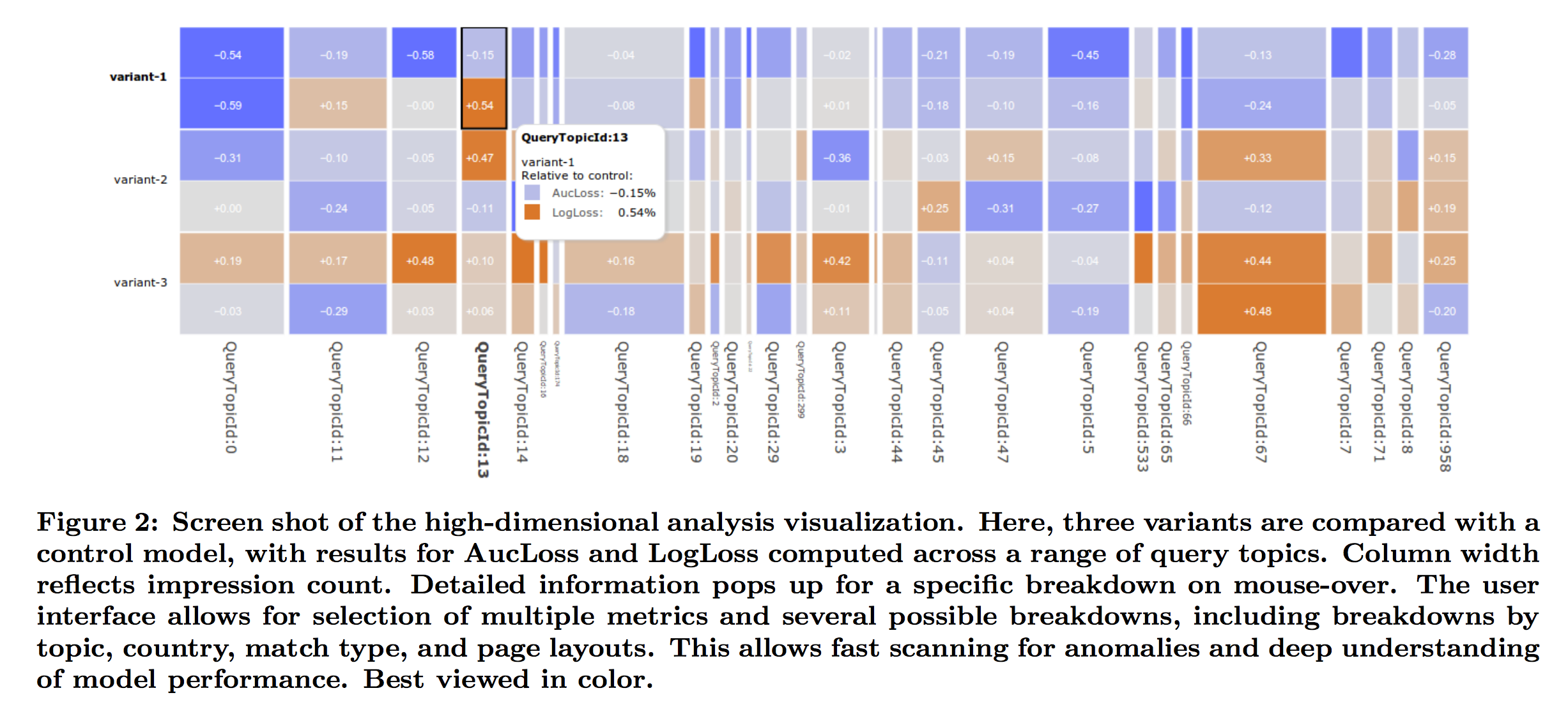
- 모델 성능에 대한 포괄적인 이해를 가능하게하는 GridViz라고 하는 고차원적 대화형 시각화를 개발했습니다.
- GridViz의 한 화면보기가 그림 2에 나와 있으며, 컨트롤 모델과 비교하여 두 모델에 대한 쿼리 항목별로 일련의 조각을 보여줍니다.
- 메트릭 값은 유색 셀로 표시되며 모델 이름에 해당하는 행과 데이터의 각 고유 슬라이스에 해당하는 열이 표시됩니다. 열 폭은 슬라이싱의 중요성을 의미하며, 열 너비가 노출 수 또는 클릭 수와 같은 양을 반영하도록 설정 될 수 있습니다.
- 셀의 색은 선택한 기준선과 비교한 메트릭 값을 반영하므로 전체 성능에 대한 시각적인 이해 뿐만 아니라 특이치 및 관심 영역에 대한 빠른 검색이 가능합니다.
6. CONFIDENCE ESTIMATES
- 많은 어플리케이션에서, 광고의 CTR 뿐만 아니라 예측의 예상 정확도를 정량화 할 수 있음, 더 적은 데이터에서도 예측 시스템에서는 광고를 표시해야 하고 제어할 수 있어야함 (explore/exploit tradeoff)
- 신뢰 구간은 불확실성의 개념을 포착 하며, 그러나 실용적이고 통계적인 이유로 인해, 우리의 시스템에서는 신뢰 구간을 적용 하는 것이 부적합함
- 표준적인 모델에서 사용할 수 있는 방법은 정규화(Lasso)가 없는 fully-converged 배치 모델의 예측 신뢰도를 평가하는 것이 일반적입니다.
- 우리가 제시하는 모델은 온라인이며, IID(independent and identically distributed) 데이터를 가정하지 않고 정규화가 되어 있고 또한, 신뢰 추정치가 매우 싸게 계산 될 수 있음
-
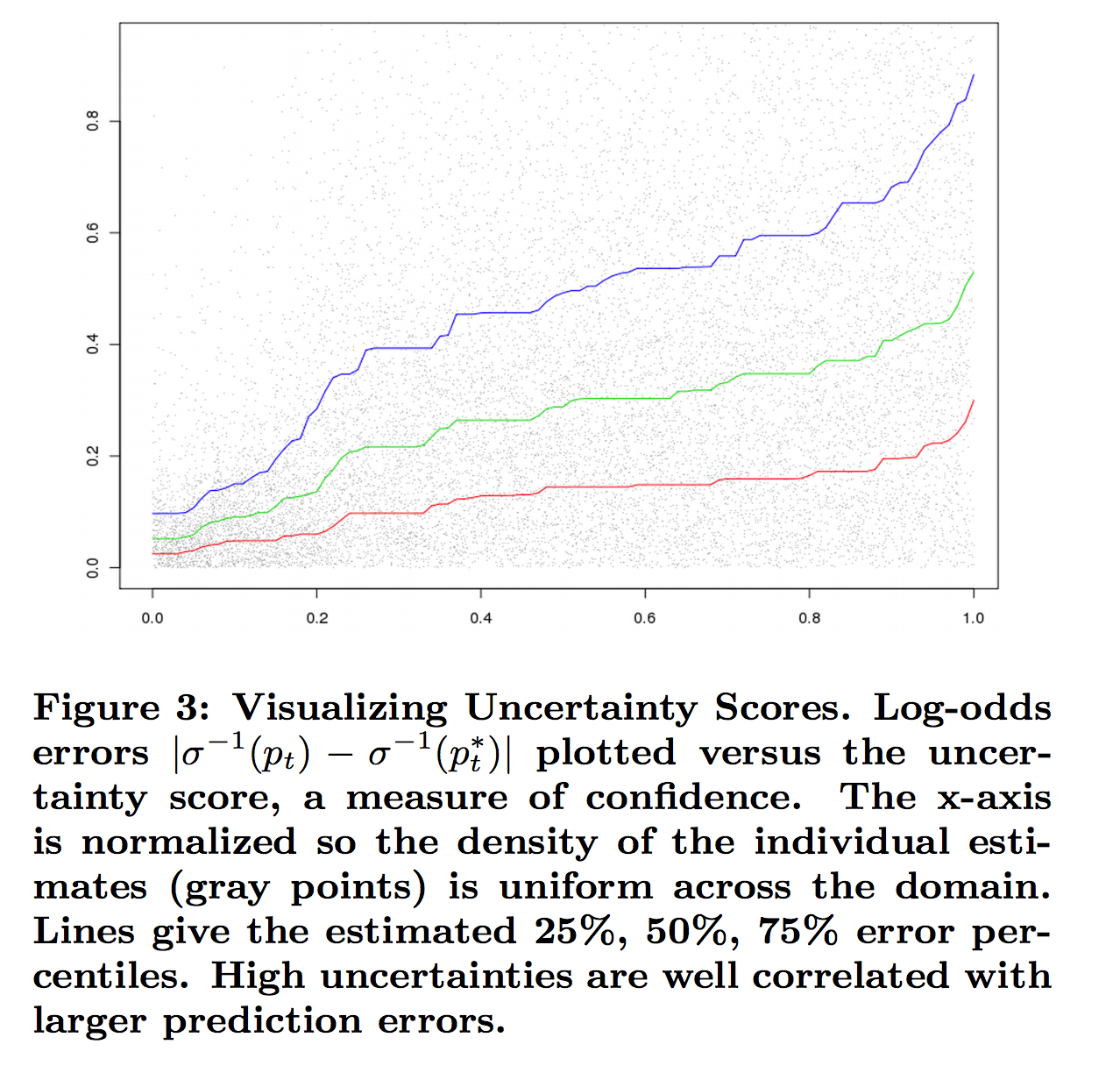
불확실성 점수라고 부르는 heuristic 방법을 제안한다. 이것은 계산적으로 다루기 쉽고 경험적으로 예측 정확도를 정량화하는 일을 하는 부분

- The essential observation is that the learning algorithm itself maintains a notion of uncertainty in the per-feature counters n t,i used for learning rate control
- ni가 큰 특징은 현재 계수 값이 정확할 확률이 더 높기 때문에 학습률이 낮아집니다. log-odds 점수에 대한 로지스틱 손실의 기울기는 (pt - yt)이므로 절대 값은 1로 제한됩니다.
- 따라서 특성 벡터가
| xt, i | ≤ 1이면, 단일 훈련 예 (x, y)를 관찰함으로써 log-odds prediction의 변화를 제한 할 수 있습니다. 단순화를 위해 λ1 = λ2 = 0을 고려하면 FTRL- 근사는 SGD랑 동치
- 실제 데이터에서 “ground truth (실측 차료)”모델을 훈련 했지만 평소보다 약간 다른 기능을 사용했습니다.
- 1. 실제 클릭 레이블을 삭제하고 True CTR으로 ground truth 모델의 예측을 가져와서 새 레이블을 샘플링했습니다.
- 신뢰 절차의 타당성을 평가할 때 true 라벨을 알아야 하므로 필요함
- 2. FTRL-Proximal을 실행하여 re-labeled data를 얻은 다음에 log-odds 공간에서 예측의 정확성을 비교함 (et)
- Log-odds error가 et, 여기서 p*t는 True CTR 값 (Ground Truth Model / 실측자료 모델)
- 1. 실제 클릭 레이블을 삭제하고 True CTR으로 ground truth 모델의 예측을 가져와서 새 레이블을 샘플링했습니다.
-
그림 3은 불확실성 스코어는 large 예측 에러와 높은 상관 관계가 있습니다.
- 추가 실험을 통해 불확실성 점수는 평가 체계에서 비교할 수 있게 수행되어 32 개 모델의 부트스트랩을 통해 얻은 훨씬 더 비싼 추정치가 데이터의 무작위 하위 샘플에 대해 훈련 된 것으로 나타났습니다.
7. CALIBRATING PREDICTIONS
- 정확하고 잘 보정(calibration) 된 예측은 경매를 실행하는 데 필수적일 뿐만 아니라 경매에서 최적화에 대한 기계 학습에서 분리하는 느슨하게 결합된 전체 시스템 설계를 허용합니다.
- 체계적 편향 (일부 데이터 조각에 대한 예측 예측 및 관측 클릭률 (CTR)의 차이)가 발생하는 이유
- 부정확한 모델링 가정, 학습 알고리즘의 결함 또는 훈련 및 / 또는 검색에서 사용할 수 없는 숨겨진 기능과 같은 다양한 요소로 인해 발생할 수 있습니다
체계적 편향 예측 편향은 두 평균이 서로 얼마나 멀리 떨어져 있는지 측정하는 수량입니다. 즉, 다음과 같습니다.
예측 편향 = 예측 평균 - 이 데이터 세트의 라벨 평균
- 평균적으로 전체 이메일의 1%가 스팸이라고 예를 들어 보겠습니다. 어떤 이메일에 대해 전혀 모르는 경우 메일의 1%는 스팸일 수 있다고 예측해야 합니다.
- 마찬가지로 적절한 스팸 모델은 이메일의 1%가 스팸일 수 있다고 평균적으로 예측해야 합니다.
- 다시 말해서 각 이메일이 스팸으로 예측될 가능성의 평균을 내면 결과는 1%여야 합니다. 그런데 모델이 스팸 가능성을 평균 20%로 예측한다면 예측 편향을 드러내는 것으로 결론을 내릴 수 있습니다. !!
- 문제를 해결하기 위해 별개로 Calibration 레이어를 사용하여 예상 클릭률을 관측된 클릭률과 일치시킬 수 있습니다.
- 예측은 데이터 조각에 대해 조정됩니다. p를 예측할 때 평균적으로 실제 관찰된 CTR이 p에 가까울 경우. 보정 함수 τ (p) = γp^κ 를 적용하여 보정을 향상시킬 수 있습니다.
- p는 예측된 CTR이고 d는 학습 데이터의 partition 요소입니다.
- 성공의 정의는 데이터의 가능한 다양한 파티션에 대해 잘 보정 된 예측을 제공하는 것으로 정의합니다. τ 를 모델링하는 간단한 방법은 함수에 τ (p) = γp^κ를 맞추는 것
- 포아송 회귀를 사용하여 γ와 κ를 집합 데이터에 대해 배울 수 있습니다.
- 바이어스 곡선에서 더 복잡한 모양을 처리 할 수 있는 좀 더 일반적인 접근법은 조각별 선형 또는 조각별 상수 교정 기능을 사용하는 것입니다. 유일한 제한은 매핑 함수 τ가 isotonic (단조 증가) 해야한다는 것
- 참고자료 : 모델 예측값 보정하기
- 같은 제약 조건에 따라 입력 데이터에 대한 가중치가 있는 최소 제곱합을 계산하는 isotonic regression를 사용하여 이러한 매핑을 찾을 수 있습니다
- 이러한 조각별 선형 접근법은 위의 합리적인 기준 방법과 비교하여 범위의 상한 및 하한 모두에서 예측에 대한 편향을 크게 줄였습니다.
- 추가적인 강력한 가정없이 시스템의 고유한 피드백 루프가 보정의 영향에 대한 이론적 인 보증을 제공 할 수 없게 한다는 점은 주목할 가치가 있음
8. AUTOMATED FEATURE MANAGEMENT
- 확장 가능한 기계학습의 중요한 측면은 기계학습 시스템을 구성하는 모든 구성, 개발자, 코드 및 컴퓨팅 자원을 포함하여 설치 규모를 관리하는 것
- 수십 개의 도메인 관련 문제를 모델링 하는 여러 팀으로 구성된 설치는 약간의 오버 헤드가 필요합니다. 특히 흥미로운 사례는 기계학습을 위한 기능 공간의 관리라고 생각
- 우리는 각 신호 (e.g., ‘words in the advertisement’, ‘country of origin’, etc.) 를 학습을 위한 실제 값 집합으로 변환 할 수있는 상황별 및 의미론적 신호의 집합으로 특징 공간을 특성화 할 수 있음
- 많은 설치에서 개발자가 신호 개발에 비동기적으로 작업 할 수 있습니다. 신호에는 구성 변경, 개선 및 대체 구현에 해당하는 여러 버전이 있을 수 있습니다.
- 직접 개발하지 않는 신호. 신호는 다양한 별개의 학습 플랫폼에서 소비 될 수 있으며 다양한 학습 문제 (예 : 검색 예측 vs. 광고 광고 CTR)에 적용될 수 있습니다.
- To handle the combinatorial growth of use cases 수천 개의 활성 모델에서 수천 개의 입력 신호를 관리하기 위한 메타 데이터 색인을 배포
- 인덱싱 된 신호는 다양한 관심사에 대해 수동 또는 자동으로 모두 주석 처리됩니다.
- 폐지, 플랫폼 별 가용성 및 도메인 별 적용 가능성이 포함됨, 새롭고 활동적인 모델에 의해 소비 된 신호는 automatic system of alerts에 의해 검사됩니다. 서로 다른 학습 플랫폼은 신호 소비를 중앙 인덱스에 보고하기 위한 공통 인터페이스를 공유
- 신호가 더 이상 사용되지 않는 경우 (예 : 최신 버전을 사용할 수 있게 된 경우) 신호의 모든 소비자를 신속하게 식별하고 교체 노력을 추적 할 수 있습니다. 신호의 향상된 버전을 사용할 수있게되면 소비자는 새 버전을 실험하도록 경고 할 수 있습니다.
- 새로운 신호는 자동 테스트 및 포함을 위한 허용 목록에 의해 검증 될 수 있습니다. 화이트리스트는 생산 시스템의 정확성을 보장하고 자동화 된 기능 선택을 사용하여 학습 시스템에 사용할 수 있습니다.
- 더 이상 소비되지 않는 오래된 신호는 코드 정리 및 관련 데이터의 삭제를 위해 자동으로 지정됩니다. 효율적인 자동 신호 소비 관리로 처음으로 더 많은 학습을 올바르게 수행 할 수 있습니다.
- 이로 인해 낭비되고 중복되는 엔지니어링 노력이 줄어들고 많은 엔지니어링 시간이 절약됩니다.
- 학습 알고리즘을 실행하기 전에 구성의 정확성을 검증하면 사용할 수 없는 모델이 발생할 수 있는 많은 경우가 없어짐
9. UNSUCCESSFUL EXPERIMENTS
- 마지막 섹션에서는 몇 가지 접근 방향에 대해 간략하게 보고, 다음의 방법들은 (놀랍게도) 모델에서 상당한 이익을 가져 오지 못했습니다.
- Aggressive Feature Hashing
- 대규모 학습의 RAM 비용을 줄이기 위해 Feature Hashing을 사용합니다.
- Feature Hashing 이란
- 빠르고, space 효율적인 feature 를 vetorize 하는 방법이다. 즉, 임의의 feature 들을 vector 안의 index 로 바꿔주는 작업이다.
- hash function 를 feature 들에 적용한다. 그리고 그들의 hash 값들이 바로 index 로 이용된다. (중간에 hash 와 array 의 index 를 다시 mapping 하는 부분을 두지 않는다.)
- 비슷하게, Chapelle은 디스플레이 광고 데이터 모델링을 위해 2^24 개의 결과 특성을 가진 해싱 트릭을 사용하여 보고했다.
- 접근 방법을 테스트 했지만 관찰 할 수 있는 손실 없이는 수십억 개 미만의 기능을 예측할 수 없음을 발견했습니다.
- 이것은 우리에게 큰 비용 절감 효과를 주지 못했고, 대신 해석 가능한 (해쉬가없는) 특징 벡터를 유지하려고 했습니다.
- Dropout
- 최근의 연구는 훈련, 특히 deep belief network 공동체에서의 무작위적인 “탈락”이라는 새로운 기술에 관심을 두었다.
- 주요 아이디어는 임의로 확률 p로 입력 예제 벡터에서 피쳐를 무작위로 제거하고 테스트 시간에 결과 웨이트 벡터를 (1 - p) 배로 스케일링하여 보상합니다. 이것은 가능한 기능 하위 집합에 대한 포괄을 에뮬레이트하는 정규화의 한 형태로 간주됩니다.
- 우리는 0.1에서 0.5까지의 다양한 범위의 탈락율을 실험했으며, 각각은 데이터에 대한 통과 횟수를 변경하는 것을 포함하여 학습 속도 설정을위한 그리드 검색을 수반합니다.
- 모든 경우에 우리는 중도 이탈 훈련이 예측 정확도 측정 기준이나 일반화 능력에 도움이 되지 않으며 대개는 손해를 초래한다는 것을 발견했습니다.
- 이러한 부정적인 결과와 vision 분야의 유망한 결과 사이의 차이점이 특징 분포의 차이에 있다고 믿습니다.
- vision 작업에서 입력 기능은 일반적으로 밀도가 높지만 작업 입력 기능은 희소하고 레이블에는 소음이 있습니다. 조밀한 설정에서 드롭 아웃은 강하게 상관 된 피쳐와 효과를 분리하여 더 강력한 분류기를 만듭니다.
- 그러나 우리의 sparse 데이터의 dropout을 추가하는 시끄러운 설정은 단순히 학습에 사용할 수있는 데이터의 양을 줄이는 것처럼 보입니다.
- Feature Bagging
- K 모델이 특징 공간의 k 개의 겹쳐진 부분 집합에 대해 독립적으로 학습되는 특징 배깅 (bagging)이 연구되었다. 모델의 출력은 최종 예측을 위해 평균화됩니다.
- 이 접근법은 데이터마이닝 공동체에서 광범위하게 사용되어 왔으며 특히 결정 트리의 앙상블과 함께 사용되어 바이어스 - 분산 트레이드 오프를 관리하는 잠재적인 유용한 방법을 제공한다.
- 그러나 feature bagging는 실제로 bagging scheme에 따라 AucLoss가 0.1 % ~ 0.6 % 정도 예측 품질을 약간 감소시키는 것을 발견했습니다.
- Feature Vector Normalization
- 벡터에서 크기의 분산을 줄이기 위한 목적으로 다양한 규범으로 몇 가지 표준화를 탐구했습니다.
- 조그마한 정확도 향상을 보여주는 초기 결과에도 불구하고 전반적으로 긍정적 메트릭으로 변환 할 수 없었습니다. ( 좌표에 의한 학습 속도와 정규화 와의 상호 작용 때문에 문제가 있었음 )
그외 참고자료 (+ 코드)
코드 보기(클릭)
library(reticulate)
use_python("/usr/bin/python3")
getwd()
kaggle <- import("kaggle")
#search competitions & files
kaggle$api$competitions_list(search = 'outbrain')
kaggle$api$competitions_data_list_files('outbrain-click-prediction')
#download files
kaggle$api$competition_download_files(competition = 'outbrain-click-prediction', path = '/home/syleeie/workspace/07_kaggle/outbrain/data')
## 데이터 전처리
library(data.table)
library(methods)
library(Matrix)
# like this sugar
library(magrittr)
fread_zip = function( file , ...) {
fn = basename(file)
# cut ".zip" suffix using substr
path = paste("unzip -p", file, substr(x = fn, 1, length(fn) - 4))
fread(path, ...)
}
promo = fread_zip("./data/promoted_content.csv.zip")
dim(promo)
head(promo)
setnames(promo, 'document_id', 'promo_document_id')
saveRDS(promo, "./data/promo.rds", compress = FALSE)
clicks_train = fread_zip("./data/clicks_train.csv.zip")
saveRDS(clicks_train, "./data/clicks_train.rds", compress = FALSE)
events = fread_zip("./data/events.csv.zip")
# several values in "platform" column has som bad values, so we need to remove these rows or convert to some value
events[ , platform := as.integer(platform)]
# I chose to convert them to most common value
events[is.na(platform), platform := 1L]
H_SIZE = 2**28
H_SIZE
events[, uuid := text2vec:::hasher(uuid, H_SIZE)]
geo3 = strsplit(events$geo_location, ">", T) %>% lapply(function(x) x[1:3]) %>% simplify2array(higher = FALSE)
events[, geo_location := text2vec:::hasher(geo_location, H_SIZE)]
events[, country := text2vec:::hasher(geo3[1, ], H_SIZE)]
events[, state := text2vec:::hasher(geo3[2, ], H_SIZE)]
events[, dma := text2vec:::hasher(geo3[3, ], H_SIZE)]
rm(geo3)
events[, train := display_id %in% unique(clicks_train$display_id)]
events[, day := as.integer((timestamp / 1000) / 60 / 60 / 24) ]
saveRDS(events, './data/events.rds', compress = FALSE)
train_test_distr = events[, .N, keyby = .(day, train)]
ggplot(train_test_distr) + geom_bar(aes(x = day, y = N, fill = train), stat = 'identity')
train_test_distr[, N_share := N / sum(N), keyby = .(day)]
train_test_distr
ggplot(train_test_distr) +
geom_bar(aes(x = day, y = N_share, fill = train), stat = 'identity') +
scale_y_continuous(breaks=seq(0, 1, 0.05))
rm(train_test_distr)
#devtools::install_github("dselivanov/text2vec")
#devtools::install_github("dselivanov/FTRL")
set.seed(1)
events[, cv := TRUE]
# leave 11-12 days for validation as well as 15% of events in days 1-10
events[day <= 10, cv := sample(c(FALSE, TRUE), .N, prob = c(0.85, 0.15), replace = TRUE), by = day]
# sort by uuid - not imoprtant at this point. Why we are doing this will be explained below.
setkey(events, uuid)
# save events for future usage
#saveRDS(events, "~/projects/kaggle/outbrain/data/events2.rds", compress = FALSE)
# also for now let's remove test events, since we will work with local cross validation data
events = events[train == TRUE]
tables()
head(events)
N_PART = 50
data_sample = events[uuid %% N_PART == 0]
# join with clicks_train to get information about clicks and shown ads
data_sample = clicks_train[data_sample, on = .(display_id = display_id)]
data_sample = promo[data_sample, on = .(ad_id = ad_id)]
object.size(data_sample) / 1e6
head(data_sample)
dim(data_sample)
create_feature_matrix = function(dt, features, h_space_size) {
# 0-based indices
row_index = rep(0L:(nrow(dt) - 1L), length(features))
# note that here we adding `text2vec:::hasher(feature, h_space_size)` - hash offset for this feature
# this reduces number of collisons because. If we won't apply such scheme - identical values of
# different features will be hashed to same value
col_index = Map(function(feature) {
index = (text2vec:::hasher(feature, h_space_size) + dt[[feature]]) %% h_space_size
as.integer(index)
}, features) %>%
unlist(recursive = FALSE, use.names = FALSE)
m = sparseMatrix(i = row_index, j = col_index, x = 1,
dims = c(nrow(dt), h_space_size),
index1 = FALSE, giveCsparse = FALSE, check = F)
m
}
> str(unique(events$uuid))
int [1:14412805] 13 18 24 38 69 73 88 109 123 137 ...
> str(unique(events$geo_location))
int [1:2919] 27275434 58786477 62737713 174182756 75244144 127080681 149277295 64787572 210546949 163247150 ...
> str(unique(events$country))
int [1:230] 122884069 230679753 137928186 127053501 14388093 223535975 36432902 206438380 201240644 32076222 ...
> str(unique(events$state))
int [1:400] 120214145 125162122 262348480 39403474 192586294 137928186 90682557 116016836 110325263 207535342 ...
> str(unique(events$dma))
int [1:212] 134038534 182729554 263053436 246983977 156881311 63996322 50194147 69171333 150360461 86078534 ...
> str(unique(data_sample$ad_id))
int [1:114506] 37900 165329 177591 203377 225611 287583 329867 474291 45192 144740 ...
> dim(data_sample)
[1] 1743567 17
> dim(dt)
[1] 1270642 17
> dim(X_train)
[1] 1270642 16777216
> length(y_train)
[1] 1270642
> summary(X_cv)
472925 x 16777216 sparse Matrix of class "dgRMatrix", with 14187743 entries
i j x
1 1 511446 1
2 1 1416811 1
3 1 1463189 1
4 1 2128721 1
5 1 2225891 1
6 1 2308204 1
7 1 2446642 1
8 1 3407622 1
9 1 3943570 1
(중간 생략)
327 11 13503474 1
328 11 14076254 1
329 11 14878194 1
330 11 15073455 1
331 12 1698778 1
332 12 2129158 1
333 12 2226659 1
[ reached getOption("max.print") -- omitted 14187410 rows ]
> str(X_train)
Formal class 'dgRMatrix' [package "Matrix"] with 6 slots
..@ p : int [1:1270643] 0 30 60 90 120 150 180 210 240 270 ...
..@ j : int [1:38119233] 494078 575104 1704621 1750753 2002139 2128476 2446396 3944857 4201573 4948588 ...
..@ Dim : int [1:2] 1270642 16777216
..@ Dimnames:List of 2
.. ..$ : NULL
.. ..$ : NULL
..@ x : num [1:38119233] 1 1 1 1 1 1 1 1 1 1 ...
..@ factors : list()
y_train = as.numeric(data_sample[cv == FALSE, clicked])
data_sample_cv = data_sample[cv == TRUE]
X_cv = create_feature_matrix(data_sample[cv == TRUE], feature_names, h_space_size)
y_cv = as.numeric(data_sample[cv == TRUE, clicked])
glmnet_model = glmnet::glmnet(x = X_train, y = y_train, family = 'binomial',
thresh = 1e-3, nlambda = 10, type.logistic = "modified.Newton")
> summary(glmnet_model$beta)
16777216 x 10 sparse Matrix of class "dgCMatrix", with 162125 entries
i j x
1 2445833 2 -1.720603e-01
2 2446351 2 -9.825541e-02
3 2446549 2 -1.683684e-01
4 2447218 2 -2.112142e-04
5 2447430 2 -2.628027e-01
6 2447481 2 -4.757428e-02
7 2447693 2 -2.441406e-02
8 2447699 2 -2.093941e-01
9 2447931 2 -1.789522e-01
10 2449037 2 4.472599e-02
(중간 생략)
330 7819349 4 4.015979e-02
331 7830515 4 1.780055e-01
332 7832180 4 1.149014e-01
333 7871500 4 -1.259998e-01
[ reached getOption("max.print") -- omitted 161792 rows ]
> dim(summary(glmnet_model$beta))
[1] 162125 3
library(Matrix)
library(methods)
library(FTRL)
# First of all need to convert matrix to row-sparse matrix
X_train_csr = as(X_train, "RsparseMatrix")
X_cv_csr = as(X_cv, "RsparseMatrix")
# set up model
ftrl = FTRL$new(alpha = 0.01, beta = 0.1, lambda = 20, l1_ratio = 1, dropout = 0)
ftrl
# 1 thread
system.time(ftrl$partial_fit(X = X_train_csr, y = y_train, nthread = 1))
# 4 threads
system.time(ftrl$partial_fit(X = X_train_csr, y = y_train, nthread = 4))
# 4 threads + 4 hyperthreads
system.time(ftrl$partial_fit(X = X_train_csr, y = y_train, nthread = 8))
h_space_size = 2**24
feature_names = c("ad_id", "promo_document_id", "campaign_id", "advertiser_id", "document_id",
"platform", "geo_location", "country", "state", "dma")
X_cv = as(X_cv, "RsparseMatrix")
# regularization parameter lambda and learning rate alpha are important hyperparameters
# should be defined after via cross-validation and grid-search
ftrl = FTRL$new(alpha = 0.05, beta = 0.5, lambda = 1, l1_ratio = 1, dropout = 0)
# iterate through all examples
i = 1
for(i in 0:(N_PART - 1)) {
dt = events[uuid %% N_PART == i & cv == FALSE]
dt = clicks_train[dt, on = .(display_id = display_id)]
dt = promo[dt, on = .(ad_id = ad_id)]
# create model matrix for a given chunk and convert it to CSR format
X_train = create_feature_matrix(dt, feature_names, h_space_size) %>%
as("RsparseMatrix")
y_train = as.numeric(dt[, clicked])
# update model
ftrl$partial_fit(X = X_train, y = y_train, nthread = 8)
# check target metric. Alternatively can check map@12
# but in our case it was 100% correlated with AUC
if(i %% 5 == 0) {
train_auc = glmnet::auc(y_train, ftrl$predict(X_train))
p = ftrl$predict(X_cv)
dt_cv = data_sample_cv[, .(display_id, clicked, p = -p)]
# res[, p := -(p)]
setkey(dt_cv, display_id, p)
mean_map12 = dt_cv[ , .(map_12 = 1 / .Internal(which(clicked == 1))), by = display_id][['map_12']] %>%
mean %>% round(5)
cv_auc = glmnet::auc(y_cv, p)
message(sprintf("batch %d train_auc = %f, cv_auc = %f, map@12 = %f",i, train_auc, cv_auc, mean_map12))
}
}
batch 0 train_auc = 0.724768, cv_auc = 0.704696, map@12 = 0.630780
batch 5 train_auc = 0.731685, cv_auc = 0.715615, map@12 = 0.638130
batch 10 train_auc = 0.734354, cv_auc = 0.718261, map@12 = 0.640280
batch 15 train_auc = 0.735428, cv_auc = 0.719932, map@12 = 0.640360
batch 20 train_auc = 0.735220, cv_auc = 0.721028, map@12 = 0.641320
batch 25 train_auc = 0.736259, cv_auc = 0.721872, map@12 = 0.641830
batch 30 train_auc = 0.736308, cv_auc = 0.722242, map@12 = 0.641690
batch 35 train_auc = 0.737115, cv_auc = 0.722791, map@12 = 0.642550
batch 40 train_auc = 0.737084, cv_auc = 0.723242, map@12 = 0.642910
batch 45 train_auc = 0.737795, cv_auc = 0.723460, map@12 = 0.643150
ave_rds_compressed = function(x, file, compr_lvl = 1) {
con = gzfile(file, open = "wb", compression = compr_lvl)
saveRDS(x, file = con)
close.connection(con)
}
# now features will be a list of sets of features
# single values will correspont to single original features,
# while sets of features will correspond to interactions
# for example `features = list("platform", c("country", "campaign_id") )`
create_feature_matrix = function(dt, features, h_space_size) {
# 0-based indices
row_index = rep(0L:(nrow(dt) - 1L), length(features))
# note that here we adding `text2vec:::hasher(feature, h_space_size)` - hash offset for this feature
# this reduces number of collisons because. If we won't apply such scheme - identical values of
# different features will be hashed to same value
col_index = Map(function(fnames) {
# here we calculate offset for each feature
# hash name of feature to reduce number of collisions
# because for eample if we won't hash value of platform=1 will be hashed to the same as advertiser_id=1
offset = text2vec:::hasher(paste(fnames, collapse = "_"), h_space_size)
# calculate index = offest + sum(feature values)
index = (offset + Reduce(`+`, dt[, fnames, with = FALSE])) %% h_space_size
as.integer(index)
}, features) %>%
unlist(recursive = FALSE, use.names = FALSE)
m = sparseMatrix(i = row_index, j = col_index, x = 1,
dims = c(nrow(dt), h_space_size),
index1 = FALSE, giveCsparse = FALSE, check = F)
m
}
interactions = c('promo_document_id', 'campaign_id', 'advertiser_id', 'document_id', 'platform', 'country', 'state') %>%
combn(2, simplify = F)
single_features = c('ad_id', 'campaign_id', 'advertiser_id', 'document_id', 'platform', 'geo_location', 'country', 'state', 'dma')
features_with_interactions = c(single_features, interactions)
h_space_size = 2**24
data_sample_cv = data_sample[cv == TRUE]
X_cv = create_feature_matrix(data_sample[cv == TRUE], features_with_interactions, h_space_size) %>%
as("RsparseMatrix")
y_cv = as.numeric(data_sample[cv == TRUE, clicked])
save_rds_compressed(list(x = X_cv, y = y_cv,
dt = data_sample_cv[, .(display_id, uuid, ad_id, promo_document_id, campaign_id, advertiser_id)]),
file = "./data/dt_cv_0.rds")
# will save mini-batches here
events_matrix_dir = "./data/events_matrix/"
dir.create(events_matrix_dir)
# iterate through all examples
for(i in 0:(N_PART - 1)) {
dt = events[uuid %% N_PART == 0 & cv == FALSE]
dt = clicks_train[dt, on = .(display_id = display_id)]
dt = promo[dt, on = .(ad_id = ad_id)]
setkey(dt, display_id, ad_id)
# create model matrix for a given chunk and convert it to CSR format
X_train = create_feature_matrix(dt, features_with_interactions, h_space_size) %>%
as("RsparseMatrix")
y_train = as.numeric(dt[, clicked])
# save file for further faster model tuning - we won't need to recalculate model matrix each time
# dt will be used in further steps to join with page views.
save_rds_compressed(list(x = X_train, y = y_train,
dt = dt[, .(uuid, ad_id, promo_document_id, campaign_id, advertiser_id)]),
file = sprintf("%s/%d.rds", events_matrix_dir, i))
message(sprintf("%s batch %d", Sys.time(), i))
}
# regularization parameter lambda and learning rate alpha are important hyperparameters
# should be defined after via cross-validation and grid-search
ftrl = FTRL$new(alpha = 0.05, beta = 0.5, lambda = 1, l1_ratio = 1, dropout = 0)
for(i in 0:(N_PART - 1)) {
data = readRDS(sprintf("%s/%d.rds", events_matrix_dir, i))
# update model
ftrl$partial_fit(X = data$x, y = data$y, nthread = 8)
# check target metric. Alternatively can check map@12
# but in our case it was 100% correlated with AUC
if(i %% 5 == 0) {
train_auc = glmnet::auc(y_train, ftrl$predict(X_train))
p = ftrl$predict(X_cv)
dt_cv = data_sample_cv[, .(display_id, clicked, p = -p)]
setkey(dt_cv, display_id, p)
mean_map12 = dt_cv[ , .(map_12 = 1 / .Internal(which(clicked == 1))), by = display_id][['map_12']] %>%
mean %>% round(5)
cv_auc = glmnet::auc(y_cv, p)
message(sprintf("%s batch %d train_auc = %f, cv_auc = %f, map@12 = %f", Sys.time(), i, train_auc, cv_auc, mean_map12))
}
}
2018-11-07 00:59:50 batch 0 train_auc = 0.747697, cv_auc = 0.710609, map@12 = 0.634620
2018-11-07 01:00:06 batch 5 train_auc = 0.871129, cv_auc = 0.709234, map@12 = 0.632100
2018-11-07 01:00:22 batch 10 train_auc = 0.918955, cv_auc = 0.703892, map@12 = 0.627140
2018-11-07 01:00:38 batch 15 train_auc = 0.942870, cv_auc = 0.699321, map@12 = 0.623570
2018-11-07 01:00:54 batch 20 train_auc = 0.956772, cv_auc = 0.695499, map@12 = 0.620560
2018-11-07 01:01:10 batch 25 train_auc = 0.965641, cv_auc = 0.692253, map@12 = 0.618220
2018-11-07 01:01:25 batch 30 train_auc = 0.971660, cv_auc = 0.689471, map@12 = 0.616410
2018-11-07 01:01:42 batch 35 train_auc = 0.975947, cv_auc = 0.687035, map@12 = 0.614580
2018-11-07 01:01:58 batch 40 train_auc = 0.979120, cv_auc = 0.684882, map@12 = 0.613230
2018-11-07 01:02:14 batch 45 train_auc = 0.981535, cv_auc = 0.682970, map@12 = 0.611870
- FTRL은 Optimizer이기 때문에 tflearn(TFLearn: Deep learning library featuring a higher-level API for TensorFlow)에서도 제공
- tflearn FTRL optimizer 설명 (http://tflearn.org/optimizers/#ftrl-proximal)
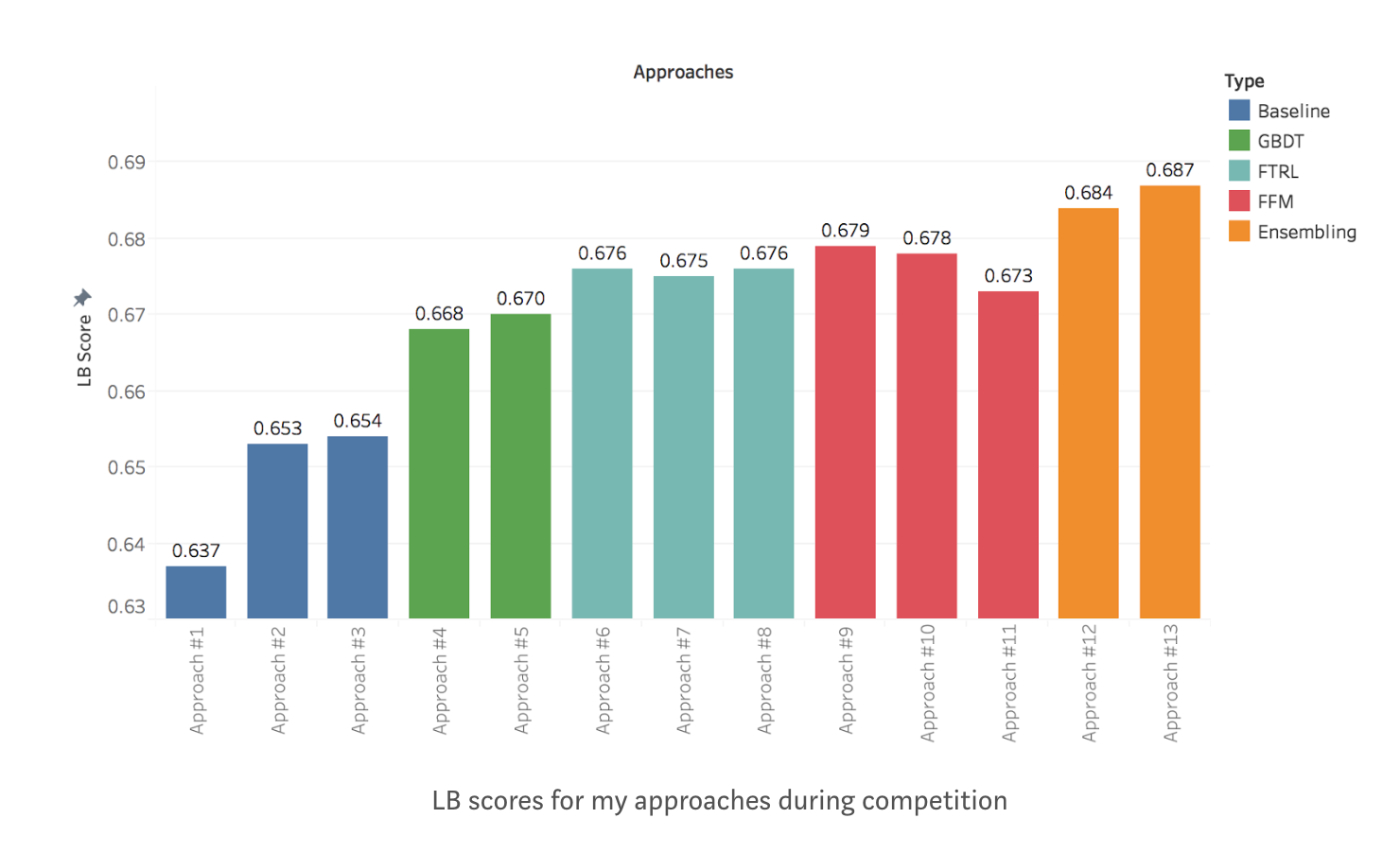
- 캐글 데이터 문제(Outbrain Click Prediction) 적용하기
- FFM
- 행렬 인수분해(matrix factorization)과 SVM(support vector machine)의 개념을 결합한 인수분해기계(factorization machines)였는데, 향후 개별 피처(feature)들의 메타정보(field)를 모델에 반영해서 FFM(Fieldaware factorization machine)으로 발전했다.
- FTRL을 SOTA라고 설명했지만, pCTR 예측에서 FFM이 로직스틱 모델보다 3~4% 이상 정확도가 높다고 보고됐다. 하지만 로지스틱 모델과 달리 FFM은 가중치를 잠재 벡터(latent vector)화했기 때문에 연산량과 메모리 사용량이 더 높은 단점




댓글남기기